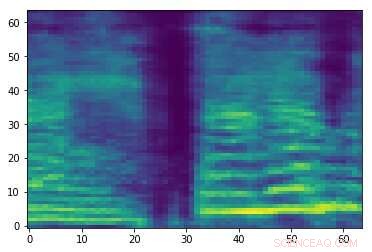
Spettrogramma di un segnale audio casuale. Attestazione:Esmailpour, Cardinale e Lemeiras Koerich.
Gli attacchi audio contraddittori sono piccole perturbazioni che non sono percepibili dagli esseri umani e vengono intenzionalmente aggiunte ai segnali audio per compromettere le prestazioni dei modelli di machine learning (ML). Questi attacchi sollevano serie preoccupazioni sulla sicurezza dei modelli ML, in quanto possono indurli a commettere errori e alla fine generare previsioni errate.
Ricercatori dell'École de Technologie Supérieure, parte dell'Università del Quebec in Canada ha recentemente sviluppato un nuovo approccio che potrebbe aiutare a proteggere gli strumenti di classificazione audio contro gli attacchi avversari. Nella loro carta, pre-pubblicato su arXiv, esaminano alcuni degli attacchi avversari più potenti esistenti e il loro impatto sulle prestazioni dei modelli ML comuni, quindi proporre un approccio che possa contrastare questi attacchi.
"Al momento, ci sono molti classificatori forti e veloci (in fase di esecuzione) in termini di accuratezza, vale a dire classificatori di deep learning (ad es. reti neurali convoluzionali), che può persino superare il livello umano dei media (ad es. Immagine, video, animazione, testo, ecc.) riconoscimento e regressione, "Mohammad Esmaeilpour, uno dei ricercatori che ha condotto lo studio, ha detto a TechXplore. "Il tallone d'Achille di questi algoritmi avanzati è la loro vulnerabilità agli input che contengono perturbazioni accuratamente realizzate, noti come attacchi avversari".
Gli attacchi contraddittori funzionano producendo campioni che assomigliano molto a campioni di addestramento legittimi, ma ciò in realtà porta un modello o modelli ML a generare etichette errate con alti livelli di confidenza. Nella ricerca ML, se ci sono dati sufficienti per addestrare un classificatore, la sfida principale non è più migliorare la sua precisione di riconoscimento, ma garantendo la sua resilienza contro gli attacchi avversari.
"Gli attacchi avversari sono minacce attive per tutti gli algoritmi basati sui dati, anche quelli formati su piccoli set di dati, " Ha detto Esmaeilpour. "Questo ha suscitato il nostro interesse a studiare la minaccia di attacchi avversari per applicazioni di riconoscimento vocale e audio, poiché tutti gli smartphone sono ora dotati di un assistente vocale virtuale come Siri, Assistente Google e Cortana."
Nel loro studio, Esmaeilpour e i suoi colleghi hanno condotto esperimenti che coinvolgono set di dati audio ambientali, piuttosto che set di dati vocali. Ciò nonostante, in futuro il loro approccio potrebbe essere potenzialmente esteso anche al riconoscimento vocale, che aiuterebbe a proteggere gli assistenti vocali dagli attacchi contraddittori.
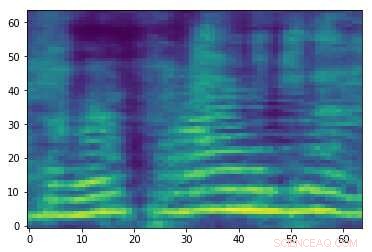
Spettrogramma contraddittorio predisposto associato al segnale audio nella prima immagine. Sebbene le due immagini siano simili, hanno etichette diverse, suggerendo che è in corso un attacco. Attestazione:Esmailpour, Cardinale e Lemeiras Koerich.
"Il nostro obiettivo principale in questo documento era quello di studiare la minaccia di attacchi contraddittori per i classificatori audio sia convenzionali che di deep learning e idealmente proporre un algoritmo più affidabile in termini di resilienza contro alcuni attacchi comuni come base per una classificazione audio davvero robusta, " Ha spiegato Esmaeilpour. "Volevamo creare un giusto equilibrio per i classificatori nell'accuratezza del riconoscimento, complessità computazionale, e robustezza contro gli attacchi avversari."
In genere, i classificatori più robusti contro gli attacchi avversari raggiungono una minore precisione di riconoscimento, e viceversa. Nel loro studio, i ricercatori si sono concentrati sulla riqualificazione del contraddittorio, una delle più valide tecniche di difesa esistenti che non offuscano le informazioni sui gradienti. Nonostante i suoi benefici, questa particolare strategia di difesa è costosa (come gli attacchi forti sono costosi, la riqualificazione del contraddittorio che utilizza questi attacchi sarà più costosa) e può influire negativamente sulle prestazioni di riconoscimento di un classificatore.
"Il caso ideale per noi sarebbe proporre un classificatore audio privo di offuscamento del gradiente e contraddittorio che apprende intrinsecamente "caratteristiche robuste", " Esmaeilpour ha detto. "Il nostro scenario di classificazione include diversi passaggi, principalmente miglioramento dello spettrogramma (rappresentazione 2D per segnali audio), riduzione della dimensionalità mediante una tecnica di decomposizione algebrica, e smoothing utilizzando un autoencoder di de-noising convoluzionale, dove gli ultimi due passaggi (accatastati insieme) hanno mostrato impatti positivi sulla rimozione di piccole potenziali perturbazioni contraddittorie sconosciute."
Dopo aver esaminato alcuni dei più potenti attacchi avversari in circolazione e i loro effetti sulle prestazioni dei modelli ML, i ricercatori hanno estratto le caratteristiche dagli spettrogrammi elaborati dai modelli, li ha organizzati in un codebook e ha addestrato un algoritmo Support Vector Machine (SVM) su questo codebook. Nella loro pipeline di formazione, non hanno implementato alcuna tecnica di rilevamento di attacchi avversari o algoritmi di difesa proattivi o reattivi.
"Il nostro obiettivo principale era quello di "apprendere vettori di funzionalità robusti" senza alcun sovraccarico di pre o post-elaborazione per rilevare potenziali campioni contraddittori, " Ha spiegato Esmaeilpour. "I nostri risultati mostrano che il nostro classificatore proposto supera lo stato dell'arte del deep learning e degli algoritmi convenzionali contro cinque tipi di forti attacchi avversari per alcuni pratici set di dati audio ambientali".
Esmaeilpour e i suoi colleghi hanno dimostrato statisticamente la vulnerabilità di entrambi i classificatori convenzionali (cioè i classificatori che imparano dallo spazio delle funzionalità) e gli algoritmi di deep learning (cioè algoritmi che imparano dai dati grezzi) contro gli attacchi avversari. Secondo i ricercatori, attualmente non esiste un algoritmo affidabile basato sui dati per la classificazione dell'audio che sia anche robusto contro gli attacchi avversari. Tra i modelli esistenti, gli approcci basati sul deep learning sembrano essere i meno sicuri contro questi attacchi, anche se in genere raggiungono la massima precisione di riconoscimento.
"Lo scenario di classificazione che abbiamo proposto nel nostro articolo utilizza un SVM con kernel polinomiale come classificatore finale, " ha detto Esmaeilpour. "Tuttavia, l'applicazione di un autoencoder convoluzionale di de-noising in cima alla decomposizione del valore singolare seguita da un clustering non supervisionato di vettori di feature robusti e accelerati estratti potrebbe aiutare ad apprendere più componenti strutturali e probabilmente caratteristiche robuste, che potrebbe consentirci di raggiungere un ragionevole equilibrio tra accuratezza del riconoscimento (paragonabile alle prestazioni allo stato dell'arte) e robustezza contro cinque comuni forti attacchi avversari".
Mentre i risultati raccolti dai ricercatori sono molto promettenti, possono variare in base al set di dati utilizzato o all'applicazione specifica di un classificatore, quindi non sono ancora generalizzabili. Nel futuro, il loro studio potrebbe informare lo sviluppo di altri classificatori che sono meglio equipaggiati contro gli attacchi avversari, senza presentare sostanziali perdite di prestazioni (es. accuratezza del riconoscimento).
"L'apprendimento di funzionalità robuste è un problema aperto e non abbiamo ancora un'idea chiara di come affrontarlo correttamente; è allo studio dal nostro team di ricerca e alcuni risultati verranno rilasciati presto, " disse Esmaeilpour. "Nel frattempo, stiamo lavorando a un nuovo, tecnica di attacco contraddittorio forte e veloce volta a utilizzare questo attacco per addestrare in modo contraddittorio il modello di apprendimento (che ne migliora la robustezza) e anche salvare le prestazioni di riconoscimento del modello prima di addestrarlo."
© 2019 Science X Network