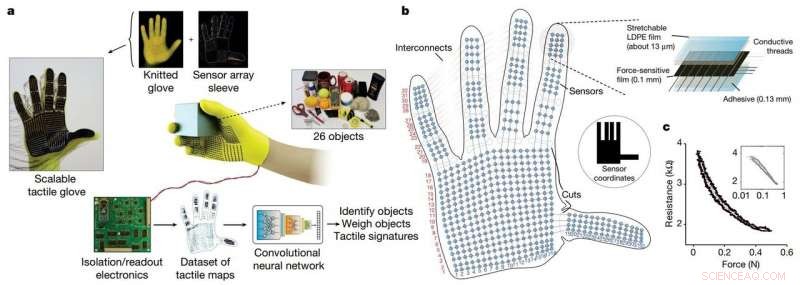
I ricercatori del MIT hanno sviluppato un sistema a basso costo, Guanto dotato di sensori che cattura i segnali di pressione mentre gli esseri umani interagiscono con gli oggetti. Il guanto può essere utilizzato per creare set di dati tattili ad alta risoluzione che i robot possono sfruttare per identificare meglio, pesare, e manipolare gli oggetti. Credito:Massachusetts Institute of Technology
Indossare un guanto dotato di sensori mentre si maneggia una varietà di oggetti, I ricercatori del MIT hanno compilato un enorme set di dati che consente a un sistema di intelligenza artificiale di riconoscere gli oggetti solo attraverso il tocco. Le informazioni potrebbero essere sfruttate per aiutare i robot a identificare e manipolare oggetti, e può aiutare nella progettazione delle protesi.
I ricercatori hanno sviluppato un guanto a maglia a basso costo, chiamato "guanto tattile scalabile" (STAG), dotato di circa 550 minuscoli sensori su quasi tutta la mano. Ciascun sensore cattura i segnali di pressione mentre gli esseri umani interagiscono con gli oggetti in vari modi. Una rete neurale elabora i segnali per "apprendere" un set di dati di modelli di segnali di pressione relativi a oggetti specifici. Quindi, il sistema utilizza quel set di dati per classificare gli oggetti e prevederne il peso sentendosi soli, senza bisogno di input visivi.
In un articolo pubblicato su Natura , i ricercatori descrivono un set di dati che hanno compilato utilizzando STAG per 26 oggetti comuni, tra cui una lattina di soda, forbici, palla da tennis, cucchiaio, penna, e tazza. Utilizzando il set di dati, il sistema ha previsto le identità degli oggetti con una precisione fino al 76%. Il sistema può anche prevedere i pesi corretti della maggior parte degli oggetti entro circa 60 grammi.
Guanti simili basati su sensori utilizzati oggi costano migliaia di dollari e spesso contengono solo circa 50 sensori che catturano meno informazioni. Anche se STAG produce dati ad altissima risoluzione, è realizzato con materiali disponibili in commercio per un totale di circa $ 10.
Il sistema di rilevamento tattile potrebbe essere utilizzato in combinazione con la visione artificiale tradizionale e i set di dati basati su immagini per fornire ai robot una comprensione più umana dell'interazione con gli oggetti.
"Gli esseri umani possono identificare e maneggiare bene gli oggetti perché abbiamo un feedback tattile. Quando tocchiamo gli oggetti, ci sentiamo intorno e ci rendiamo conto di cosa sono. I robot non hanno un feedback così ricco, " dice Subramanian Sundaram Ph.D. '18, un ex studente laureato presso il Laboratorio di Informatica e Intelligenza Artificiale (CSAIL). "Abbiamo sempre voluto che i robot facessero ciò che gli umani possono fare, come lavare i piatti o altre faccende. Se vuoi che i robot facciano queste cose, devono essere in grado di manipolare gli oggetti molto bene."
I ricercatori hanno anche utilizzato il set di dati per misurare la cooperazione tra le regioni della mano durante le interazioni con gli oggetti. Per esempio, quando qualcuno usa l'articolazione media del dito indice, usano raramente il pollice. Ma le punte dell'indice e del medio corrispondono sempre all'uso del pollice. "Mostriamo in modo quantificabile, per la prima volta, Quello, se sto usando una parte della mia mano, quanto è probabile che io usi un'altra parte della mia mano, " lui dice.
I produttori di protesi possono potenzialmente utilizzare le informazioni per, dire, scegli i punti ottimali per posizionare i sensori di pressione e aiuta a personalizzare le protesi in base alle attività e agli oggetti con cui le persone interagiscono regolarmente.
Ad unirsi a Sundaram sul giornale ci sono:i postdoc CSAIL Petr Kellnhofer e Jun-Yan Zhu; studente laureato CSAIL Yunzhu Li; Antonio Toralba, un professore in EECS e direttore del MIT-IBM Watson AI Lab; e Wojciech Matusik, professore associato in ingegneria elettrica e informatica e capo del gruppo di fabbricazione computazionale.
Lo STAG come piattaforma per imparare dalla presa umana. Credito: Natura (2019). DOI:10.1038/s41586-019-1234-z
STAG è laminato con un polimero elettricamente conduttivo che cambia la resistenza alla pressione applicata. I ricercatori hanno cucito fili conduttivi attraverso i fori nel film polimerico conduttivo, dalla punta delle dita alla base del palmo. I fili si sovrappongono in un modo che li trasforma in sensori di pressione. Quando qualcuno che indossa il guanto sente, ascensori, tiene, e lascia cadere un oggetto, i sensori registrano la pressione in ogni punto.
I fili si collegano dal guanto a un circuito esterno che traduce i dati di pressione in "mappe tattili, " che sono essenzialmente brevi video di punti che crescono e si restringono su una grafica di una mano. I punti rappresentano la posizione dei punti di pressione, e la loro dimensione rappresenta la forza:più grande è il punto, maggiore è la pressione.
Da quelle mappe, i ricercatori hanno compilato un set di dati di circa 135, 000 fotogrammi video da interazioni con 26 oggetti. Questi frame possono essere utilizzati da una rete neurale per prevedere l'identità e il peso degli oggetti, e fornire intuizioni sulla presa umana.
Per identificare gli oggetti, i ricercatori hanno progettato una rete neurale convoluzionale (CNN), che di solito viene utilizzato per classificare le immagini, associare modelli di pressione specifici a oggetti specifici. Ma il trucco era scegliere cornici da diversi tipi di presa per ottenere un'immagine completa dell'oggetto.
L'idea era di imitare il modo in cui gli umani possono tenere un oggetto in diversi modi per riconoscerlo, senza usare la vista. Allo stesso modo, la CNN dei ricercatori sceglie fino a otto fotogrammi semicasuali dal video che rappresentano le prese più dissimili, ad esempio tenendo una tazza dal fondo, superiore, e maneggiare.
Ma la CNN non può semplicemente scegliere fotogrammi casuali tra le migliaia in ogni video, o probabilmente non sceglierà impugnature distinte. Anziché, raggruppa frame simili insieme, risultando in cluster distinti corrispondenti a prese uniche. Quindi, estrae un fotogramma da ciascuno di quei grappoli, assicurandosi di avere un campione rappresentativo. Quindi la CNN utilizza i modelli di contatto appresi durante l'addestramento per prevedere una classificazione degli oggetti dai frame scelti.
"Vogliamo massimizzare la variazione tra i frame per dare il miglior input possibile alla nostra rete, " Kellnhofer dice. "Tutti i frame all'interno di un singolo cluster dovrebbero avere una firma simile che rappresenti i modi simili di afferrare l'oggetto. Il campionamento da più cluster simula un essere umano che cerca in modo interattivo di trovare prese diverse mentre esplora un oggetto".
Per la stima del peso, i ricercatori hanno costruito un set di dati separato di circa 11, 600 fotogrammi da mappe tattili di oggetti raccolti da dita e pollice, tenuto, e caduto. In particolare, la CNN non è stata addestrata su nessun frame su cui è stata testata, il che significa che non poteva imparare ad associare il peso a un oggetto. Nella prova, un singolo frame è stato inserito nella CNN. Essenzialmente, la CNN rileva la pressione intorno alla mano causata dal peso dell'oggetto, e ignora la pressione causata da altri fattori, come il posizionamento della mano per evitare che l'oggetto scivoli. Quindi calcola il peso in base alle pressioni appropriate.
Il sistema potrebbe essere combinato con i sensori già sui giunti dei robot che misurano la coppia e la forza per aiutarli a prevedere meglio il peso dell'oggetto. "Le articolazioni sono importanti per prevedere il peso, ma ci sono anche importanti componenti di peso dai polpastrelli e dal palmo che catturiamo, "Dice Sundaram.
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.