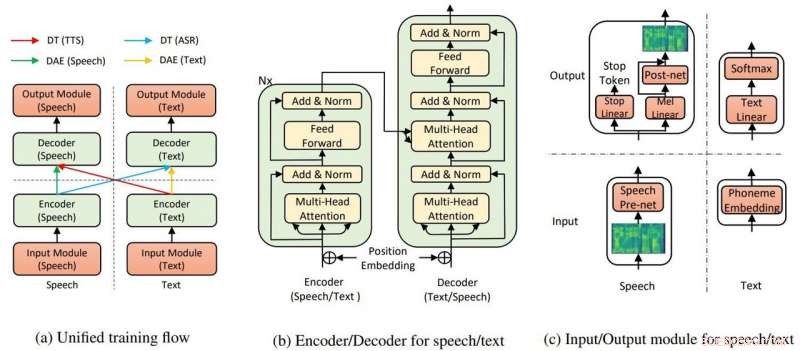
La struttura generale del modello per TTS e ASR. Credito:Yi Ren, Xu Tan et al.
Microsoft Research Asia ha raccolto applausi per aver eseguito la sintesi vocale che richiede poca formazione e mostrando risultati "incredibilmente" realistici.
Kyle Wiggers in VentureBeat detti algoritmi di sintesi vocale non erano nuovi e altri abbastanza capaci ma, ancora, il lavoro di squadra di Microsoft ha ancora un vantaggio.
Abdullah Matloob in Mondo dell'informazione digitale :"La conversione della sintesi vocale sta diventando intelligente con il tempo, ma lo svantaggio è che ci vorrà ancora una quantità eccessiva di tempo e risorse di formazione per costruire un prodotto dal suono naturale."
Alla ricerca di un modo per scrollarsi di dosso il fardello di tempo e risorse di formazione per creare un output dal suono naturale, Microsoft Research e ricercatori cinesi hanno scoperto un altro modo per convertire la sintesi vocale.
Fabienne Lang in Ingegneria interessante :La loro risposta risulta essere una sintesi vocale AI che utilizza 200 campioni vocali (solo 200) per creare un discorso dal suono realistico per abbinare le trascrizioni. Lang ha detto, "Questo significa che vale circa 20 minuti."
Il fatto che il requisito fosse solo 200 clip audio e le relative trascrizioni ha impressionato Wiggers in VentureBeat . Ha anche notato che i ricercatori hanno ideato un sistema di intelligenza artificiale "che sfrutta l'apprendimento non supervisionato, un ramo dell'apprendimento automatico che raccoglie conoscenza da non etichettati, non classificato, e dati di test non classificati."
Il loro articolo è su arXiv. "Sintesi vocale quasi senza supervisione e riconoscimento vocale automatico" è di Yi Ren, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie Yan Liu. Le affiliazioni degli autori sono Zhejiang University, Microsoft Research e Microsoft Search Technology Center (STC) Asia.
Nella loro carta, il team ha affermato che l'IA di TTS utilizza due componenti chiave, un trasformatore e auto-encoder denoising, per far funzionare tutto.
"Attraverso i trasformatori, L'IA di sintesi vocale di Microsoft è stata in grado di riconoscere il parlato o il testo come input o output, " ha detto un articolo in spigoloso di Rechelle Fuertes.
Tyler Lee in Ubergizmo ha fornito una definizione di trasformatore:"I trasformatori... sono reti neurali profonde progettate per emulare i neuroni nel nostro cervello.."
MathWorks aveva una definizione per l'autoencoder. "Un codificatore automatico è un tipo di rete neurale artificiale utilizzata per apprendere dati efficienti (codifiche) in modo non supervisionato. Lo scopo di un codificatore automatico è apprendere una rappresentazione (codifica) per un insieme di dati, il denoising degli autoencoder è in genere un tipo di autoencoder addestrato a ignorare il "rumore" nei campioni di input danneggiati."
I risultati del loro esperimento hanno mostrato che vale la pena inseguire la loro idea? "Il nostro metodo raggiunge il 99,84% in termini di velocità intelligibile a livello di parola e 2,68 MOS per TTS, e 11,7% PER per ASR [riconoscimento vocale automatico] su set di dati LJSpeech, sfruttando solo 200 dati vocali e di testo accoppiati (circa 20 minuti di audio), insieme a dati vocali e di testo extra non accoppiati."
Perché è importante:questo approccio può rendere la sintesi vocale più accessibile, detti rapporti.
"I ricercatori lavorano continuamente per migliorare il sistema, e speriamo che in futuro, ci vorrà ancora meno lavoro per generare un discorso realistico, " ha detto Lang.
Il paper sarà presentato alla International Conference on Machine Learning, a Long Beach in California entro la fine dell'anno, e il team prevede di rilasciare il codice nelle prossime settimane, disse Wiggers.
Nel frattempo, i ricercatori non si stanno ancora allontanando dal loro lavoro nel presentare le trasformazioni con pochi dati accoppiati.
"In questo lavoro, abbiamo proposto il metodo quasi non supervisionato per la sintesi vocale e il riconoscimento vocale automatico, che sfrutta solo pochi dati vocali e di testo accoppiati e dati extra non accoppiati... Per il lavoro futuro, spingeremo verso il limite dell'apprendimento non supervisionato sfruttando puramente dati vocali e testuali spaiati, con l'aiuto di altri metodi di pre-formazione."
© 2019 Scienza X Rete