In questa visualizzazione dei dati, ogni nodo rappresenta un gruppo di pagine di Wikipedia su un argomento relativo agli eventi mondiali del 2015. I petali sono formati raggruppando i nodi di un determinato argomento. Attestazione:Kirell Benzi
I ricercatori dell'EPFL hanno studiato le dinamiche delle strutture di rete utilizzando uno dei siti web più visitati al mondo:Wikipedia. Oltre a una migliore comprensione delle reti online, il loro lavoro porta intuizioni entusiasmanti sul comportamento sociale umano e sulla memoria collettiva.
Hai mai visitato una pagina di Wikipedia per rispondere a una domanda, solo per ritrovarti a fare clic da una pagina all'altra, fino a quando non ti ritrovi su un argomento molto diverso da quello con cui hai iniziato? Se è così, non solo non sei solo, ma è probabile che altre persone abbiano preso lo stesso percorso rotatorio da, dire, "Game of Thrones" a "Dubrovnik" a "attrazione turistica" a "il più grande gomitolo di spago del mondo".
I ricercatori del Signal Processing Laboratory (LTS2) guidati dal professor Pierre Vandergheynst della EPFL School of Engineering (STI) e della School of Computer and Communication Sciences (IC) volevano scoprire come funziona questo processo.
Più specificamente, hanno deciso di studiare la dinamica della struttura di rete utilizzando l'elaborazione del segnale e la teoria della rete, sviluppare un algoritmo per rilevare automaticamente attività insolite in continuo cambiamento, sistemi complessi come Wikipedia.
"Il cervello dell'umanità"
La capacità di rilevare e studiare eventi anomali nelle reti online, ad esempio, un picco improvviso nel numero di visite a una particolare pagina di Wikipedia in un certo periodo di tempo, potrebbe dirci molto sull'interazione umana, comportamento collettivo, memoria e scambio di informazioni, dicono i ricercatori.

Questa visualizzazione dei dati mostra le pagine di Wikipedia sugli attori GoT, personaggi ed episodi. Credito:LTS2/EPFL
"La nostra idea era di immaginare Wikipedia come il cervello dell'umanità, dove le visite alle pagine sono paragonabili ai picchi dell'attività cerebrale, "dice Volodymyr Miz, un ricercatore e Ph.D. studente in LTS2. Miz è l'autore principale di un articolo sul nuovo algoritmo, che è stato recentemente presentato alla Web Conference 2019 di San Francisco, California, NOI..
Co-autore Kirell Benzi, un ex ricercatore di LTS2 e docente di visualizzazione dei dati dell'EPFL che ora lavora come artista di dati, ha aggiunto che ciò che ha reso Wikipedia così attraente come fonte di dati è stata la sua accessibilità e dimensione.
"Wikipedia ha circa 5 miliardi di visite all'anno solo per l'inglese. Con questa tecnica, possiamo identificare gruppi di pagine che appartengono insieme, " Egli ha detto.
Dalla memoria collettiva alle fake news
L'algoritmo dei ricercatori è unico perché non solo può identificare tali eventi anomali, ma forniscono anche informazioni su dove esattamente, come, e perché sono accaduti.
"La differenza fondamentale è che forniamo più contesto grazie alla struttura della rete. Ad esempio, se guardiamo alle pagine di Wikipedia sugli attacchi terroristici di Parigi del 2015, possiamo vedere che la pagina sull'attentato è direttamente collegata alla pagina sulla rivista Charlie Hebdo, e anche a un gruppo di pagine che rappresentano organizzazioni terroristiche, "Spiega Miz.
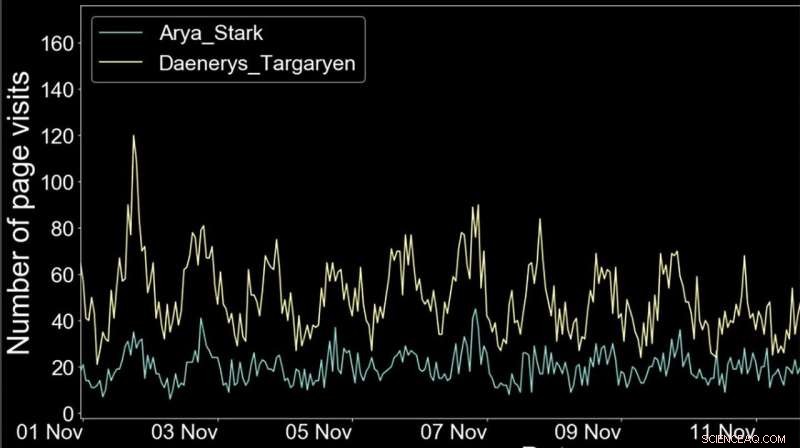
Fluttuazioni delle visite alle pagine di Wikipedia per due caratteri GoT nel tempo. Credito:LTS2/EPFL
Benzi e Miz chiamano questo tipo di ricerca di informazioni "memoria collettiva, " in quanto può rivelare come gli eventi attuali inneschino ricordi del passato.
"La ricerca su Wikipedia riguarda il tentativo di esplorare nuove scoperte sulla stessa natura umana. Wikipedia è un set di dati molto interessante perché riflette più o meno ciò che noi come umanità decidiamo di ricordare. Collettivamente, abbiamo lo stesso filo conduttore e navighiamo sugli stessi argomenti, "dice Benzi.
Così, quali argomenti interessano di più alle persone, secondo questa ricerca? In breve:altre persone.
"Circa l'80% delle visite è per intrattenimento o celebrità. In ricerche passate, abbiamo scoperto che il 40% di tutti i link cliccati riguarda persone e le loro relazioni, "Benzi dice, aggiungendo che meno dell'1% delle visite riguarda argomenti legati alla scienza.
LTS2 sta attualmente collaborando con gli sviluppatori del browser web offline gratuito Kiwix, che mira a portare versioni compresse di Wikipedia a coloro che non hanno accesso gratuito a Internet.
"Il nostro metodo potrebbe essere molto utile a Kiwix per aiutare a identificare e comprimere solo parti rilevanti di Wikipedia, basata sulla lingua e la cultura, Per esempio, " dice Miz.
Altre applicazioni dell'algoritmo potrebbero includere lo studio della diffusione di notizie false su Twitter monitorando i picchi nei retweet, o comprendere i collegamenti tra le dinamiche della rete di posta elettronica e gli eventi del mondo reale. Però, questi argomenti sono più difficili da studiare rispetto a Wikipedia a causa delle minori quantità di dati liberamente disponibili.

Questa visualizzazione dei dati mostra le pagine di Wikipedia sugli attori GoT, personaggi ed episodi. Credito:LTS2/EPFL
Caso di studio:Game of Thrones
Miz, Benzi e i suoi colleghi hanno usato il loro metodo per rilevare attività anomale sulle pagine di Wikipedia relative alla stagione finale dello show di successo della HBO Game of Thrones come esempio. Il dataset aperto risultante ha permesso loro di creare visualizzazioni di dati di pagine relative a diversi aspetti dello spettacolo, compresi gli attori, caratteri, le stagioni, Episodi, e altri argomenti.
I ricercatori sono stati anche in grado di utilizzare il metodo per determinare la popolarità dei personaggi in base al numero di visite alle loro pagine di Wikipedia nel tempo, e stanno attualmente cercando di vedere quali altre pagine sono state attivate dalla morte di un particolare personaggio dello show. Questo lavoro si basa su uno sforzo simile nel 2016 per analizzare l'universo di Star Wars.
Benzi osserva che la ricerca è un ottimo esempio di digital humanities, in cui i metodi della scienza dei dati e le tecnologie digitali sono applicati alla sociologia, letteratura, storia e altri campi umanistici.
"Le discipline umanistiche digitali sono un campo davvero interessante, ma funziona solo quando si dispone di una combinazione di diverse competenze di data science, ingegneria, psicologia, sociologia, arte e così via. Così, uno dei vantaggi è la possibilità di collaborare tra laboratori, "dice Benzi.