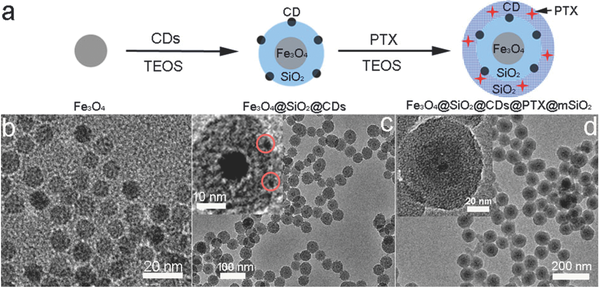
I ricercatori del MIT stanno addestrando un paio di reti generative avversarie, o GAN, imitare la terra, mare, e le trame delle nuvole viste nelle immagini satellitari con l'obiettivo di visualizzare l'innalzamento del livello del mare nel mondo reale. È uno dei tanti progetti di ricerca sull'intelligenza artificiale resi possibili dai crediti cloud donati da IBM e Google. Credito:Brandon Leshchinskiy
Le reti neurali hanno fornito ai ricercatori un potente strumento per guardare al futuro e fare previsioni. Ma uno svantaggio è il loro insaziabile bisogno di dati e potenza di calcolo ("calcolo") per elaborare tutte quelle informazioni. Al MIT, si stima che la domanda di calcolo sia cinque volte superiore a quella che l'Istituto può offrire. Per aiutare ad alleviare il crunch, l'industria è intervenuta. Un supercomputer da 11,6 milioni di dollari recentemente donato da IBM sarà online questo autunno, e nell'ultimo anno, sia IBM che Google hanno fornito crediti cloud a MIT Quest for Intelligence per la distribuzione in tutto il campus. Di seguito sono evidenziati quattro progetti resi possibili dalle donazioni cloud di IBM e Google.
Più piccoli, Più veloce, reti neurali più intelligenti
Per riconoscere un gatto in una foto, un modello di deep learning potrebbe aver bisogno di vedere milioni di foto prima che i suoi neuroni artificiali "imparano" a identificare un gatto. Il processo è computazionalmente intensivo e comporta un forte costo ambientale, come ha evidenziato una nuova ricerca che tenta di misurare l'impronta di carbonio dell'intelligenza artificiale (AI).
Ma potrebbe esserci un modo più efficiente. Una nuova ricerca del MIT mostra che i modelli sono necessari solo per una frazione delle dimensioni. "Quando alleni una grande rete ce n'è una piccola che avrebbe potuto fare tutto, "dice Jonathan Frankle, uno studente laureato presso il Dipartimento di Ingegneria Elettrica e Informatica (EECS) del MIT.
Con il coautore dello studio e il professor EECS Michael Carbin, Frankle stima che una rete neurale potrebbe cavarsela con un decimo del numero di connessioni se si trovasse la sottorete giusta all'inizio. Normalmente, le reti neurali vengono tagliate dopo il processo di addestramento, con connessioni irrilevanti rimosse quindi. Perché non addestrare il modello piccolo per cominciare, si chiedeva Frankle?
Sperimentando una rete a due neuroni sul suo laptop, Frankle ha ottenuto risultati incoraggianti e si è spostato su set di dati di immagini più grandi come MNIST e CIFAR-10, prendendo in prestito GPU dove poteva. Finalmente, tramite IBM Cloud, ha ottenuto una potenza di calcolo sufficiente per addestrare un modello ResNet reale. "Tutto quello che avevo fatto in precedenza erano esperimenti con i giocattoli, " dice. "Finalmente sono stato in grado di eseguire dozzine di impostazioni diverse per assicurarmi di poter fare le affermazioni nel nostro documento".
Frankle ha parlato dagli uffici di Facebook, dove ha lavorato per l'estate per esplorare le idee sollevate dal suo documento Ipotesi del biglietto della lotteria, uno dei due selezionati per il premio come miglior articolo alla Conferenza internazionale sulle rappresentazioni dell'apprendimento di quest'anno. Le potenziali applicazioni per il lavoro vanno oltre la classificazione delle immagini, Frankle dice, e includono modelli di apprendimento per rinforzo e di elaborazione del linguaggio naturale. Già, ricercatori di Facebook AI Research, Università di Princeton, e Uber hanno pubblicato studi successivi.
"Quello che amo delle reti neurali è che non abbiamo ancora gettato le basi, "dice Frankle, che di recente è passato dallo studio della crittografia e della politica tecnologica all'intelligenza artificiale. "Davvero non capiamo come impara, dove va bene e dove fallisce. Questa è la fisica 1, 000 anni prima di Newton."
Fatto distintivo dalle notizie false
Le piattaforme di networking come Facebook e Twitter hanno reso più facile che mai trovare notizie di qualità. Ma troppo spesso, le notizie vere sono soffocate da informazioni fuorvianti o completamente false pubblicate online. La confusione su un recente video della presidentessa della Camera degli Stati Uniti Nancy Pelosi manipolata per farla sembrare ubriaca è solo l'ultimo esempio della minaccia che la disinformazione e le notizie false rappresentano per la democrazia.
"Puoi mettere qualsiasi cosa su Internet ora, e alcune persone ci crederanno, "dice Moin Nadeem, un senior e EECS major al MIT.
Se la tecnologia ha contribuito a creare il problema, può anche aiutare a risolverlo. Questa è stata la ragione per cui Nadeem ha scelto un progetto superUROP incentrato sulla costruzione di un sistema automatizzato per combattere le notizie false e fuorvianti. Lavorando nel laboratorio di James Glass, un ricercatore presso il Computer Science and Artificial Intelligence Laboratory del MIT, e supervisionato da Mitra Mohtarami, Nadeem ha aiutato a formare un modello linguistico per verificare le affermazioni effettuando ricerche su Wikipedia e tre tipi di fonti di notizie valutate dai giornalisti come di alta qualità, di qualità mista o di bassa qualità.
Per verificare un reclamo, il modello misura quanto strettamente concordano le fonti, con punteggi di accordo più alti che indicano che l'affermazione è probabilmente vera. Un alto punteggio di disaccordo per un'affermazione come, "L'ISIS si infiltra negli Stati Uniti, " è un forte indicatore di notizie false. Uno svantaggio di questo metodo, lui dice, è che il modello non identifica la verità indipendente tanto quanto descrive ciò che la maggior parte delle persone pensa sia vero.
Con l'aiuto di Google Cloud Platform, Nadeem ha eseguito esperimenti e creato un sito Web interattivo che consente agli utenti di valutare istantaneamente l'accuratezza di un reclamo. Lui e i suoi coautori hanno presentato i loro risultati alla conferenza della North American Association of Computational Linguistics (NAACL) a giugno e stanno continuando ad espandere il lavoro.
"Il detto era che vedere per credere, "dice Nadem, in questo video sul suo lavoro. "Ma stiamo entrando in un mondo in cui questo non è vero. Se le persone non possono fidarsi dei loro occhi e delle loro orecchie, diventa una questione di cosa possiamo fidarci?"
Visualizzare un clima caldo
Dall'innalzamento dei mari all'aumento della siccità, gli effetti del cambiamento climatico si fanno già sentire. Tra qualche decennio, il mondo sarà più caldo, più secco, e luogo più imprevedibile. Brandon Leshchinskiy, uno studente laureato presso il Dipartimento di aeronautica e astronautica del MIT (AeroAstro), sta sperimentando reti generative avversarie, o GAN, immaginare come sarà la Terra allora.
I GAN producono immagini iperrealistiche mettendo una rete neurale contro un'altra. La prima rete apprende la struttura sottostante di un insieme di immagini e cerca di riprodurle, mentre il secondo decide quali immagini sembrano non plausibili e dice alla prima rete di riprovare.
Ispirato dai ricercatori che hanno utilizzato i GAN per visualizzare le proiezioni dell'innalzamento del livello del mare da immagini di street view, Leshchinskiy voleva vedere se le immagini satellitari potessero personalizzare in modo simile le proiezioni climatiche. Con il suo consigliere, Professoressa AeroAstro Dava Newman, Leshchinskiy sta attualmente utilizzando crediti IBM Cloud gratuiti per addestrare una coppia di GAN sulle immagini della costa orientale degli Stati Uniti con i corrispondenti punti di elevazione. L'obiettivo è visualizzare come le proiezioni dell'innalzamento del livello del mare per il 2050 ridisegnano la costa. Se il progetto funziona, Leshinskiy spera di utilizzare altri set di dati della NASA per immaginare la futura acidificazione degli oceani e i cambiamenti nell'abbondanza di fitoplancton.
"Siamo oltre il punto di mitigazione, ", dice. "Visualizzare come sarà il mondo tra tre decenni può aiutarci ad adattarci ai cambiamenti climatici".
Identificare gli atleti da pochi gesti
Pochi movimenti in campo o in campo sono sufficienti per un modello di visione artificiale per identificare i singoli atleti. Questo secondo una ricerca preliminare di un team guidato da Katherine Gallagher, un ricercatore al MIT Quest for Intelligence.
Il team ha addestrato modelli di visione artificiale su registrazioni video di partite di tennis e partite di calcio e basket e ha scoperto che i modelli potevano riconoscere i singoli giocatori in pochi fotogrammi dai punti chiave del loro corpo, fornendo una sagoma approssimativa del loro scheletro.
Il team ha utilizzato un'API Google Cloud per elaborare i dati video, e hanno confrontato le prestazioni dei loro modelli con i modelli addestrati sulla piattaforma AI di Google Cloud. "Queste informazioni sulla posa sono così distintive che i nostri modelli possono identificare i giocatori con precisione quasi quanto i modelli dotati di molte più informazioni, come il colore dei capelli e i vestiti, " lei dice.
I loro risultati sono rilevanti per l'identificazione automatizzata dei giocatori nei sistemi di analisi sportiva, e potrebbero fornire una base per ulteriori ricerche su come dedurre l'affaticamento del giocatore per anticipare quando i giocatori dovrebbero essere sostituiti. Il rilevamento automatico della posa potrebbe anche aiutare gli atleti a perfezionare la loro tecnica consentendo loro di isolare i movimenti precisi associati alla guida esperta di un golfista o allo swing vincente di un giocatore di tennis.
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.