
Quando il futuro è incerto, la ricompensa futura può essere rappresentata come una distribuzione di probabilità. alcuni possibili futuri sono buoni (verde acqua), altri sono cattivi (rosso). L'apprendimento del rinforzo distributivo può conoscere questa distribuzione sui premi previsti attraverso una variante dell'algoritmo TD. Credito: Natura (2020). DOI:10.1038/s41586-019-1924-6
Un team di ricercatori di DeepMind, L'University College e l'Università di Harvard hanno scoperto che le lezioni apprese nell'applicazione delle tecniche di apprendimento ai sistemi di intelligenza artificiale possono aiutare a spiegare come funzionano i percorsi di ricompensa nel cervello. Nel loro articolo pubblicato sulla rivista Natura , il gruppo descrive il confronto dell'apprendimento per rinforzo distributivo in un computer con l'elaborazione della dopamina nel cervello del topo, e cosa hanno imparato da esso.
Ricerche precedenti hanno dimostrato che la dopamina prodotta nel cervello è coinvolta nell'elaborazione della ricompensa:viene prodotta quando accade qualcosa di buono, e la sua espressione si traduce in sensazioni di piacere. Alcuni studi hanno anche suggerito che i neuroni del cervello che rispondono alla presenza di dopamina rispondono tutti allo stesso modo:un evento fa sentire bene o male una persona o un topo. Altri studi hanno suggerito che la risposta neuronale è più di un gradiente. In questo nuovo sforzo, i ricercatori hanno trovato prove a sostegno di quest'ultima teoria.
L'apprendimento per rinforzo distributivo è un tipo di apprendimento automatico basato sul rinforzo. Viene spesso utilizzato durante la progettazione di giochi come Starcraft II o Go. Tiene traccia delle mosse buone rispetto a quelle cattive e impara a ridurre il numero di mosse sbagliate, migliorando le sue prestazioni più suona. Ma tali sistemi non trattano tutte le mosse buone e cattive allo stesso modo:ogni mossa viene ponderata man mano che viene registrata e i pesi fanno parte dei calcoli utilizzati quando si effettuano scelte di mosse future.
I ricercatori hanno notato che gli umani sembrano usare una strategia simile per migliorare il loro livello di gioco, anche. I ricercatori di Londra sospettavano che le somiglianze tra i sistemi di intelligenza artificiale e il modo in cui il cervello esegue l'elaborazione della ricompensa fossero probabilmente simili, anche. Per sapere se erano corretti, hanno effettuato esperimenti con i topi. Hanno inserito nei loro cervelli dispositivi in grado di registrare le risposte dei singoli neuroni dopaminergici. I topi sono stati quindi addestrati a svolgere un compito in cui hanno ricevuto ricompense per aver risposto nel modo desiderato.
Le risposte dei neuroni di topo hanno rivelato che non tutti rispondevano allo stesso modo, come la teoria precedente aveva previsto. Anziché, hanno risposto in modo affidabile in modi diversi, un'indicazione che i livelli di piacere che i topi stavano provando erano più di un gradiente, come la squadra aveva previsto.
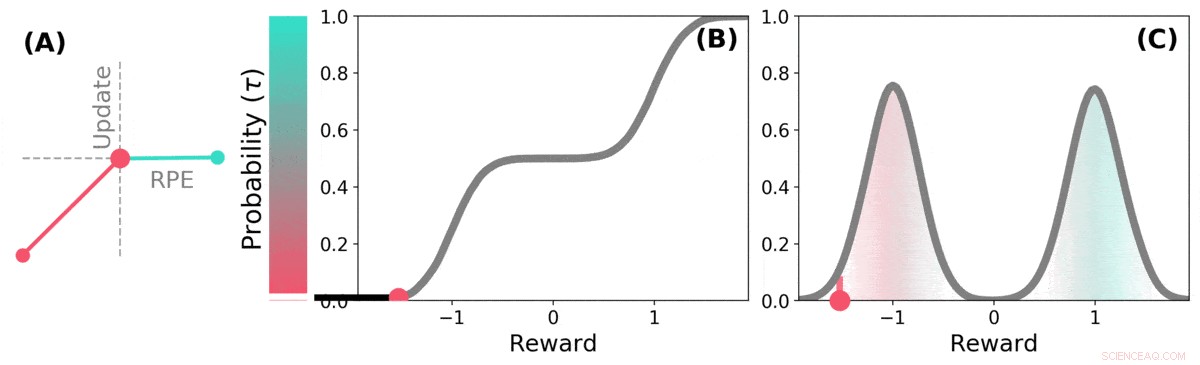
Il TD distributivo apprende le stime del valore per molte parti diverse della distribuzione dei premi. quale parte copre una determinata stima è determinata dal tipo di aggiornamento asimmetrico applicato a tale stima. (a) Una cella "pessimista" amplificherebbe gli aggiornamenti negativi e ignorerebbe gli aggiornamenti positivi, una cella "ottimista" amplificherebbe gli aggiornamenti positivi e ignorerebbe gli aggiornamenti negativi. (b) Ciò si traduce in una diversità di stime di valore pessimistiche o ottimistiche, mostrato qui come punti lungo la distribuzione cumulativa dei premi, che cattura (c) La piena distribuzione dei premi. Credito: Natura (2020). DOI:10.1038/s41586-019-1924-6
© 2020 Scienza X Rete














