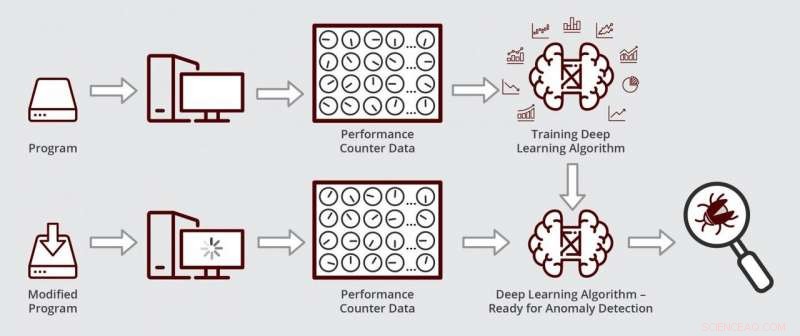
Schema che illustra come funziona l'algoritmo di deep learning di Muzahid. L'algoritmo è pronto per il rilevamento delle anomalie dopo essere stato addestrato per la prima volta sui dati del contatore delle prestazioni da una versione priva di bug di un programma. Credito:Texas A&M Engineering
Abbiamo condiviso tutti la frustrazione:gli aggiornamenti software che hanno lo scopo di velocizzare l'esecuzione delle nostre applicazioni finiscono inavvertitamente per fare esattamente l'opposto. Questi bug, soprannominati nel campo dell'informatica come regressioni delle prestazioni, richiedono molto tempo per risolverli poiché l'individuazione degli errori del software richiede normalmente un intervento umano sostanziale.
Per superare questo ostacolo, ricercatori della Texas A&M University, in collaborazione con scienziati informatici presso Intel Labs, hanno ora sviluppato un modo completamente automatizzato per identificare l'origine degli errori causati dagli aggiornamenti del software. Il loro algoritmo basato su una forma specializzata di machine learning chiamata deep learning, non è solo chiavi in mano, ma anche veloce, trovare bug di prestazioni nel giro di poche ore invece che di giorni.
"L'aggiornamento del software a volte può metterti in difficoltà quando gli errori si insinuano e causano rallentamenti. Questo problema è ancora più esagerato per le aziende che utilizzano sistemi software su larga scala in continua evoluzione, " ha detto il dottor Abdullah Muzahid, ricercatore presso il Dipartimento di Informatica e Ingegneria. "Abbiamo progettato uno strumento conveniente per diagnosticare le regressioni delle prestazioni che è compatibile con un'intera gamma di software e linguaggi di programmazione, espandendo enormemente la sua utilità."
I ricercatori hanno descritto i loro risultati nella 32a edizione di Advances in Neural Information Processing Systems dagli atti della conferenza Neural Information Processing Systems di dicembre.
Per individuare la fonte degli errori all'interno del software, i debugger spesso controllano lo stato dei contatori delle prestazioni all'interno dell'unità di elaborazione centrale. Questi contatori sono righe di codice che controllano come il programma viene eseguito sull'hardware del computer in memoria, Per esempio. Così, quando il software è in esecuzione, i contatori tengono traccia del numero di volte in cui accede a determinate locazioni di memoria, il tempo che sta lì e quando esce, tra l'altro. Quindi, quando il comportamento del software va storto, i contatori vengono nuovamente utilizzati per la diagnostica.
"I contatori delle prestazioni danno un'idea dello stato di esecuzione del programma, " disse Muzahid. "Allora, se un programma non funziona come dovrebbe, questi contatori di solito hanno il segno rivelatore di un comportamento anomalo."
Però, i desktop e i server più recenti hanno centinaia di contatori delle prestazioni, rendendo praticamente impossibile tenere traccia di tutti i loro stati manualmente e quindi cercare schemi aberranti che siano indicativi di un errore di prestazione. È qui che entra in gioco l'apprendimento automatico di Muzahid.
Utilizzando l'apprendimento profondo, i ricercatori sono stati in grado di monitorare i dati provenienti da un gran numero di contatori contemporaneamente riducendo la dimensione dei dati, che è simile alla compressione di un'immagine ad alta risoluzione a una frazione della sua dimensione originale cambiando il suo formato. Nei dati dimensionali inferiori, il loro algoritmo potrebbe quindi cercare modelli che si discostano dal normale.
Quando il loro algoritmo fu pronto, i ricercatori hanno testato se fosse possibile trovare e diagnosticare un bug delle prestazioni in un software di gestione dei dati disponibile in commercio utilizzato dalle aziende per tenere traccia dei loro numeri e cifre. Primo, hanno addestrato il loro algoritmo a riconoscere i normali dati del contatore eseguendo un vecchio, versione senza problemi del software di gestione dei dati. Prossimo, hanno eseguito il loro algoritmo su una versione aggiornata del software con la regressione delle prestazioni. Hanno scoperto che il loro algoritmo ha individuato e diagnosticato il bug in poche ore. Muzahid ha affermato che questo tipo di analisi potrebbe richiedere molto tempo se eseguito manualmente.
Oltre a diagnosticare le regressioni delle prestazioni nel software, Muzahid ha notato che il loro algoritmo di deep learning ha potenziali usi anche in altre aree di ricerca, come lo sviluppo della tecnologia necessaria per la guida autonoma.
"L'idea di base è ancora una volta la stessa, cioè essere in grado di rilevare uno schema anomalo, " ha detto Muzahid. "Le auto a guida autonoma devono essere in grado di rilevare se un'auto o un essere umano si trova davanti e quindi agire di conseguenza. Così, è di nuovo una forma di rilevamento delle anomalie e la buona notizia è che è ciò per cui il nostro algoritmo è già progettato".
Altri contributori alla ricerca includono il Dr. Mejbah Alam, Dottor Justin Gottschlich, Dott.ssa Nesime Tatbul, Dr. Javier Turek e Dr. Timothy Mattson di Intel Labs.














