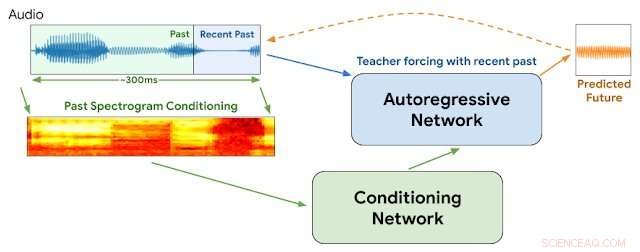
Architettura WaveNetEQ. Durante l'inferenza, "scaldiamo" la rete autoregressiva forzando l'insegnante con l'audio più recente. Dopo, il modello viene fornito con un proprio output come input per il passaggio successivo. Uno spettrogramma MEL da una parte audio più lunga viene utilizzato come input per la rete di condizionamento. Credito:Google
"È bello sentire la tua voce, sai che è passato così tanto tempo
Se non ricevo le tue chiamate, poi tutto va storto...
La tua voce oltre la linea mi dà una strana sensazione"
- Bionda, "Appeso al telefono"
Nel 1978, Debbie Harry ha portato la sua band new wave Blondie in cima alle classifiche con una storia lamentosa di desiderio di sentire la voce del suo ragazzo da lontano e insistendo sul fatto che non la lasciasse "appesa al telefono".
Ma sorgono le domande:e se fosse il 2020 e lei stesse parlando su VOIP con perdite di pacchetti intermittenti, tremolio dell'audio, ritardi di rete e trasmissioni di pacchetti fuori sequenza?
Non lo sapremo mai.
Ma Google questa settimana ha annunciato i dettagli di una nuova tecnologia per la sua popolare app vocale e video Duo che contribuirà a garantire trasmissioni vocali più fluide e a ridurre le lacune momentanee che a volte rovinano le connessioni basate su Internet. Ci piacerebbe pensare che Debbie approverebbe.
Abbiamo tutti sperimentato il jitter audio di Internet. Si verifica quando uno o più pacchetti di istruzioni che comprendono un flusso di istruzioni audio vengono ritardati o spostati in modo casuale tra il chiamante e l'ascoltatore. I metodi che utilizzano buffer di pacchetti vocali e intelligenza artificiale generalmente possono attenuare un jitter di 20 millisecondi o meno. Ma le interruzioni diventano più evidenti quando i pacchetti mancanti si sommano a 60 millisecondi e oltre.
Google afferma che praticamente tutte le chiamate subiscono una perdita di pacchetti di dati:un quinto di tutte le chiamate perde il 3% dell'audio e un decimo l'8%.
Questa settimana, I ricercatori di Google della divisione DeepMind hanno riferito di aver iniziato a utilizzare un programma chiamato WaveNetEQ per affrontare questi problemi. L'algoritmo eccelle nel colmare le lacune sonore momentanee con elementi vocali sintetizzati ma dal suono naturale. Basandosi su una voluminosa libreria di dati vocali, WaveNetEQ riempie le lacune sonore fino a 120 millisecondi. Tali scambi di bit sonori sono chiamati occultamenti della perdita di pacchetti (PLC).
"WaveNetEQ è un modello generativo basato sulla tecnologia WaveRNN di DeepMind, " Il blog AI di Google ha riportato il 1 aprile "che viene addestrato utilizzando un ampio corpus di dati vocali per continuare realisticamente segmenti di parlato brevi, consentendogli di sintetizzare completamente la forma d'onda grezza del parlato mancante".
Il programma ha analizzato i suoni di 100 parlanti in 48 lingue, concentrandosi sulle "caratteristiche del linguaggio umano in generale, invece delle proprietà di una lingua specifica, " ha spiegato il rapporto.
Inoltre, l'analisi del suono è stata testata in ambienti che offrono un'ampia varietà di rumore di fondo per aiutare a garantire un riconoscimento accurato da parte degli altoparlanti sui marciapiedi trafficati della città, stazioni ferroviarie o caffetterie.
Tutta l'elaborazione WaveNetEQ deve essere eseguita sul telefono del destinatario in modo che i servizi di crittografia non vengano compromessi. Ma la richiesta extra sulla velocità di elaborazione è minima, Google afferma. WaveNetEQ è "abbastanza veloce da funzionare su un telefono, pur fornendo una qualità audio all'avanguardia e un PLC dal suono più naturale rispetto ad altri sistemi attualmente in uso."
Esempi di suoni che illustrano il jitter audio e il miglioramento con WabeNetEQ sono pubblicati nel report del blog di Google.
© 2020 Scienza X Rete