Secondo l'Organizzazione Mondiale della Sanità, le frane sono più diffuse di qualsiasi altro evento geologico. Credito:NASA
Gli studenti laureati dell'Università della British Columbia hanno addestrato i computer a "leggere" articoli di notizie sulle frane su Reddit per rafforzare un database della NASA, che potrebbe migliorare le previsioni di quando e dove si verificheranno questi disastri naturali.
Per il loro progetto capstone del Master in Data Science in Computational Linguistics, Badr Jaidi e il suo team, il gruppo Social Landslides, hanno addestrato i computer a estrarre automaticamente informazioni utili da articoli di notizie rilevanti sulle frane che sono stati pubblicati su Reddit. In questa sessione di domande e risposte, discute di come questo strumento potrebbe finire per salvare vite umane.
Perché abbiamo bisogno di questo strumento?
Secondo l'Organizzazione Mondiale della Sanità, le frane sono più diffuse di qualsiasi altro evento geologico. Sono così distruttivi e non abbiamo molti dati su di loro. Più sono accurati i dati sulle frane, più è possibile prevedere con precisione quali luoghi presentano un rischio maggiore, il che alla fine potrebbe salvare vite umane.
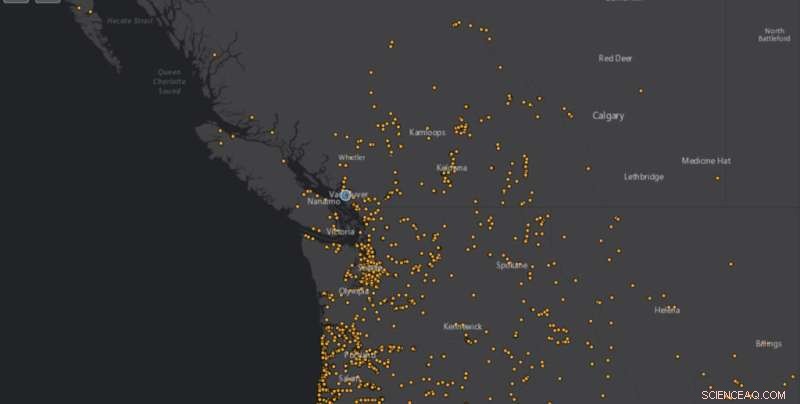
La NASA raccoglie tali informazioni in un database pubblico chiamato Cooperative Open Online Repository, o COOLR, e lo utilizza per prevedere quando e dove si verificheranno frane. Ma le persone hanno dovuto inviare manualmente informazioni sulle frane o cercare articoli e dati di notizie uno per uno, il che è piuttosto noioso. Il nostro strumento automatizza tale processo, completando in pochi minuti ciò che in precedenza avrebbe potuto richiedere mesi.
Ciò libererebbe risorse per ricerche più importanti e significherebbe anche ottenere più dati, più velocemente e potenzialmente migliorare la ricerca sulle frane in generale, nonché le previsioni delle frane della NASA.
Come funziona?
Guidato da BGC Engineering Inc. e dalla NASA per il nostro progetto Capstone, il nostro team ha progettato uno strumento che scansiona Reddit alla ricerca di articoli sulle frane entro un determinato periodo di tempo e quindi estrae informazioni rilevanti.
In primo luogo, un modello al computer determina se l'articolo riguarda davvero le frane, piuttosto che un'elezione in cui qualcuno vince "per una frana" o, come abbiamo anche scoperto, articoli su Pokémon con tecniche della terra come "frana di roccia".
Quindi, abbiamo addestrato un modello di elaborazione del linguaggio naturale sui dati delle frane, insegnandogli a riconoscere le informazioni che volevamo da un articolo. Questo tipo di modello può comprendere il linguaggio, inclusa l'analisi delle frasi. Quindi, gli davamo un articolo di notizie e chiedevamo dove potrebbe essere avvenuta una frana. Il modello prevederebbe la risposta in base alla lingua coinvolta, ad esempio "La frana molto probabilmente è avvenuta qui, secondo questa frase", e gli faremmo sapere se era corretta o meno.
In questo modo, il computer apprende quali informazioni estrarre automaticamente e con precisione, incluso quando si è verificata una frana e dove, cosa l'ha causata e quanti decessi sono stati coinvolti.
Tutto ciò avviene abbastanza rapidamente:restituisce un mese di articoli in circa 15 minuti, rispetto a quando li sfoglia manualmente per trovare quelle informazioni. I dati possono quindi essere inseriti in COOLR. Ci sono voluti circa due mesi per costruire. La NASA sta attualmente valutando se lo strumento può essere eseguito così com'è o necessita di alcune modifiche per essere utilizzato.
Lo strumento potrebbe essere utilizzato su altri siti di social media?
Abbiamo usato Reddit perché è gratuito per accedere alla loro API (Application Programming Interface). Ad esempio, l'API di Twitter ha molte restrizioni ed è piuttosto costoso accedervi. Inoltre, la quantità di dati sarebbe enorme.
Volevamo iniziare in piccolo e dimostrare che funziona con Reddit. Ma potrebbe essere esteso a piattaforme e fonti più grandi, a condizione che abbiano articoli di notizie. Potresti anche espandere lo strumento per usarlo per altri disastri come i terremoti, utilizzando la stessa metodologia addestrando i modelli con set di dati simili.
Migliorare il modello e aggiungere più fonti da cui possono essere estratte le frane diverse da Reddit aiuterebbe in definitiva la NASA ad avere più punti dati, più velocemente. Lo terrò d'occhio. + Esplora ulteriormente