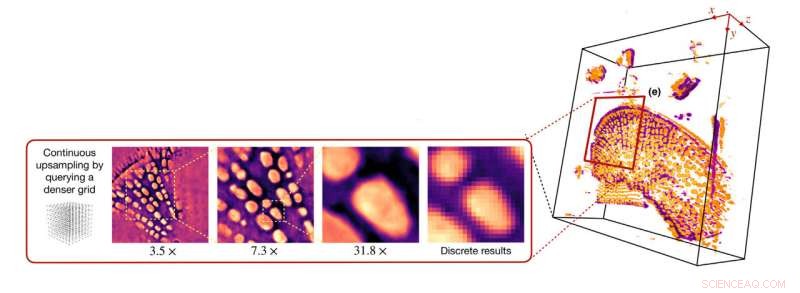
Il sistema di imaging può ingrandire un'immagine pixelata e riempire i pezzi mancanti, creando una rappresentazione 3D continua. Credito:Washington University di St. Louis
I ricercatori della McKelvey School of Engineering della Washington University di St. Louis hanno sviluppato un algoritmo di apprendimento automatico in grado di creare un modello 3D continuo di cellule da un insieme parziale di immagini 2D che sono state acquisite utilizzando gli stessi strumenti di microscopia standard che si trovano oggi in molti laboratori .
Le loro scoperte sono state pubblicate il 16 settembre sulla rivista Nature Machine Intelligence .
"Formiamo il modello sull'insieme delle immagini digitali per ottenere una rappresentazione continua", ha affermato Ulugbek Kamilov, assistente professore di ingegneria elettrica e dei sistemi e di informatica e ingegneria. "Ora posso mostrarlo come voglio. Posso ingrandire senza problemi e non ci sono pixel."
La chiave di questo lavoro è stata l'uso di una rete di campo neurale, un particolare tipo di sistema di apprendimento automatico che apprende una mappatura dalle coordinate spaziali alle corrispondenti quantità fisiche. Al termine della formazione, i ricercatori possono puntare a qualsiasi coordinata e il modello può fornire il valore dell'immagine in quella posizione.
Un punto di forza particolare delle reti di campo neurale è che non hanno bisogno di essere addestrate su abbondanti quantità di dati simili. Invece, finché c'è un numero sufficiente di immagini 2D del campione, la rete può rappresentarlo nella sua interezza, dentro e fuori.
L'immagine utilizzata per addestrare la rete è proprio come qualsiasi altra immagine di microscopia. In sostanza, una cella è illuminata dal basso; la luce lo attraversa e viene catturata dall'altra parte, creando un'immagine.
"Poiché ho alcune viste della cella, posso usare quelle immagini per addestrare il modello", ha detto Kamilov. Questo viene fatto alimentando le informazioni del modello su un punto del campione in cui l'immagine ha catturato parte della struttura interna della cella.
Quindi la rete fa del suo meglio per ricreare quella struttura. Se l'output è sbagliato, la rete è ottimizzata. Se è corretto, quel percorso è rafforzato. Una volta che le previsioni corrispondono alle misurazioni del mondo reale, la rete è pronta per riempire parti della cella che non sono state catturate dalle immagini 2D originali.
Il modello ora contiene informazioni su una rappresentazione completa e continua della cella:non è necessario salvare un file immagine ricco di dati perché può sempre essere ricreato dalla rete del campo neurale.
E, ha detto Kamilov, non solo il modello è una rappresentazione fedele e facile da memorizzare della cellula, ma anche, per molti versi, è più utile della cosa reale.
"Posso inserire qualsiasi coordinata e generare quella vista", ha detto. "Oppure posso generare viste completamente nuove da diverse angolazioni". Può usare il modello per ruotare una cella come una cima o ingrandire per dare un'occhiata più da vicino; utilizzare il modello per svolgere altri compiti numerici; o addirittura inserirlo in un altro algoritmo. + Esplora ulteriormente