I ricercatori del Courant Institute of Mathematical Sciences della New York University hanno delineato un metodo per memorizzare programmi all'interno del DNA che semplifica il nanocomputing, il calcolo a livello molecolare. Co-autore di Jessie Chang e Dennis Shasha, Programmi memorizzati all'interno del DNA:un framework semplificato per il nanocomputing (Morgan e Claypool) descrive come costruire milioni di programmi DNA da cui è possibile estrarre le istruzioni una alla volta da ciascun programma in sincronia.
La motivazione per questo lavoro è simile a quella per i programmi memorizzati all'interno del tuo laptop. Prima dei computer, c'erano calcolatrici meccaniche in cui gli individui premevano i tasti secondo una procedura e alla fine appariva un numero. Una volta che i calcolatori sono diventati più veloci, divenne chiaro che ciò che doveva migliorare era il processo di punzonatura, non il tasso di calcolo. Per fare questo, i primi progettisti di computer memorizzavano i programmi contenenti istruzioni di "punzonatura" all'interno delle macchine in modo che potessero funzionare da soli. Una volta memorizzate queste istruzioni, l'intero calcolo potrebbe essere eseguito alla velocità della macchina.
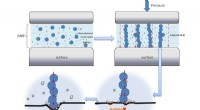
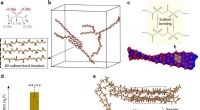
Programmi con clock memorizzati Inside DNA offre un percorso per fare lo stesso per il calcolo del DNA. Mentre i computer si basano su dati archiviati in stringhe di 0 e 1, Il DNA, gli elementi costitutivi della vita, immagazzina le informazioni nelle molecole ("basi") rappresentate da A, T, C, e G. Due singoli filamenti di DNA si legheranno se ogni A in un filamento è allineato con ogni T nell'altro e allo stesso modo per C e G. Se solo alcune delle basi del filamento s1 sono allineate con i loro partner preferiti in s2, quindi un altro filo s3 con un allineamento migliore spingerà s1 fuori strada. Questo fenomeno di "spostamento" consente ai ricercatori di creare sculture di DNA e nanorobot. Però, come calcolatrici portatili, Il calcolo del DNA attualmente si basa sul versamento di provette di DNA in una provetta di DNA più grande, ostacolandone la velocità e rendendone delicato l'utilizzo.
Nel loro libro, Shasha e Chang offrono un metodo per memorizzare le istruzioni del DNA all'interno di una soluzione chimica in modo tale da consentire al processo di calcolo di funzionare secondo un orologio globale costituito da speciali filamenti di DNA chiamati "tick" e "tock". Ogni volta che un "tick" e un "tock" entrano in un tubo del DNA, un filamento di istruzioni viene rilasciato da una pila di istruzioni. Questo è simile al modo in cui un ciclo di clock in un computer elettronico fa sì che una nuova istruzione entri in un'unità di elaborazione. Finché rimangono dei fili in pila, il ciclo successivo rilascerà un nuovo filone di istruzioni. Indipendentemente dall'effettivo filamento o componente da rilasciare in un particolare passo di clock, i fili "tick" e "tock" rimangono gli stessi, in effetti, fungendo da dispositivo di input automatizzato e eliminando l'immissione manuale dei dati.
Aidan Dali, uno studente di Harvard in uno stage estivo alla New York University, ha lavorato con Shasha e Chang per testare il loro processo di costruzione nel laboratorio del professore di chimica della NYU Nadrian Seeman, che ha fondato e sviluppato il campo della nanotecnologia del DNA. Le creazioni di Seeman, che vanno da strutture di DNA tridimensionali a una catena di montaggio del DNA, gli consentono di organizzare pezzi e formare molecole specifiche su scala nanometrica con una certa precisione, simile al modo in cui si può dire a una fabbrica di automobili robotiche che tipo di auto produrre.