Esempio di frame video affollato annotato utilizzando il nuovo metodo. Credito:Růžička e Franchetti.
I ricercatori della Carnegie Mellon University hanno recentemente sviluppato un nuovo modello che consente il rilevamento rapido e accurato degli oggetti nelle riprese video 4K e 8K ad alta risoluzione utilizzando le GPU. Il loro metodo di pipeline di attenzione esegue una valutazione in due fasi di ogni immagine o fotogramma video con una risoluzione approssimativa e raffinata, limitando il numero totale di valutazioni necessarie.
Negli ultimi anni, l'apprendimento automatico ha ottenuto risultati notevoli nelle attività di visione artificiale, compreso il rilevamento di oggetti. Però, la maggior parte dei modelli di riconoscimento degli oggetti in genere offre prestazioni migliori su immagini con una risoluzione relativamente bassa. Poiché la risoluzione dei dispositivi di registrazione sta migliorando rapidamente, c'è una crescente necessità di strumenti in grado di elaborare dati ad alta risoluzione.
"Eravamo interessati a trovare e superare i limiti degli approcci attuali, "Vít Růžička, uno dei ricercatori che hanno condotto lo studio ha detto a TechXplore. "Mentre molte fonti di dati registrano in alta risoluzione, attuali modelli di rilevamento di oggetti all'avanguardia, come YOLO, RCNN più veloce, SSD, eccetera., lavorare con immagini che hanno una risoluzione relativamente bassa di circa 608 x 608 px. Il nostro obiettivo principale era quello di ridimensionare l'attività di rilevamento degli oggetti su video 4K-8K (fino a 7680 x 4320 px) mantenendo un'elevata velocità di elaborazione. Volevamo anche capire se e quanto possiamo trarre vantaggio dall'alta risoluzione rispetto all'utilizzo di immagini a bassa risoluzione, in termini di accuratezza dei modelli."
La pipeline dell'attenzione proposta da Růžička e dal suo collega Franz Franchetti divide il compito del rilevamento degli oggetti in due fasi. In entrambe queste fasi, i ricercatori hanno suddiviso l'immagine originale sovrapponendola con una griglia regolare e poi hanno applicato il modello YOLO v2 per il rilevamento rapido degli oggetti.
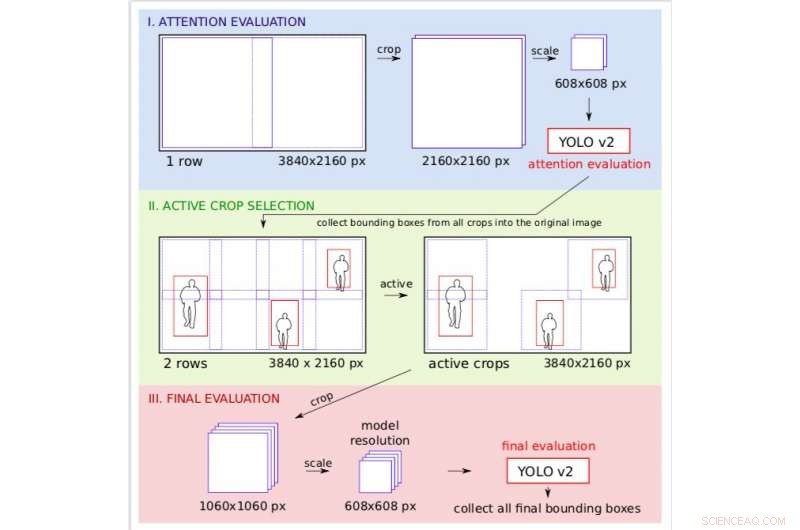
Gestione della risoluzione nell'esempio dell'elaborazione di fotogrammi video 4K. Durante la fase di attenzione l'immagine viene elaborata con una risoluzione approssimativa, consentendo ai ricercatori di decidere quali regioni dell'immagine dovrebbero essere attive nella valutazione finale più fine. Credito:Růžička e Franchetti.
"Noi creiamo tante piccole colture rettangolari, che può essere elaborato da YOLO v2 su diversi server worker, parallelamente, " ha spiegato Růžička. "La prima fase esamina l'immagine ridimensionata a una risoluzione inferiore ed esegue un rilevamento rapido dell'oggetto per ottenere riquadri di delimitazione approssimativi. La seconda fase utilizza questi riquadri di delimitazione come mappa dell'attenzione per decidere dove è necessario controllare l'immagine ad alta risoluzione. Perciò, quando alcune aree dell'immagine non contengono alcun oggetto di interesse, possiamo risparmiare sull'elaborazione in alta risoluzione."
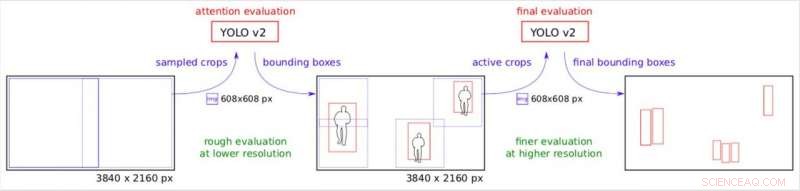
Il canale dell'attenzione. Scomposizione graduale dell'immagine originale con una diversa risoluzione effettiva. Credito:Růžička e Franchetti.
I ricercatori hanno implementato il loro modello in codice, distribuendo il suo lavoro su GPU. Sono stati in grado di mantenere un'elevata precisione raggiungendo prestazioni medie da tre a sei fps su video 4K e due fps su video 8K. Il loro metodo ha prodotto vantaggi significativi, con la precisione media misurata sul set di dati testato che aumenta da 33,6 AP 50 a 74,3 AP 50 durante l'elaborazione di immagini ad alta risoluzione rispetto al ridimensionamento delle immagini a bassa risoluzione, è così che generalmente funziona YOLO v2.
"Il nostro metodo ha ridotto il tempo necessario per elaborare le immagini ad alta risoluzione di circa il 20%, rispetto all'elaborazione di ogni parte dell'immagine originale ad alta risoluzione, " Růžička ha detto. "L'implicazione pratica di questo è che l'elaborazione video 4K quasi in tempo reale è fattibile. Il nostro metodo richiede anche un numero inferiore di lavoratori server per completare questa attività".
Nonostante i risultati molto promettenti ottenuti da questo nuovo metodo di rilevamento degli oggetti, l'uso di una griglia regolare che si sovrappone all'immagine originale può dar luogo a una serie di problemi. Ad esempio, a volte può comportare che gli oggetti rilevati vengano tagliati a metà, che richiede una fase di post-elaborazione sui riquadri di delimitazione rilevati. Růžička e Franchetti stanno attualmente esplorando modi per affrontare e aggirare questi problemi per migliorare ulteriormente il loro modello.
© 2018 Science X Network