 Mentre gli attuali sistemi di traduzione possono generare solo output vocale tradotto o sottotitoli testuali per i contenuti video, il protocollo di traduzione automatica faccia a faccia può sincronizzare il visual, quindi lo stile della voce e il movimento delle labbra corrispondono alla lingua di destinazione. Prajwal Renukanand
Mentre gli attuali sistemi di traduzione possono generare solo output vocale tradotto o sottotitoli testuali per i contenuti video, il protocollo di traduzione automatica faccia a faccia può sincronizzare il visual, quindi lo stile della voce e il movimento delle labbra corrispondono alla lingua di destinazione. Prajwal Renukanand Un team di ricercatori in India ha ideato un sistema per tradurre le parole in una lingua diversa e far sembrare che le labbra di chi parla si muovano in sincronia con quella lingua.
Traduzione automatica faccia a faccia, come descritto in questo documento di ottobre 2019, è un progresso rispetto alla traduzione da testo a testo o da sintesi vocale, perché non solo traduce il discorso, ma fornisce anche un'immagine facciale sincronizzata con le labbra.
Per capire come funziona, guarda il video dimostrativo qui sotto, creato dai ricercatori. Al segno delle 6:38, vedrai un videoclip della defunta principessa Diana in un'intervista del 1995 con il giornalista Martin Bashir, spiegando, "Vorrei essere la regina dei cuori delle persone, nel cuore delle persone, ma non mi vedo come una regina di questo paese".
Un momento dopo, la vedrai pronunciare la stessa citazione in hindi - con le labbra che si muovono, come se parlasse davvero quella lingua.
"Comunicare efficacemente attraverso le barriere linguistiche è sempre stata una grande aspirazione per gli esseri umani in tutto il mondo, " Prajwal K.R., uno studente laureato in informatica presso l'International Institute of Information Technology di Hyderabad, India, spiega via mail. È l'autore principale del giornale, insieme al suo collega Rudrabha Mukhopadhyay.
"Oggi, Internet è pieno di video di volti parlanti:YouTube (300 ore caricate al giorno), lezioni on line, videoconferenze, film, Programmi TV e così via, " Prajval, che porta il suo nome di battesimo, scrive. "Gli attuali sistemi di traduzione possono solo generare un output vocale tradotto o sottotitoli testuali per tali contenuti video. Non gestiscono la componente visiva. Di conseguenza, il discorso tradotto quando sovrapposto al video, i movimenti delle labbra non sarebbero sincronizzati con l'audio.
"Così, ci basiamo sui sistemi di traduzione vocale e proponiamo una pipeline che può prendere un video di una persona che parla in una lingua di partenza e produrre un video dello stesso oratore che parla in una lingua di destinazione in modo tale che lo stile della voce e i movimenti delle labbra corrispondano il discorso della lingua di destinazione, " Prajwal dice. "Così facendo, il sistema di traduzione diventa olistico, e come mostrato dalle nostre valutazioni umane in questo articolo, migliora significativamente l'esperienza dell'utente nella creazione e nel consumo di contenuti audiovisivi tradotti."
La traduzione faccia a faccia richiede una serie di operazioni complesse. "Dato un video di una persona che parla, abbiamo due principali flussi di informazioni da tradurre:le informazioni visive e quelle vocali, " spiega. Lo fanno in diversi passaggi principali. "Il sistema prima trascrive le frasi nel discorso utilizzando il riconoscimento vocale automatico (ASR). Questa è la stessa tecnologia utilizzata negli assistenti vocali (Google Assistant, ad esempio) nei dispositivi mobili." Successivamente, le frasi trascritte vengono tradotte nella lingua desiderata utilizzando modelli di traduzione automatica neurale, e quindi la traduzione viene convertita in parole pronunciate con un sintetizzatore di sintesi vocale, la stessa tecnologia utilizzata dagli assistenti digitali.
Finalmente, una tecnologia chiamata LipGAN corregge i movimenti delle labbra nel video originale in modo che corrispondano al discorso tradotto.
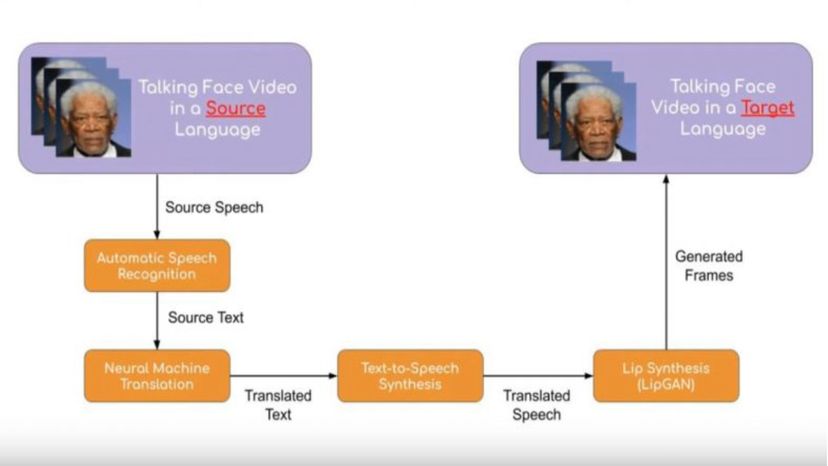 Come il discorso passa dall'input iniziale all'output sincronizzato. Prajwal Renukanand
Come il discorso passa dall'input iniziale all'output sincronizzato. Prajwal Renukanand "Così, otteniamo anche un video completamente tradotto con sincronizzazione labiale, "Spiega Prajwal.
"LipGAN è il nuovo contributo chiave del nostro articolo. Questo è ciò che porta la modalità visiva nell'immagine. È molto importante in quanto corregge la sincronizzazione labiale nel video finale, che migliora significativamente l'esperienza dell'utente."
Un articolo, pubblicato il 24 gennaio 2020 in New Scientist, ha descritto la svolta come un "deepfake, "un termine per i video in cui i volti sono stati scambiati o alterati digitalmente con l'aiuto dell'intelligenza artificiale, spesso per creare un'impressione fuorviante, come ha spiegato questa storia della BBC. Ma Prajwal sostiene che questa è una rappresentazione scorretta della traduzione faccia a faccia, che non ha lo scopo di ingannare, ma piuttosto per rendere il discorso tradotto più facile da seguire.
"Il nostro lavoro è principalmente mirato ad ampliare l'ambito dei sistemi di traduzione esistenti per gestire i contenuti video, " spiega. "Questo è un software creato con la motivazione di migliorare l'esperienza dell'utente e abbattere le barriere linguistiche tra i contenuti video. Apre una gamma molto ampia di applicazioni e migliora l'accessibilità di milioni di video online."
La sfida più grande nel rendere il lavoro di traduzione faccia a faccia è stato il modulo di generazione del volto. "I metodi attuali per creare video con sincronizzazione labiale non erano in grado di generare volti con le pose desiderate, rendendo difficile incollare la faccia generata nel video di destinazione, " Dice Prajwal. "Abbiamo incorporato una "posa prima" come input per il nostro modello LipGAN, e come risultato, possiamo generare un viso accurato sincronizzato con le labbra nella posa di destinazione desiderata che può essere perfettamente integrato nel video di destinazione."
I ricercatori prevedono che la traduzione faccia a faccia venga utilizzata nella traduzione di film e videochiamate tra due persone che parlano ciascuna una lingua diversa. "Fare cantare/parlare i personaggi digitali dei film d'animazione è dimostrato anche nel nostro video, "Note di Prajwal.
Inoltre, prevede che il sistema venga utilizzato per aiutare gli studenti di tutto il mondo a comprendere i video delle lezioni online in altre lingue. "Milioni di studenti di lingue straniere in tutto il mondo non riescono a comprendere gli eccellenti contenuti didattici disponibili online, perché sono in inglese, " lui spiega.
"Ulteriore, in un paese come l'India con 22 lingue ufficiali, il nostro sistema può, nel futuro, traduci i contenuti dei notiziari televisivi in diverse lingue locali con un'accurata sincronizzazione labiale dei presentatori delle notizie. L'elenco delle applicazioni si applica quindi a qualsiasi tipo di contenuto video con faccine parlanti, che deve essere reso più accessibile attraverso le lingue."
Sebbene Prajwal e i suoi colleghi intendano utilizzare la loro svolta in modo positivo, la capacità di mettere parole straniere in bocca a un oratore riguarda un eminente esperto di sicurezza informatica degli Stati Uniti, che teme che i video alterati diventino sempre più difficili da rilevare.
"Se guardi il video, puoi dire se guardi da vicino, la bocca ha un po' di sfocatura, "dice Anne Toomey McKenna, un illustre studioso di Cyberlaw and Policy presso la Dickinson Law della Penn State University, e professore presso l'Istituto universitario per le scienze computazionali e dei dati, in un'intervista via e-mail. "Ciò continuerà a essere ridotto al minimo man mano che gli algoritmi continueranno a migliorare. Diventerà sempre meno distinguibile dall'occhio umano".
McKenna per esempio, immagina come un video alterato del commentatore di MSNBC Rachel Maddow possa essere usato per influenzare le elezioni in altri paesi, "trasmettendo informazioni imprecise e l'opposto di ciò che ha detto".
Prajwal è preoccupato anche per il possibile uso improprio di video alterati, ma pensa che si possano sviluppare precauzioni per proteggersi da tali scenari, e che il potenziale positivo per aumentare la comprensione internazionale supera i rischi della traduzione automatica faccia a faccia. (Dal lato benefico, questo post sul blog prevede di tradurre il discorso di Greta Thunberg al vertice sul clima delle Nazioni Unite a settembre 2019 in una varietà di lingue diverse utilizzate in India.)
"Ogni potente pezzo di tecnologia può essere usato per un'enorme quantità di bene, e hanno anche effetti negativi, " Prajwal osserva. "Il nostro lavoro è, infatti, un sistema di traduzione in grado di gestire i contenuti video. Il contenuto tradotto da un algoritmo è sicuramente "non reale, ' ma questo contenuto tradotto è essenziale per le persone che non capiscono una lingua particolare. Ulteriore, nella fase attuale, tale contenuto tradotto automaticamente è facilmente riconoscibile da algoritmi e visualizzatori. Contemporaneamente, sono in corso ricerche attive per riconoscere tali contenuti alterati. Crediamo che lo sforzo collettivo di un uso responsabile, regole rigide, e i progressi della ricerca nell'individuare l'uso improprio possono garantire un futuro positivo per questa tecnologia".
Ora è cinematograficoSecondo Language Insight, uno studio condotto da ricercatori britannici ha stabilito che la preferenza degli spettatori per i film stranieri doppiati rispetto a quelli sottotitolati influisce sul tipo di film a cui gravitano. Coloro che amano i blockbuster mainstream hanno maggiori probabilità di vedere una versione doppiata di un film, mentre coloro che preferiscono i sottotitoli hanno maggiori probabilità di essere fan delle importazioni d'autore.














