I ricercatori hanno utilizzato l'apprendimento automatico per creare la prima, studio guidato dai dati per illuminare come la cultura influenza i significati delle parole. Credito:Dipinto della Torre di Babele di Pieter Bruegel il Vecchio, Kunsthistorisches Museum di Vienna, Vienna, Austria
Cosa intendiamo con la parola bello? Dipende non solo da chi chiedi, ma in che lingua glielo chiedi. Secondo un'analisi di apprendimento automatico di dozzine di lingue condotta presso la Princeton University, il significato delle parole non si riferisce necessariamente a un intrinseco, costante essenziale. Anziché, è significativamente modellato dalla cultura, storia e geografia. Questa constatazione vale anche per alcuni concetti che sembrerebbero universali, come le emozioni, caratteristiche del paesaggio e parti del corpo.
"Anche per ogni giorno le parole che pensereste significhino la stessa cosa per tutti, c'è tutta questa variabilità là fuori, " ha detto William Thompson, un ricercatore post-dottorato in informatica presso la Princeton University, e autore principale dei risultati, pubblicato in Natura Comportamento Umano 10 agosto. "Abbiamo fornito la prima prova basata sui dati che il modo in cui interpretiamo il mondo attraverso le parole fa parte della nostra eredità culturale".
Il linguaggio è il prisma attraverso il quale concettualizza e comprendiamo il mondo, e linguisti e antropologi hanno cercato a lungo di districare le complesse forze che modellano questi sistemi di comunicazione critici. Ma gli studi che tentano di affrontare queste domande possono essere difficili da condurre e richiedere molto tempo, spesso coinvolgendo lungo, attente interviste con relatori bilingue che valutano la qualità delle traduzioni. "Potrebbero volerci anni e anni per documentare una coppia specifica di lingue e le differenze tra loro, " ha detto Thompson. "Ma di recente sono emersi modelli di apprendimento automatico che ci consentono di porre queste domande con un nuovo livello di precisione".
Nel loro nuovo documento, Thompson e i suoi colleghi Seán Roberts dell'Università di Bristol, UK., e Gary Lupyan dell'Università del Wisconsin, madison, sfruttato la potenza di quei modelli per analizzare oltre 1, 000 parole in 41 lingue.
Invece di cercare di definire le parole, il metodo su larga scala utilizza il concetto di "associazioni semantiche, "o semplicemente parole che hanno una relazione significativa tra loro, che i linguisti considerano uno dei modi migliori per definire una parola e confrontarla con un'altra. Associati semantici di "bello, " Per esempio, includere "colorato, " "amore, " "prezioso" e "delicato".
I ricercatori hanno costruito un algoritmo che ha esaminato le reti neurali addestrate su vari linguaggi per confrontare milioni di associazioni semantiche. L'algoritmo ha tradotto gli associati semantici di una particolare parola in un'altra lingua, e poi ho ripetuto il procedimento al contrario. Per esempio, l'algoritmo ha tradotto gli associati semantici di "beautiful" in francese e quindi ha tradotto gli associati semantici di beau in inglese. Il punteggio finale di somiglianza dell'algoritmo per il significato di una parola è derivato dalla quantificazione di quanto la semantica fosse allineata in entrambe le direzioni della traduzione.
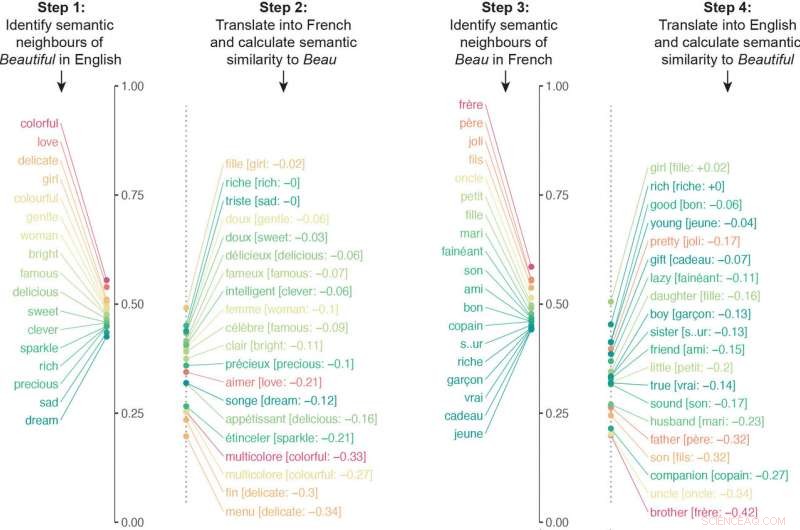
L'algoritmo ha tradotto gli associati semantici di una particolare parola in un'altra lingua, e poi ho ripetuto il procedimento al contrario. In questo esempio, i vicini semantici di "beautiful" sono stati tradotti in francese e quindi i vicini semantici di "beau" sono stati tradotti in inglese. Le rispettive liste erano sostanzialmente diverse a causa delle diverse associazioni culturali. Immagine per gentile concessione dei ricercatori. Credito:Princeton University
"Un modo per vedere cosa abbiamo fatto è un modo basato sui dati per quantificare quali parole sono più traducibili, "ha detto Thompson.
I risultati hanno rivelato che ci sono alcune parole quasi universalmente traducibili, principalmente quelli che si riferiscono ai numeri, professioni, le quantità, date di calendario e parentela. Molti altri tipi di parole, però, compresi quelli che si riferivano agli animali, cibo ed emozioni, erano molto meno ben assortiti nel significato.
In un ultimo passaggio, i ricercatori hanno applicato un altro algoritmo che ha confrontato quanto siano simili le culture che hanno prodotto le due lingue, sulla base di un set di dati antropologici che confronta cose come le pratiche matrimoniali, sistemi giuridici e organizzazione politica dei parlanti di una determinata lingua.
I ricercatori hanno scoperto che il loro algoritmo potrebbe prevedere correttamente la facilità con cui due lingue potrebbero essere tradotte in base a quanto siano simili le due culture che le parlano. Ciò dimostra che la variabilità nel significato delle parole non è solo casuale. La cultura gioca un ruolo importante nel plasmare le lingue, un'ipotesi che la teoria ha predetto da tempo, ma che i ricercatori non disponevano di dati quantitativi a supporto.
"Questo è un documento estremamente piacevole che fornisce una quantificazione di principio a questioni che sono state centrali nello studio della semantica lessicale, " ha detto Damián Blasi, uno scienziato del linguaggio all'Università di Harvard, che non era coinvolto nella nuova ricerca. Mentre il documento non fornisce una risposta definitiva per tutte le forze che modellano le differenze nel significato delle parole, i metodi stabiliti dagli autori sono validi, Blasi ha detto, e l'uso di più fonti di dati diverse "è un cambiamento positivo in un campo che ha sistematicamente ignorato il ruolo della cultura a favore di universali mentali o cognitivi".
Thompson ha convenuto che lui e le scoperte dei suoi colleghi enfatizzano il valore di "curare insiemi improbabili di dati che normalmente non si vedono nelle stesse circostanze". Gli algoritmi di apprendimento automatico utilizzati da lui e dai suoi colleghi sono stati originariamente formati da scienziati informatici, mentre i set di dati che hanno inserito nei modelli da analizzare sono stati creati da antropologi del XX secolo e da studi linguistici e psicologici più recenti. Come ha detto Thompson, "Dietro questi nuovi metodi fantasiosi, c'è un'intera storia di persone in più campi che raccolgono dati che stiamo mettendo insieme e guardando in un modo completamente nuovo".