L’osservazione delle singole cellule attraverso i microscopi può rivelare una serie di importanti fenomeni biologici cellulari che spesso svolgono un ruolo nelle malattie umane, ma il processo di distinzione delle singole cellule l’una dall’altra e il loro background è estremamente dispendioso in termini di tempo ed è un compito particolarmente adatto per l'assistenza dell'IA.
I modelli di intelligenza artificiale imparano come svolgere tali compiti utilizzando una serie di dati annotati dagli esseri umani, ma il processo di distinzione delle cellule dal loro sfondo, chiamato “segmentazione a cellula singola”, è lungo e laborioso. Di conseguenza, la quantità di dati annotati da utilizzare nei set di addestramento AI è limitata. I ricercatori dell'UC Santa Cruz hanno sviluppato un metodo per risolvere questo problema costruendo un modello AI di generazione di immagini al microscopio per creare immagini realistiche di singole cellule, che vengono poi utilizzate come "dati sintetici" per addestrare un modello AI per eseguire meglio la segmentazione delle singole cellule.
Il nuovo software è descritto in un nuovo articolo pubblicato sulla rivista iScience . Il progetto è stato guidato dal professore assistente di ingegneria biomolecolare Ali Shariati e dal suo studente laureato Abolfazl Zargari. Il modello, chiamato cGAN-Seg, è disponibile gratuitamente su GitHub.
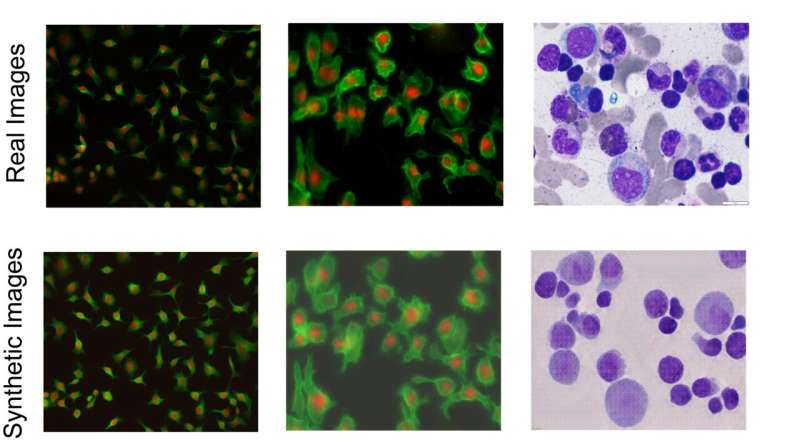
"Le immagini che escono dal nostro modello sono pronte per essere utilizzate per addestrare modelli di segmentazione", ha affermato Shariati. "In un certo senso stiamo facendo la microscopia senza microscopio, nel senso che siamo in grado di generare immagini molto vicine alle immagini reali delle cellule in termini di dettagli morfologici della singola cellula. Il bello è che quando escono del modello, sono già annotate ed etichettate. Le immagini mostrano moltissime somiglianze con le immagini reali, il che ci consente quindi di generare nuovi scenari che non sono stati visti dal nostro modello durante l'addestramento."
Le immagini di singole cellule viste al microscopio possono aiutare gli scienziati a conoscere il comportamento e le dinamiche delle cellule nel tempo, a migliorare il rilevamento delle malattie e a trovare nuovi farmaci. I dettagli subcellulari come la struttura possono aiutare i ricercatori a rispondere a domande importanti, ad esempio se una cellula è cancerosa o meno.
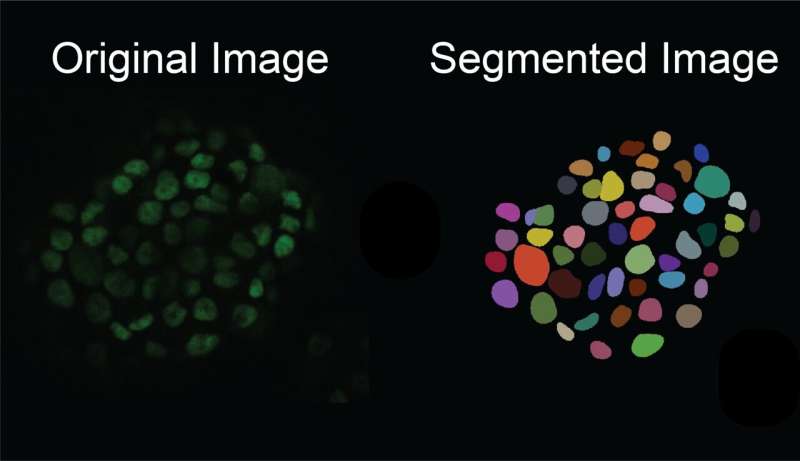
Tuttavia, trovare ed etichettare manualmente i confini delle cellule dal loro sfondo è estremamente difficile, soprattutto nei campioni di tessuto in cui sono presenti molte cellule in un'immagine. I ricercatori potrebbero impiegare diversi giorni per eseguire manualmente la segmentazione cellulare su sole 100 immagini al microscopio.
Il deep learning può accelerare questo processo, ma per addestrare i modelli è necessario un set di dati iniziale di immagini annotate:sono necessarie almeno migliaia di immagini come base per addestrare un modello di deep learning accurato. Anche se i ricercatori riescono a trovare e annotare 1.000 immagini, tali immagini potrebbero non contenere la variazione delle caratteristiche che appaiono nelle diverse condizioni sperimentali.
"Vuoi dimostrare che il tuo modello di deep learning funziona su diversi campioni con diversi tipi di cellule e diverse qualità di immagine", ha affermato Zargari. "Ad esempio, se addestri il tuo modello con immagini di alta qualità, non sarà in grado di segmentare le immagini di cellule di bassa qualità. Raramente riusciamo a trovare un set di dati così buono nel campo della microscopia."
Per risolvere questo problema, i ricercatori hanno creato un modello di intelligenza artificiale generativa da immagine a immagine che prende un insieme limitato di immagini cellulari annotate ed etichettate e ne genera altre, introducendo caratteristiche e strutture subcellulari più complesse e varie per creare un insieme diversificato di cellule "sintetiche" immagini. In particolare, possono generare immagini annotate con un’alta densità di cellule, che sono particolarmente difficili da annotare a mano e sono particolarmente rilevanti per lo studio dei tessuti. Questa tecnica funziona per elaborare e generare immagini di diversi tipi di cellule nonché diverse modalità di imaging, come quelle scattate utilizzando la fluorescenza o la colorazione istologica.
Zargari, che ha guidato lo sviluppo del modello generativo, ha utilizzato un algoritmo di intelligenza artificiale comunemente utilizzato chiamato "rete avversaria generativa del ciclo" per creare immagini realistiche. Il modello generativo è arricchito dalle cosiddette “funzioni di aumento” e da una “rete di iniezione di stile”, che aiuta il generatore a creare un’ampia varietà di immagini sintetiche di alta qualità che mostrano diverse possibilità di come potrebbero apparire le cellule. A conoscenza dei ricercatori, questa è la prima volta che le tecniche di iniezione vengono utilizzate in questo contesto.
Quindi, questo insieme diversificato di immagini sintetiche create dal generatore viene utilizzato per addestrare un modello a eseguire con precisione la segmentazione cellulare su nuove immagini reali scattate durante gli esperimenti.
"Utilizzando un set di dati limitato, possiamo addestrare un buon modello generativo. Utilizzando quel modello generativo, siamo in grado di generare un insieme più diversificato e più ampio di immagini sintetiche annotate. Utilizzando le immagini sintetiche generate possiamo addestrare un buon modello di segmentazione:questa è l'idea principale", ha detto Zagari.
I ricercatori hanno confrontato i risultati del loro modello utilizzando dati di addestramento sintetici con metodi più tradizionali di addestramento dell’intelligenza artificiale per eseguire la segmentazione cellulare tra diversi tipi di cellule. Hanno scoperto che il loro modello produce una segmentazione significativamente migliore rispetto ai modelli addestrati con dati di addestramento convenzionali e limitati. Ciò conferma ai ricercatori che fornire un set di dati più diversificato durante l'addestramento del modello di segmentazione migliora le prestazioni.
Attraverso queste capacità di segmentazione potenziate, i ricercatori saranno in grado di rilevare meglio le cellule e studiare la variabilità tra le singole cellule, in particolare tra le cellule staminali. In futuro, i ricercatori sperano di utilizzare la tecnologia che hanno sviluppato per andare oltre le immagini fisse e generare video, che possano aiutarli a individuare quali fattori influenzano il destino di una cellula nelle prime fasi della sua vita e a prevederne il futuro.
"Stiamo generando immagini sintetiche che possono anche essere trasformate in un film time lapse, dove possiamo generare il futuro invisibile delle cellule", ha detto Shariati. "Con questo, vogliamo vedere se siamo in grado di prevedere gli stati futuri di una cellula, ad esempio se la cellula crescerà, migrerà, si differenzierà o si dividerà."
Ulteriori informazioni: Abolfazl Zargari et al, Segmentazione cellulare migliorata con set di dati di addestramento limitati utilizzando reti avversarie generatrici di cicli, iScience (2024). DOI:10.1016/j.isci.2024.109740
Informazioni sul giornale: iScienza
Fornito dall'Università della California - Santa Cruz