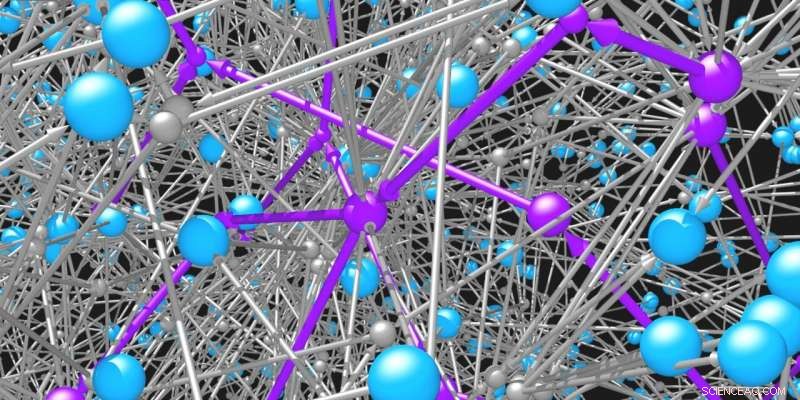
Le molecole (sfere blu) sono collegate tra loro dalle reazioni (sfere e frecce grigie) a cui partecipano. La rete di possibili molecole e reazioni organiche è incredibilmente vasta. Sono necessari algoritmi di ricerca intelligenti per identificare percorsi praticabili (viola) per sintetizzare le molecole desiderate. Credito:Mikolaj Kowalik &Kyle Bishop/Columbia Engineering
Ricercatori, dai biochimici agli scienziati dei materiali, hanno a lungo fatto affidamento sulla ricca varietà di molecole organiche per risolvere sfide urgenti. Alcune molecole possono essere utili nel trattamento di malattie, altri per illuminare i nostri display digitali, altri ancora per i pigmenti, vernici, e plastiche. Le proprietà uniche di ogni molecola sono determinate dalla sua struttura, cioè dalla connettività dei suoi atomi costituenti. Una volta individuata una struttura promettente, resta il difficile compito di realizzare la molecola mirata attraverso una sequenza di reazioni chimiche. Ma quali?
I chimici organici generalmente lavorano a ritroso dalla molecola bersaglio ai materiali di partenza utilizzando un processo chiamato analisi retrosintetica. Durante questo processo, il chimico deve affrontare una serie di decisioni complesse e interconnesse. Ad esempio, delle decine di migliaia di diverse reazioni chimiche, quale scegliere per creare la molecola target? Una volta presa tale decisione, potresti trovarti con più molecole reagenti necessarie per la reazione. Se queste molecole non sono disponibili per l'acquisto, allora come selezioni le reazioni appropriate per produrle? Scegliere in modo intelligente cosa fare in ogni fase di questo processo è fondamentale per navigare nell'enorme numero di percorsi possibili.
I ricercatori della Columbia Engineering hanno sviluppato una nuova tecnica basata sull'apprendimento per rinforzo che addestra un modello di rete neurale per selezionare correttamente la reazione "migliore" in ogni fase del processo retrosintetico. Questa forma di intelligenza artificiale fornisce un quadro per i ricercatori per progettare sintesi chimiche che ottimizzano gli obiettivi specificati dall'utente come il costo di sintesi, sicurezza, e sostenibilità. Il nuovo approccio, pubblicato il 31 maggio da Scienze Centrali ACS , ha più successo (di circa il 60%) rispetto alle strategie esistenti per risolvere questo impegnativo problema di ricerca.
"L'apprendimento per rinforzo ha creato giocatori al computer che sono molto più bravi degli umani a giocare a videogiochi complessi. Forse la retrosintesi non è diversa! Questo studio ci fa sperare che gli algoritmi di apprendimento per rinforzo saranno forse un giorno migliori dei giocatori umani al 'gioco' di retrosintesi, "dice Alán Aspuru-Guzik, professore di chimica e informatica all'Università di Toronto, che non era coinvolto nello studio.
Il team ha inquadrato la sfida della pianificazione retrosintetica come un gioco come gli scacchi e il Go, dove il numero combinatorio delle scelte possibili è astronomico e il valore di ciascuna scelta incerto fino a quando il piano di sintesi non è completato e il suo costo valutato. A differenza di studi precedenti che utilizzavano funzioni di punteggio euristico, semplici regole empiriche, per guidare la pianificazione retrosintetica, questo nuovo studio ha utilizzato tecniche di apprendimento per rinforzo per formulare giudizi basati sull'esperienza del modello neurale.
"Siamo i primi ad applicare l'apprendimento per rinforzo al problema dell'analisi retrosintetica, "dice Kyle Bishop, professore associato di ingegneria chimica. "Partendo da uno stato di completa ignoranza, dove il modello non sa assolutamente nulla di strategia e applica le reazioni in modo casuale, il modello può esercitarsi e esercitarsi finché non trova una strategia che supera un'euristica definita dall'uomo".
Nel loro studio, Il team di Bishop si è concentrato sull'utilizzo del numero di fasi di reazione come misurazione di ciò che rende un percorso sintetico "buono". Avevano il loro modello di apprendimento per rinforzo adattare la sua strategia con questo obiettivo in mente. Utilizzando l'esperienza simulata, il team ha addestrato la rete neurale del modello a stimare il costo o il valore di sintesi previsto di una determinata molecola in base a una rappresentazione della sua struttura molecolare.
Il team prevede di esplorare diversi obiettivi in futuro, ad esempio, addestrare il modello a minimizzare i costi piuttosto che il numero di reazioni, o per evitare molecole che potrebbero essere tossiche. I ricercatori stanno anche cercando di ridurre il numero di simulazioni necessarie affinché il modello impari la sua strategia, poiché il processo di formazione era piuttosto costoso dal punto di vista computazionale.
"Ci aspettiamo che il nostro gioco di retrosintesi seguirà presto la via degli scacchi e del Go, in cui gli algoritmi autodidatti superano costantemente gli esperti umani, " Vescovo osserva. "E noi accogliamo favorevolmente la concorrenza. Come con i programmi per computer per giocare a scacchi, la concorrenza è il motore per il miglioramento dello stato dell'arte, e speriamo che altri possano basarsi sul nostro lavoro per dimostrare prestazioni ancora migliori".
Lo studio è intitolato "Apprendimento della pianificazione retrosintetica attraverso l'esperienza simulata".