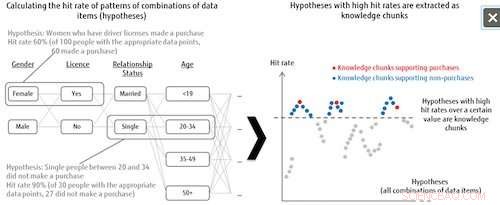
Figura 1:Elenco delle ipotesi ed estrazione di blocchi di conoscenza. Credito:Fujitsu
Fujitsu Laboratories Ltd. ha annunciato oggi lo sviluppo di "Wide Learning, " una tecnologia di apprendimento automatico in grado di esprimere giudizi accurati anche quando gli operatori non possono ottenere il volume di dati necessario per l'addestramento. L'intelligenza artificiale è ora spesso utilizzata per sfruttare i dati in una varietà di campi, ma l'accuratezza dell'IA può essere compromessa nei casi in cui il volume dei dati da analizzare è piccolo o sbilanciato. La tecnologia Wide Learning di Fujitsu consente di esprimere giudizi in modo più accurato di quanto fosse possibile in precedenza, e l'apprendimento è raggiunto in modo uniforme, indipendentemente dall'ipotesi esaminata, anche quando i dati sono sbilanciati. Lo fa estraendo prima ipotesi con un alto grado di importanza, dopo aver fatto un ampio insieme di ipotesi formato da tutte le combinazioni di elementi di dati, e quindi controllando il grado di impatto di ciascuna rispettiva ipotesi in base alle relazioni di sovrapposizione delle ipotesi. Inoltre, perché le ipotesi sono registrate come espressioni logiche, gli esseri umani possono anche comprendere il ragionamento alla base di un giudizio. La nuova tecnologia Wide Learning di Fujitsu consente l'utilizzo dell'intelligenza artificiale anche in aree quali sanità e marketing, dove i dati necessari per esprimere giudizi sono scarsi, supportare le operazioni e promuovere l'automazione dei processi di lavoro utilizzando l'intelligenza artificiale.
Negli ultimi anni, La tecnologia AI ha iniziato ad essere utilizzata in una varietà di campi, compresa l'assistenza sanitaria, marketing, e finanza. Sono in aumento le aspettative per l'uso del processo decisionale dell'IA a supporto delle operazioni e per l'automazione dei compiti in queste aree. Una sfida che resta per realizzare il potenziale di queste tecnologie, però, è che i dati potrebbero essere sbilanciati. Nello specifico, a seconda del settore può essere difficile ottenere dati sufficienti per addestrare l'IA sugli obiettivi su cui deve esprimere giudizi. Questo, in effetti, lascia molte di queste tecnologie incapaci di produrre risultati con sufficiente precisione per l'uso pratico. Per di più, uno dei motivi principali per cui l'implementazione dell'IA manca di progressi è che anche quando un'IA fornisce prestazioni di riconoscimento o classificazione sufficientemente accurate, gli esperti e persino gli stessi sviluppatori spesso non riescono a spiegare perché l'IA abbia prodotto una certa risposta, e se non possono adempiere alla loro responsabilità di spiegare i risultati alle prime linee dell'industria, allora l'IA non può essere impiegata.
Le tecnologie di intelligenza artificiale basate sul deep learning formulano convenzionalmente giudizi molto accurati essendo addestrate su grandi volumi di dati, compresi ampi dati di destinazione per essere giudicati. Negli scenari del mondo reale, però, ci sono molti casi in cui i dati sono insufficienti, con pochissimi dati di destinazione. In questi casi, di fronte a dati sconosciuti, diventa difficile per la tecnologia AI fornire giudizi altamente accurati. Inoltre, il modello di apprendimento automatico per l'IA esistente basato sul deep learning è un modello di scatola nera che non può spiegare le ragioni alla base dei giudizi espressi dall'IA, creando un problema con la trasparenza. Come tale, andando avanti sarà necessario sviluppare una nuova tecnologia di intelligenza artificiale che realizzi giudizi altamente accurati da dati sbilanciati, e questo è anche trasparente per risolvere vari problemi nella società.
Tenendo presenti queste sfide, Fujitsu Laboratories ha ora sviluppato Wide Learning, una tecnologia di machine learning in grado di dare giudizi molto accurati anche nei casi in cui i dati sono sbilanciati. Le caratteristiche della tecnologia Wide Learning includono i seguenti due punti.
1. Crea combinazioni di elementi di dati per estrarre grandi volumi di ipotesi
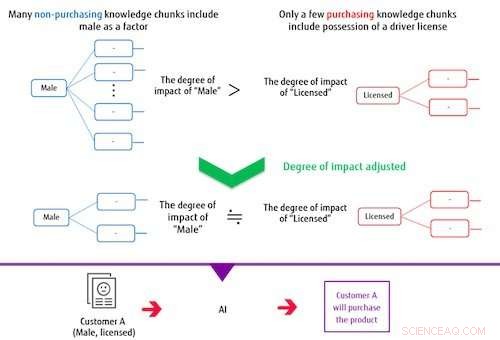
Figura 2:Quando si crea un modello di classificazione, i blocchi di conoscenza influiscono sulla regolazione. Credito:Fujitsu
Questa tecnologia tratta tutti i modelli di combinazione di elementi di dati come ipotesi, e quindi determina il grado di importanza di ciascuna ipotesi in base al tasso di successo per la categoria dell'etichetta. Per esempio, quando si analizzano le tendenze di chi acquista determinati prodotti, il sistema combina tutti i tipi di modelli dagli elementi di dati per coloro che hanno o non hanno effettuato acquisti (l'etichetta della categoria), come le donne single tra i 20 e i 34 anni che hanno la patente di guida, e poi analizza quanti hit ottiene nei dati di chi ha effettivamente effettuato acquisti quando si prendono come ipotesi questi schemi di combinazione. Le ipotesi che raggiungono un hit rate al di sopra di un certo livello sono definite ipotesi importanti, chiamati "pezzi di conoscenza". Ciò significa che anche quando i dati di destinazione sono insufficienti, il sistema può estrarre tutte le ipotesi che vale la pena esaminare, che può anche contribuire alla scoperta di spiegazioni precedentemente non considerate.
2. Regola il grado di impatto dei blocchi di conoscenza per costruire un modello di classificazione accurato
Il sistema costruisce un modello di classificazione basato su più blocchi di conoscenza estratti e sull'etichetta di destinazione. In questo processo, se gli elementi che costituiscono un blocco di conoscenza si sovrappongono frequentemente agli elementi che costituiscono altri blocchi di conoscenza, il sistema controlla il loro grado di impatto in modo da ridurre il peso della loro influenza sul modello di classificazione. In questo modo, il sistema può addestrare un modello capace di classificazioni accurate anche quando l'etichetta di destinazione oi dati contrassegnati come corretti sono sbilanciati. Per esempio, in un caso in cui gli uomini che non hanno effettuato un acquisto costituiscono la stragrande maggioranza di un set di dati di acquisto di articoli, se l'IA viene addestrata senza controllare il grado di impatto, quindi il pezzo di conoscenza che include se una persona ha o meno una licenza, indipendente dal genere, non avrà molta influenza sulla classificazione. Con questo metodo di nuova concezione, il grado di impatto dei blocchi di conoscenza che includono il fattore maschile è limitato a causa della sovrapposizione di questo elemento, mentre l'impatto del minor numero di blocchi di conoscenza che includono se una persona ha una licenza diventa relativamente maggiore nella formazione, costruire un modello in grado di categorizzare correttamente sia gli uomini che il possesso di una licenza.
I laboratori Fujitsu hanno condotto una prova di questa tecnologia, applicandolo ai dati in aree come il marketing digitale e la sanità. In un test utilizzando i dati di riferimento nelle aree marketing e sanità dall'UC Irvine Machine Learning Repository, questa tecnologia ha migliorato la precisione di circa il 10-20% rispetto al deep learning. Ha ridotto con successo di circa il 20-50% la probabilità che il sistema trascuri i clienti che potrebbero abbonarsi a un servizio o i pazienti con una condizione. Nei dati di marketing, dei circa 5, 000 voci di dati del cliente utilizzate nel test, solo circa 230 erano per l'acquisto di clienti, creando un insieme sbilanciato. Questa tecnologia ha ridotto il numero di potenziali clienti esclusi dalle promozioni di vendita da 120, il risultato di analisi di deep learning, a 74. Inoltre, poiché i blocchi di conoscenza che costituiscono la base di questa tecnologia hanno un formato di espressione logica, la capacità di spiegare il ragionamento alla base di un giudizio è utile anche per implementare questa tecnologia nella società. Anche quando si determina che sono necessarie correzioni a un modello, sulla base dei risultati di nuovi dati, è possibile effettuare revisioni più opportune, perché gli utenti possono capire le ragioni dei risultati.
I laboratori Fujitsu continueranno ad applicare questa tecnologia a compiti che richiedono il ragionamento alla base dei giudizi dell'IA, come nelle transazioni finanziarie e nelle diagnosi mediche, e a compiti che gestiscono fenomeni a bassa frequenza, come frodi e guasti alle apparecchiature, con l'obiettivo di commercializzarlo come una nuova tecnologia di apprendimento automatico a supporto di Fujitsu Human Centric AI Zinrai di Fujitsu Limited nell'anno fiscale 2019. Fujitsu Laboratories farà anche un uso efficace della caratteristica capacità di spiegazione di questa tecnologia, continua ricerca e sviluppo su argomenti come un migliore supporto per esprimere giudizi e decisioni nei compiti a cui è applicato, e nella progettazione complessiva del sistema, compresa la collaborazione con gli esseri umani.