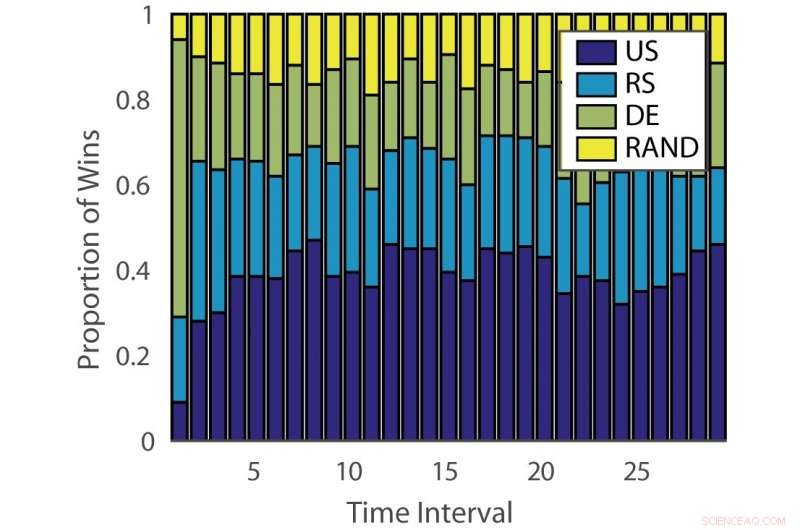
Percentuale di vittorie:“ILPD”. Credito:Pang et al.
Ricercatori dell'Università di Edimburgo, L'University College London (UCL) e il Nara Institute of Science and Technology hanno sviluppato un nuovo approccio di apprendimento attivo d'insieme basato su un bandito multi-braccio non stazionario e un algoritmo di consulenza di esperti. Il loro metodo, presentato in un articolo pre-pubblicato su arXiv, potrebbe ridurre il tempo e gli sforzi investiti nell'annotazione manuale dei dati.
"L'apprendimento automatico supervisionato convenzionale è affamato di dati, e i dati etichettati possono essere un collo di bottiglia quando l'annotazione dei dati è costosa, "Timothy Hospedales, uno dei ricercatori che hanno condotto lo studio ha detto a Tech Xplore. "L'apprendimento attivo supporta l'apprendimento supervisionato prevedendo i punti dati più informativi da annotare in modo che i modelli validi possano essere addestrati con un budget di annotazione ridotto".
L'apprendimento attivo è una particolare area dell'apprendimento automatico in cui un algoritmo di apprendimento può scegliere attivamente i dati da cui desidera apprendere. Ciò si traduce in genere in prestazioni migliori, con set di dati di addestramento significativamente più piccoli.
I ricercatori hanno sviluppato una varietà di algoritmi di apprendimento attivo che potrebbero ridurre i costi di annotazione, ma così lontano, nessuna di queste soluzioni si è rivelata efficace per tutti i problemi. Altri studi hanno quindi utilizzato algoritmi banditi per identificare il miglior algoritmo di apprendimento attivo per un determinato set di dati.
"Il termine 'bandito' si riferisce a una slot machine bandito multi-braccio, che è una comoda astrazione matematica per problemi di esplorazione/sfruttamento, " Ha spiegato Hospedales. "Un algoritmo bandito trova un buon equilibrio tra lo sforzo speso per esplorare tutte le slot machine per scoprire quale sta pagando di più, con lo sforzo speso per sfruttare la migliore slot machine trovata finora."
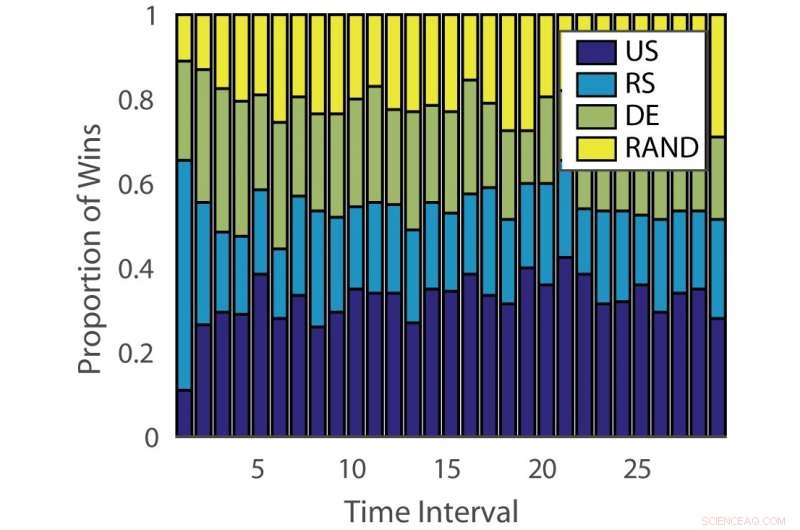
Percentuale di vittorie:“tedesco”. Credito:Pang et al.
L'efficacia degli algoritmi di apprendimento attivo varia sia a seconda dei problemi che nel tempo nelle diverse fasi dell'apprendimento. Questa osservazione è analoga al gioco delle slot machine, dove la probabilità di vincita cambia nel tempo.
"Lo scopo del nostro studio era sviluppare un nuovo algoritmo bandito che migliora le prestazioni tenendo conto di questo aspetto del problema dell'apprendimento attivo, " disse Hospedales.
Per ovviare a questa limitazione, i ricercatori hanno proposto un discente attivo di ensemble dinamico (DEAL) basato su un bandito non stazionario. Questo studente costruisce una stima dell'efficacia di ogni algoritmo di apprendimento attivo online, in base alla ricompensa (accuratezza ponderata in base all'importanza) ottenuta dopo ogni annotazione dei dati.
"Lo fa utilizzando la preferenza espressa per quel punto da ciascun algoritmo di apprendimento attivo, "Kunkun Pang, un altro ricercatore che ha condotto lo studio, ha detto a Tech Xplore. "Per affrontare il problema della mutevole efficacia dei discenti attivi nel tempo, riavviamo periodicamente l'algoritmo di apprendimento per aggiornare la sua preferenza di studente attivo. Con questa capacità, se l'algoritmo di apprendimento attivo più efficace cambia tra le fasi iniziali e tardive dell'apprendimento, possiamo adattarci rapidamente a questo cambiamento".
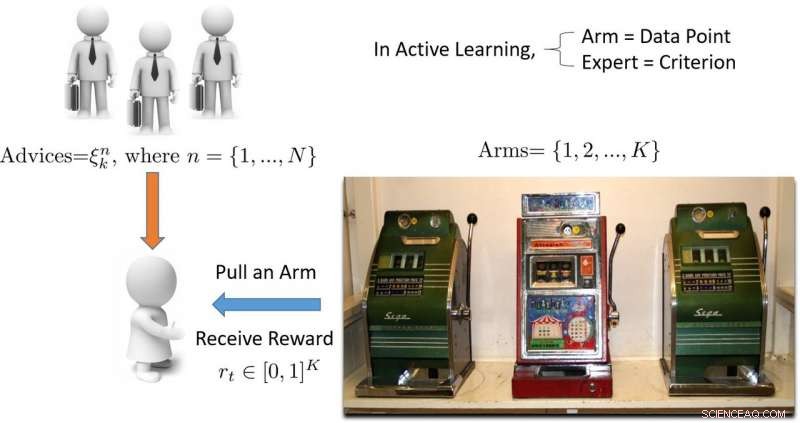
Illustrazione di un approccio di apprendimento attivo basato su banditi multi-armati. Credito:Pang et al.
I ricercatori hanno testato il loro approccio su 13 set di dati popolari, ottenendo risultati altamente incoraggianti. Il loro algoritmo DEAL ha una garanzia di prestazioni matematiche, il che significa che c'è un alto grado di fiducia nel modo in cui funzionerà.
"La garanzia riguarda le prestazioni del nostro algoritmo, che è quella di un oracolo ideale che conosce sempre la scelta giusta per lo studente attivo, " Ha spiegato Hospedales. "Fornisce un limite al divario di prestazioni tra un algoritmo del genere e il nostro".
La valutazione empirica effettuata da Hospedales e dai suoi colleghi ha confermato che il loro algoritmo DEAL migliora le prestazioni di apprendimento attivo su una suite di benchmark. Lo fa identificando continuamente l'algoritmo di apprendimento attivo più efficace per diversi compiti e in diverse fasi della formazione.
"Oggi, mentre l'apprendimento attivo è attraente, il suo impatto sulle pratiche di apprendimento automatico è limitato a causa del fastidio di abbinare gli algoritmi ai problemi e alle fasi di apprendimento, " Hospedales ha detto. "DEAL elimina questa difficoltà e fornisce un approccio per affrontare molti problemi e tutte le fasi di apprendimento. Rendendo l'apprendimento attivo più facile da usare, speriamo che possa avere un impatto maggiore sulla riduzione dei costi di annotazione nella pratica del machine learning."
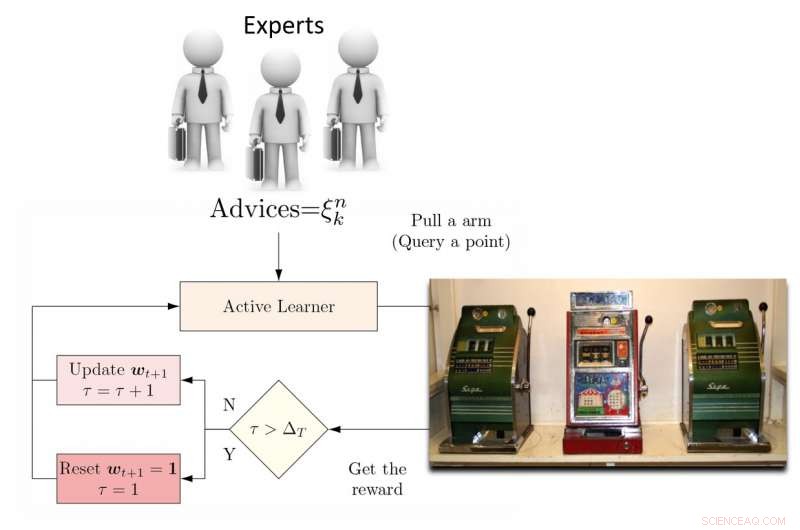
Illustrazione dell'algoritmo DEAL REXP4. Credito:Pang et al.
Nonostante i risultati molto promettenti, la tecnica ideata dai ricercatori ha ancora un notevole limite. DEAL fa tutto l'apprendimento all'interno di un singolo problema e questo si traduce in un "avvio a freddo, ' significa che l'algoritmo affronta tutti i nuovi problemi con una tabula rasa.
"Nei lavori in corso, stiamo imparando come annotare su molti problemi diversi e alla fine trasferire questa conoscenza a un nuovo problema, per eseguire immediatamente un'annotazione efficace senza requisiti di riscaldamento, " Ha detto Pang. "Il nostro lavoro preliminare su questo argomento è stato pubblicato e ha anche vinto il premio Best Paper al workshop AutoML di ICML 2018".
© 2018 Science X Network














