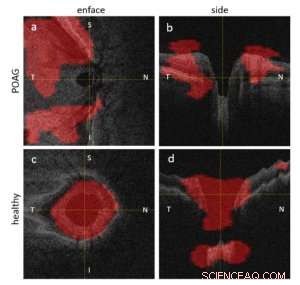
Figura 1:Visualizzazione delle regioni rilevate dalla rete in un occhio glaucomatoso (riga superiore) e sano (riga inferiore). Credito:IBM
Il glaucoma è la seconda causa di cecità nel mondo, che colpisce circa 2,7 milioni di persone nei soli Stati Uniti. È un insieme complesso di malattie e, se non trattata, può portare alla cecità. È un problema particolarmente grande in Australia, dove solo il 50 percento di tutte le persone che ne soffrono viene effettivamente diagnosticato e riceve il trattamento di cui ha bisogno.
Come parte di un team di scienziati dell'IBM e della New York University, io e i miei colleghi stiamo esaminando nuovi modi in cui l'intelligenza artificiale potrebbe essere utilizzata per aiutare gli oftalmologi e gli optometristi a utilizzare ulteriormente le immagini degli occhi, e potenzialmente aiutano ad accelerare il processo di rilevamento del glaucoma nelle immagini. In un recente documento, descriviamo in dettaglio un nuovo framework di deep learning che rileva il glaucoma direttamente dall'imaging tomografico a coerenza ottica (OCT) grezzo, un metodo che utilizza le onde luminose per acquisire immagini in sezione trasversale della retina. Questo metodo ha raggiunto un tasso di precisione del 94 percento, senza alcuna ulteriore segmentazione o pulizia dei dati, che di solito richiede tempo.
Attualmente, il glaucoma viene diagnosticato utilizzando una varietà di test, come misurazioni della pressione intraoculare e test del campo visivo, così come l'imaging del fondo e dell'OCT. L'OCT fornisce un modo efficiente per visualizzare e quantificare le strutture nell'occhio, vale a dire lo strato di fibre nervose retiniche (RNFL), che cambia con la progressione della malattia.
Sebbene questo approccio funzioni bene, richiede un processo aggiuntivo per quantificare l'RNFL nelle immagini OCT. Queste tecniche in genere puliscono anche i dati di input in vari modi, come capovolgere tutti gli occhi nello stesso orientamento (sinistra o destra) al fine di ridurre la variabilità dei dati per migliorare le prestazioni dei classificatori. Il nostro approccio rimuove questi passaggi aggiuntivi, indicando che queste fasi potenzialmente lunghe non sono necessarie per la rilevazione del glaucoma.
In definitiva, quando normalizzato da un tasso di falsi positivi, in una coorte di 624 soggetti (217 sani e 432 pazienti con glaucoma), il nostro nuovo approccio, fondata sull'apprendimento profondo, rileva correttamente gli occhi glaucomatosi nel 94 percento dei casi, mentre le tecniche menzionate in precedenza lo hanno trovato solo nell'86 percento dei casi. Riteniamo che questa maggiore precisione sia il risultato dell'eliminazione degli errori nella segmentazione automatizzata delle strutture nelle immagini e dell'inclusione di regioni dell'immagine che non sono attualmente utilizzate clinicamente per questo scopo.
Inoltre, contrariamente all'attuale tendenza nella ricerca sull'intelligenza artificiale che utilizza reti più grandi e più profonde, la rete che abbiamo usato era una piccola rete a 5 livelli perché i dati medici non sono facilmente accessibili a causa della loro natura riservata. Questa scarsità di dati rende impraticabile l'uso di reti di grandi dimensioni in molte applicazioni mediche. Anche nella ricerca, a volte vediamo che "less is more, " e l'addestramento di questi algoritmi su reti più piccole consente loro di funzionare con maggiore efficienza.
Questo è solo un aspetto della nostra ricerca nell'applicazione dell'intelligenza artificiale per l'occhio. In una nuova collaborazione recentemente annunciata, IBM Research e George &Matilda (G&M) sfrutteranno il solido set di dati di G&M di dati clinici anonimi e studi di imaging per esplorare metodi per utilizzare modelli di deep learning e analisi di imaging per supportare i medici nell'identificazione e nel rilevamento di malattie dell'occhio, incluso il glaucoma, nelle immagini . I ricercatori cercheranno anche di studiare i potenziali biomarcatori del glaucoma, che potrebbe aiutare a comprendere meglio la progressione della malattia.
Questa storia è stata ripubblicata per gentile concessione di IBM Research. Leggi la storia originale qui.