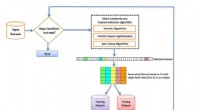
Visualizzazione che rappresenta la codifica fonetica delle iniziali Pinyin. Credito:IBM
Eseguendo la ginnastica mentale per fare la distinzione fenetica tra parole e frasi come "Sento" a "Sono qui" o "Non posso così ma tonnellate" a "Non riesco a cucire bottoni, " è familiare a chiunque abbia riscontrato messaggi di testo con correzione automatica, post sui social media e simili. Sebbene a prima vista possa sembrare che la somiglianza fonetica possa essere quantificata solo per le parole udibili, questo problema è spesso presente negli spazi puramente testuali.
Gli approcci di intelligenza artificiale per l'analisi e la comprensione del testo richiedono un input pulito, che a sua volta implica una necessaria quantità di pre-elaborazione dei dati grezzi. Omofoni e sinofoni errati, se usato per errore o per scherzo, deve essere corretto come qualsiasi altra forma di errore di ortografia o grammatica. Nell'esempio sopra, trasformare accuratamente le parole "sentire" e "così" nelle loro controparti corrette foneticamente simili richiede una rappresentazione robusta della somiglianza fonetica tra coppie di parole.
La maggior parte degli algoritmi per la somiglianza fonetica sono motivati da casi d'uso inglesi, e progettato per le lingue indoeuropee. Però, molte lingue, come cinese, hanno una struttura fonetica diversa. Il suono del parlato di un carattere cinese è rappresentato da una singola sillaba in Pinyin, il sistema ufficiale di romanizzazione dei cinesi. Una sillaba Pinyin è composta da:un'iniziale (opzionale) (come 'b', 'z', o 'x'), un finale (come 'a', 'tu', 'aspetta', o 'yuan') e tono (di cui ce ne sono cinque). La mappatura di questi suoni del parlato ai fonemi inglesi risulta in una rappresentazione abbastanza imprecisa, e l'utilizzo di algoritmi di somiglianza fonetica indoeuropea aggrava ulteriormente il problema. Per esempio, due noti algoritmi, Soundex e doppio metafono, indice le consonanti ignorando le vocali (e non hanno il concetto di toni).
pinyin
Poiché una sillaba Pinyin rappresenta una media di sette diversi caratteri cinesi, la preponderanza degli omofoni è addirittura maggiore che in inglese. Nel frattempo, l'uso di Pinyin per la creazione di testi è estremamente diffuso nelle applicazioni mobili e di chat, sia quando si utilizza la sintesi vocale che quando si digita direttamente, poiché è più pratico inserire una sillaba Pinyin e selezionare il carattere desiderato. Di conseguenza, gli errori di input basati sulla fonetica sono estremamente comuni, evidenziando la necessità di un algoritmo di somiglianza fonetica molto accurato su cui si possa fare affidamento per correggere gli errori.
Motivato da questo caso d'uso, che si generalizza a molte altre lingue che non si adattano facilmente allo stampo fonetico dell'inglese, abbiamo sviluppato un approccio per l'apprendimento di una codifica fonetica n-dimensionale per il cinese, Una caratteristica importante di Pinyin è che le tre componenti di una sillaba (iniziale, finale e tono) dovrebbero essere considerati e confrontati indipendentemente. Per esempio, la somiglianza fonetica delle finali "ie" e "ue" è identica nelle coppie Pinyin {"xie2, " "xue2"} e {"lie2, " "lue2"}, nonostante le iniziali diverse. Così, la somiglianza di una coppia di sillabe Pinyin è un'aggregazione delle somiglianze tra le loro iniziali, finale, e toni.
Però, vincolando artificialmente lo spazio di codifica a una dimensione bassa (ad es. indicizzando ogni iniziale a una singola categoriale, o anche valore numerico) limita l'accuratezza di catturare le variazioni fonetiche. Il corretto, L'approccio data-driven è quindi quello di apprendere organicamente una codifica di dimensionalità appropriata. Il modello di apprendimento deriva codifiche accurate considerando congiuntamente le caratteristiche linguistiche Pinyin, come luogo di articolazione e metodi di pronuncia, così come set di dati di allenamento annotati di alta qualità.
Dimostrazione di un miglioramento di 7,5 volte rispetto agli approcci di somiglianza fonetica esistenti
Le codifiche apprese possono quindi essere utilizzate per, Per esempio, accetta una parola come input e restituisce un elenco ordinato di parole foneticamente simili (classificate per somiglianza fonetica decrescente). La classifica è importante perché le applicazioni a valle non si ridimensionano per considerare un gran numero di candidati sostitutivi per ogni parola, soprattutto durante l'esecuzione in tempo reale. Come esempio del mondo reale, abbiamo valutato il nostro approccio per generare una graduatoria di candidati per ciascuna delle 350 parole cinesi prese da un set di dati di social media, e ha dimostrato un miglioramento di 7,5 volte rispetto agli approcci di somiglianza fonetica esistenti.
Ci auguriamo che i miglioramenti apportati da questo lavoro per rappresentare la somiglianza fonetica specifica della lingua contribuiscano alla qualità di numerose applicazioni di elaborazione del linguaggio naturale multilingue. Questo lavoro, parte del progetto IBM Research SystemT, è stato recentemente presentato alla conferenza SIGNLL 2018 sull'apprendimento computazionale del linguaggio naturale, e il modello cinese pre-addestrato è disponibile per i ricercatori da utilizzare come risorsa nella creazione di chatbot, app di messaggistica, correttori ortografici e qualsiasi altra applicazione pertinente.