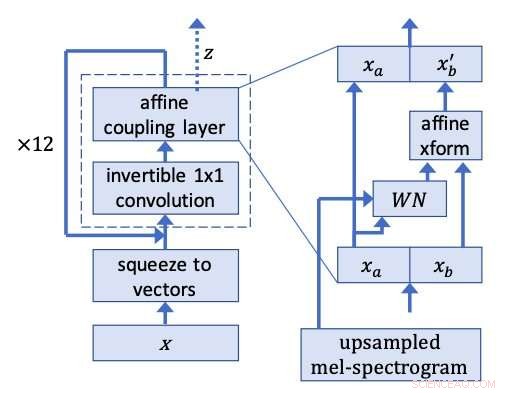
Rete WaveGlow. Credito:Prenger, Valle, e Catanzaro.
Un team di ricercatori di NVIDIA ha recentemente sviluppato WaveGlow, una rete basata sul flusso in grado di generare discorsi di alta qualità da spettrogrammi melometrici, che sono rappresentazioni acustiche tempo-frequenza del suono. Il loro metodo, delineato in un documento pre-pubblicato su arXiv, utilizza un'unica rete addestrata con un'unica funzione di costo, rendendo la procedura di formazione più facile e più stabile.
"La maggior parte delle reti neurali per la sintesi del discorso erano troppo lente per noi, "Ryan Prenger, uno dei ricercatori che ha condotto lo studio, ha detto a TechXplore. "Erano limitati in velocità perché erano progettati per generare un solo campione alla volta. Le eccezioni erano gli approcci di Google e Baidu che generavano audio molto rapidamente in parallelo. Tuttavia, questi approcci utilizzavano reti di insegnanti e reti di studenti ed erano troppo complessi per essere replicati".
I ricercatori hanno tratto ispirazione da Glow, una rete basata sul flusso di OpenAI in grado di generare immagini di alta qualità in parallelo, mantenendo una struttura abbastanza semplice. Utilizzando una convoluzione 1x1 invertibile, Glow ha ottenuto risultati notevoli, produrre immagini altamente realistiche. I ricercatori hanno deciso di applicare la stessa idea alla base di questo metodo alla sintesi vocale.
"Pensa al rumore bianco che proviene da una radio non impostata su nessuna stazione, " Ha spiegato Prenger. Quel rumore bianco è facilissimo da generare. L'idea di base della sintesi vocale con WaveGlow è addestrare una rete neurale per trasformare quel rumore bianco in voce. Se usi una vecchia rete neurale, la formazione sarà problematica. Ma se usi specificamente una rete che può essere eseguita sia all'indietro che in avanti, la matematica diventa facile e alcuni dei problemi di formazione scompaiono."
I ricercatori hanno eseguito all'indietro clip vocali dal set di dati di allenamento, addestrando WaveGlow a produrre ciò che assomiglia molto al rumore bianco. Il loro modello applica la stessa idea alla base di Glow a un'architettura simile a WaveNet, da qui il nome WaveGlow.
In un'implementazione PyTorch, WaveGlow ha prodotto campioni audio a una velocità di oltre 500kHz, su una GPU NVIDIA V100. I test del punteggio di opinione media (MOS) di crowdsourcing su Amazon Mechanical Turk suggeriscono che l'approccio offre una qualità audio pari a quella del miglior metodo WaveNet disponibile pubblicamente.
"Nel mondo della sintesi vocale, c'è bisogno di modelli che generino il parlato più di un ordine di grandezza più velocemente in tempo reale, " Prenger ha detto. "Speriamo che WaveGlow possa soddisfare questa esigenza pur essendo più facile da implementare e mantenere rispetto ad altri modelli esistenti. Nel mondo del deep learning, pensiamo che questo tipo di approccio che utilizza una rete neurale invertibile e la risultante semplice funzione di perdita sia relativamente poco studiato. WaveGlow fornisce un altro esempio di come questo approccio possa fornire risultati generativi di alta qualità nonostante la sua relativa semplicità."
Il codice di WaveGlow è prontamente disponibile online e può essere consultato da altri che desiderano provarlo o sperimentarlo. Nel frattempo, i ricercatori stanno lavorando per migliorare la qualità delle clip audio sintetizzate mettendo a punto il loro modello ed effettuando ulteriori valutazioni.
"Non abbiamo fatto molte analisi per vedere quanto piccola di una rete possiamo farla franca, " Prenger ha detto. "La maggior parte delle nostre decisioni sull'architettura si basava su parti molto precoci della formazione. Però, reti più piccole con tempi di addestramento più lunghi potrebbero generare un suono altrettanto buono. Ci sono molte direzioni interessanti che questa ricerca potrebbe prendere in futuro".
© 2018 Science X Network