Credito:KTH The Royal Institute of Technology
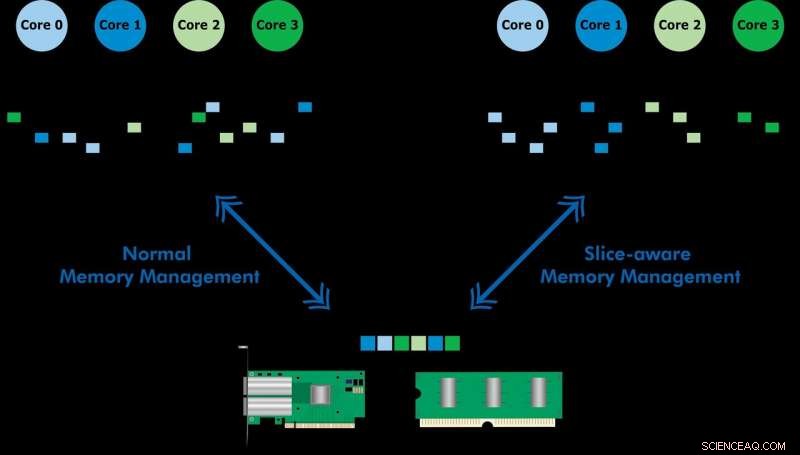
Sviluppato con Ericsson Research, lo schema di gestione della memoria con riconoscimento delle sezioni consente di accedere più rapidamente ai dati utilizzati di frequente tramite la cache di memoria di ultimo livello (LLC) di una CPU Intel Xeon. Stabilendo un archivio di valori-chiave e allocando la memoria in modo che sia mappata alla slice LLC più appropriata, hanno dimostrato sia l'elaborazione dei pacchetti ad alta velocità che le prestazioni migliorate di un archivio chiave-valore. Il team ha utilizzato lo schema proposto per implementare uno strumento chiamato CacheDirector, che rende il Data Direct I/O (DDIO) sensibile allo slice e ha pubblicato un documento di conferenza, Ottieni il massimo dalla cache di ultimo livello nei processori Intel, che è stato presentato a EuroSys 2019 in primavera.
"Al momento, un server che riceve pacchetti da 64 byte a 100 Gbps ha solo 5,12 nanosecondi per elaborare ogni pacchetto prima che arrivi il successivo, ", afferma il co-autore Alireza Farshin, uno studente di dottorato presso il Network Systems Laboratory di KTH. Ma se i dati vengono instradati alla sezione di cache corretta nella CPU, è possibile accedervi più velocemente, consentendo un'elaborazione più rapida di più pacchetti, in meno di 5 nanosecondi.
Data Direct I/O (DDIO) invia pacchetti a fette casuali, che è tutt'altro che efficiente. Data l'odierna architettura della cache non uniforme (NUCA), la soluzione di gestione della cache è inestimabile, dice il professor Dejan Kostic del KTH, che ha condotto la ricerca.
"In combinazione con l'introduzione dell'headroom dinamico nel Data Plane Development Kit (DPDK), l'intestazione del pacchetto può essere collocata nella fetta della LLC più vicina al relativo core di elaborazione. Di conseguenza, il core può accedere ai pacchetti più velocemente riducendo anche i tempi di attesa, " lui dice.
"Il nostro lavoro dimostra che sfruttare i miglioramenti in nanosecondi della latenza può avere un grande impatto sulle prestazioni delle applicazioni in esecuzione su sistemi informatici già altamente ottimizzati, " Dice Farshin. Il team ha scoperto che per una CPU che funziona a 3,2 GHz, CacheDirector può salvare fino a circa 20 cicli per accesso alla LLC che ammonta a 6,25 nanosecondi. Ciò accelera l'elaborazione dei pacchetti e riduce le latenze di coda delle catene di servizi di virtualizzazione delle funzioni di rete ottimizzate (NFV) in esecuzione a 100 Gbps fino al 21,5%.