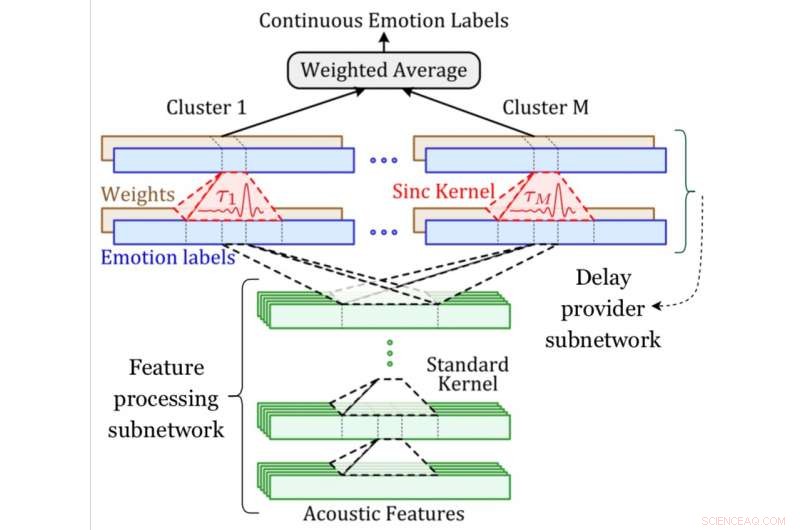
Un diagramma di sistema della rete MDS. Attestazione:Khorram, McInnis e Prevosto.
I modelli di apprendimento automatico in grado di riconoscere e prevedere le emozioni umane sono diventati sempre più popolari negli ultimi anni. Affinché la maggior parte di queste tecniche funzioni bene, però, i dati utilizzati per addestrarli vengono prima annotati da soggetti umani. Inoltre, le emozioni cambiano continuamente nel tempo, che rende particolarmente impegnativa l'annotazione di video o registrazioni vocali, spesso con conseguenti discrepanze tra etichette e registrazioni.
Per ovviare a questa limitazione, i ricercatori dell'Università del Michigan hanno recentemente sviluppato una nuova rete neurale convoluzionale in grado di allineare e prevedere simultaneamente le annotazioni delle emozioni in modo end-to-end. Hanno presentato la loro tecnica, chiamata rete MDS (multi-delay sync), in un articolo pubblicato su Transazioni IEEE su Affective Computing .
"L'emozione varia continuamente nel tempo; fluisce e rifluisce nelle nostre conversazioni" Emily Mower Provost, uno dei ricercatori che ha condotto lo studio, ha detto a TechXplore. "In ingegneria, spesso usiamo descrizioni continue delle emozioni per misurare come varia l'emozione. Il nostro obiettivo diventa quindi prevedere queste misure continue dal discorso. Ma c'è un problema. Una delle maggiori sfide nel lavorare con descrizioni continue delle emozioni è che richiede etichette che variano continuamente nel tempo. Questo viene fatto da squadre di annotatori umani. Però, le persone non sono macchine."
Come Mower Provost continua a spiegare, gli annotatori umani a volte possono essere più in sintonia con particolari segnali emotivi (ad es. risata), ma perdere il significato dietro altri segnali (ad esempio, un sospiro esasperato). In aggiunta a questo, gli esseri umani possono impiegare del tempo per elaborare una registrazione, e quindi, le loro reazioni agli stimoli emotivi a volte sono ritardate. Di conseguenza, le etichette delle emozioni continue possono presentare molte variazioni e talvolta sono disallineate con il parlato nei dati.
Nel loro studio, Mower Provost e i suoi colleghi hanno affrontato direttamente queste sfide, concentrandosi su due misure continue dell'emozione:positività (valenza) ed energia (attivazione/eccitazione). Hanno introdotto la rete di sincronizzazione multi-ritardo, un nuovo metodo per gestire il disallineamento tra il parlato e le annotazioni continue che reagisce in modo diverso ai diversi tipi di segnali acustici.
"Descrizioni dimensionali tempo-continue delle emozioni (ad es. Risveglio, valenza) forniscono informazioni dettagliate sia sui cambiamenti a breve termine che sulle tendenze a lungo termine nell'espressione delle emozioni, "Soheil Khorram, un altro ricercatore coinvolto nello studio, ha detto a TechXplore. "L'obiettivo principale del nostro studio era sviluppare un sistema di riconoscimento automatico delle emozioni in grado di stimare le emozioni dimensionali continue nel tempo dai segnali vocali. Questo sistema potrebbe avere una serie di applicazioni del mondo reale in diversi campi tra cui l'interazione uomo-computer, e-learning, marketing, assistenza sanitaria, divertimento e legge».
La rete convoluzionale sviluppata da Mower Provost, Khorram e i loro colleghi ha due componenti chiave, uno per la previsione delle emozioni e uno per l'allineamento. Il componente di previsione delle emozioni è un'architettura convoluzionale comune addestrata per identificare la relazione tra le caratteristiche acustiche e le etichette delle emozioni.
La componente di allineamento, d'altra parte, è il nuovo livello introdotto dai ricercatori (ovvero il livello di sincronizzazione ritardata), che applica un time-shift apprendibile a un segnale acustico. I ricercatori hanno compensato la variazione dei ritardi incorporando diversi di questi strati.
"Una sfida importante nello sviluppo di sistemi automatici per prevedere le etichette delle emozioni continue nel tempo dal discorso è che queste etichette non sono generalmente sincronizzate con il discorso in ingresso, " ha spiegato Khorram. "Ciò è dovuto principalmente a ritardi causati dal tempo di reazione, che è inerente alle valutazioni umane. A differenza di altri approcci, la nostra rete neurale convoluzionale è in grado di allineare e prevedere simultaneamente le etichette in modo end-to-end. La rete di sincronizzazione multi-ritardo sfrutta i tradizionali concetti di elaborazione del segnale (cioè il filtro di sincronizzazione) nelle moderne architetture di deep learning per affrontare il problema del ritardo di reazione."
I ricercatori hanno valutato la loro tecnica in una serie di esperimenti utilizzando due set di dati pubblicamente disponibili, vale a dire i set di dati RECOLA e SEWA. Hanno scoperto che compensare i ritardi di reazione degli annotatori durante l'addestramento del loro modello di riconoscimento delle emozioni ha portato a miglioramenti significativi nell'accuratezza del riconoscimento delle emozioni del modello.
Hanno anche osservato che i ritardi di reazione degli annotatori durante la definizione di etichette di emozioni continue non superano in genere i 7,5 secondi. Finalmente, i loro risultati suggeriscono che le parti del discorso che includono la risata richiedono generalmente componenti di ritardo più piccole rispetto a quelle contrassegnate da altri segnali emotivi. In altre parole, spesso è più facile per gli annotatori definire le etichette delle emozioni in segmenti del discorso che includono la risata.
"L'emozione è ovunque ed è al centro della nostra comunicazione, " Ha detto Mower Provost. "Stiamo costruendo sistemi di riconoscimento delle emozioni robusti e generalizzabili in modo che le persone possano facilmente accedere e utilizzare queste informazioni. Parte di questo obiettivo viene raggiunto creando algoritmi in grado di utilizzare efficacemente grandi fonti di dati esterne, sia etichettato che non, e modellando efficacemente le dinamiche naturali che fanno parte del modo in cui comunichiamo emotivamente. L'altra parte si ottiene dando un senso a tutta la complessità che è inerente alle etichette stesse".
Sebbene Mower Provost, Khorram e i loro colleghi hanno applicato la loro tecnica a compiti di riconoscimento delle emozioni, potrebbe anche essere utilizzato per migliorare altre applicazioni di apprendimento automatico in cui input e output non sono perfettamente allineati. Nel loro lavoro futuro, i ricercatori intendono continuare a studiare i modi in cui le etichette delle emozioni prodotte dagli annotatori umani possono essere integrate in modo efficiente nei dati.
"Abbiamo utilizzato un filtro di sincronizzazione per approssimare la funzione delta di Dirac e compensare i ritardi. Tuttavia, altre funzioni, come gaussiana e triangolare, può anche essere impiegato al posto del kernel di sincronizzazione, " Ha detto Khorram. "Il nostro lavoro futuro esplorerà l'effetto dell'utilizzo di diversi tipi di kernel che possono approssimare la funzione delta di Dirac. Inoltre, in questo articolo ci siamo concentrati sulla modalità vocale per prevedere annotazioni emotive continue, mentre la rete di sincronizzazione multi-ritardo proposta è una tecnica di modellazione ragionevole anche per altre modalità di input. Un altro piano futuro è valutare le prestazioni della rete proposta rispetto ad altre modalità fisiologiche e comportamentali come:video, linguaggio del corpo ed EEG."
© 2019 Scienza X Rete














