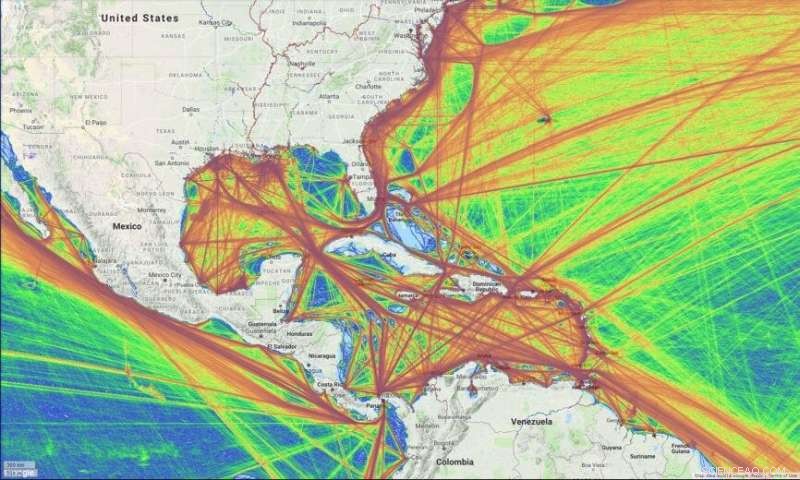
Il formato della mappa della densità di MarineTraffic che mostra le traiettorie delle navi da miliardi di punti dati dal 2017. Le linee colorate "fredde" indicano che una rotta non è stata presa spesso, le linee colorate "calde" indicano dove i percorsi sono spesso utilizzati. Il risultato è un set di dati globale della densità di tracciamento della nave. Credito:MarineTraffic
In questi giorni, gli ultimi sviluppi nella ricerca sull'intelligenza artificiale (AI) ricevono sempre molta attenzione, ma un ricercatore di intelligenza artificiale presso il Laboratorio di ricerca navale degli Stati Uniti ritiene che una tecnica di intelligenza artificiale potrebbe essere un po' troppo.
Ranjeev Mittu è a capo dell'Information Management and Decision Architectures Branch di NRL e lavora nel campo dell'IA da oltre due decenni.
"Penso che le persone si siano concentrate su un'area dell'apprendimento automatico, il deep learning (noto anche come reti profonde), e meno sulla varietà di altre tecniche di intelligenza artificiale, " Ha detto Mittu. "La più grande limitazione delle reti profonde è che una comprensione completa di come queste reti arrivino a una soluzione è ancora lontana dalla realtà".
Il deep learning è una tecnica di apprendimento automatico che può essere utilizzata per riconoscere modelli, come identificare un insieme di pixel come l'immagine di un cane. La tecnica prevede la stratificazione dei neuroni insieme, con ogni livello dedicato all'apprendimento di un diverso livello di astrazione.
Nell'esempio dell'immagine del cane, gli strati inferiori della rete neurale apprendono dettagli primitivi come i valori dei pixel. La serie successiva di livelli tenta di apprendere i bordi; gli strati più alti imparano una combinazione di bordi come un naso. Con abbastanza strati, queste reti sono in grado di riconoscere immagini con prestazioni quasi umane.
Ma i sistemi possono essere facilmente ingannati semplicemente cambiando un piccolo numero di pixel, secondo Mittu.
"Puoi avere 'attacchi' contraddittori in cui una volta creato un modello per riconoscere i cani mostrandogli milioni di immagini di cani, " disse. "... apportando modifiche a un piccolo numero di pixel, la rete potrebbe classificarlo erroneamente come un coniglio, Per esempio."
Il più grande difetto di questa tecnica di apprendimento automatico, secondo Mittu, è che c'è un grande grado di arte nel costruire questo tipo di reti, il che significa che ci sono pochissimi metodi scientifici per aiutare a capire quando falliranno.
La soluzione?
"Esistono numerose tecniche di intelligenza artificiale di cui l'apprendimento automatico è un sottoinsieme, " ha detto. "Mentre il deep learning ha avuto molto successo, è anche attualmente limitato perché c'è poca visibilità nella sua logica decisionale. Fino a quando non raggiungiamo veramente un punto in cui questa tecnica diventa completamente "spiegabile, " non può informare gli esseri umani o altre automazioni su come è arrivato a una soluzione, o perché ha fallito. Dobbiamo renderci conto che le reti profonde sono solo uno strumento nella cassetta degli attrezzi dell'IA".
E, gli umani devono rimanere nel circuito.
"Immagina di avere un sistema di rilevamento automatico delle minacce sul ponte della tua nave, e raccoglie un piccolo oggetto all'orizzonte, " ha detto. "La classificazione della rete profonda potrebbe indicare che si tratta di una nave da attacco veloce che sta venendo verso di te, ma sai che un insieme molto piccolo di pixel incerti può fuorviare l'algoritmo. Ci credi?
"Un essere umano dovrà esaminarlo ulteriormente. Potrebbe sempre essere necessario essere un essere umano nel circuito per situazioni ad alto rischio. Potrebbe esserci un alto grado di incertezza e la sfida è aumentare l'accuratezza della classificazione mantenendo basso il tasso di falsi allarmi —a volte è molto difficile trovare l'equilibrio perfetto."
Ambiente dati integrato e convergenza della rete di trasporto globale (IGC). Credito:Comando dei trasporti degli Stati Uniti/Agenzia logistica per la difesa
Il problema con l'apprendimento automatico
Quando si tratta di apprendimento automatico, il fattore chiave, in poche parole, sono dati.
Consideriamo uno dei precedenti progetti di Mittu:un'analisi dei movimenti delle navi mercantili nel mondo. L'obiettivo del progetto era utilizzare l'apprendimento automatico per discernere i modelli nel traffico navale per identificare le navi coinvolte in attività illecite. Si è rivelato un problema difficile da modellare e comprendere utilizzando l'apprendimento automatico, disse Mitù.
"Non possiamo avere un modello globale perché i comportamenti saranno diversi per le classi di navi, proprietari, ecc." ha spiegato. "È anche diverso stagionalmente, a causa dello stato del mare e dei modelli meteorologici."
Ma il problema più grande, Mittu trovato, era la possibilità di utilizzare erroneamente dati di scarsa qualità.
"Le navi trasmettono la loro posizione e altre informazioni, proprio come gli aerei. Ma ciò che trasmettono può essere falsificato, "Mittu ha detto. "Non sai se è un'informazione buona o cattiva. È come cambiare quei piccoli numeri di pixel sull'immagine del cane che causano il fallimento del sistema".
I dati mancanti sono un altro problema. Immagina un caso in cui devi spostare regolarmente un gran numero di persone e materiali per sostenere operazioni militari, e ti affidi a dati incompleti per prevedere come potresti agire in modo più efficiente.
"La difficoltà arriva quando inizi ad addestrare algoritmi di machine learning su dati di scarsa qualità, " Ha detto Mittu. "Il machine learning diventa inaffidabile a un certo punto, e gli operatori non si fideranno dei risultati degli algoritmi".
Lavoro attuale in AI
Oggi il team di Mittu continua a perseguire innovazioni AI in più aree del campo. Sostengono un approccio interdisciplinare all'utilizzo di sistemi di intelligenza artificiale per risolvere problemi complessi.
"Ci sono molti modi per migliorare le capacità predittive, ma probabilmente il migliore adotterà un approccio olistico e impiegherà più tecniche di intelligenza artificiale e integrerà strategicamente il decisore umano, " Egli ha detto.
"Aggregazione di varie tecniche (simili a 'boosting'), che possono "pesare" gli algoritmi in modo diverso, potrebbe fornire una risposta migliore, o l'apprendimento combinato con il ragionamento, ecc. Utilizzando combinazioni di tecniche di intelligenza artificiale, il sistema risultante potrebbe essere più robusto per una scarsa qualità dei dati."
Un'area di cui Mittu è entusiasta sono i sistemi di raccomandazione. Secondo lui, la maggior parte delle persone ha già familiarità con questi sistemi, che vengono utilizzati nei motori di ricerca e nelle applicazioni di intrattenimento come Netflix. È entusiasta delle potenziali applicazioni militari.
"Pensa a un sistema di comando e controllo militare, dove gli utenti hanno bisogno di buone informazioni per prendere buone decisioni, " ha detto. "Osservando ciò che l'utente sta facendo nel sistema in un certo contesto, possiamo anticipare ciò che l'utente potrebbe fare dopo e dedurre i dati di cui potrebbe aver bisogno."
Mentre il campo dell'IA offre un potenziale quasi illimitato per soluzioni innovative ai problemi di oggi, Mittu ha detto, i ricercatori hanno ovviamente molti anni di lavoro davanti a loro.
"Dobbiamo determinare le tecniche giuste, i loro limiti, e i dati necessari per ottenere risposte affidabili affinché gli utenti si fidino del sistema risultante, " ha detto. "Il campo dell'intelligenza artificiale ha una lunga strada da percorrere per adottare un approccio olistico integrando strategicamente il decisore al fine di migliorare le prestazioni del sistema uomo e macchina".














