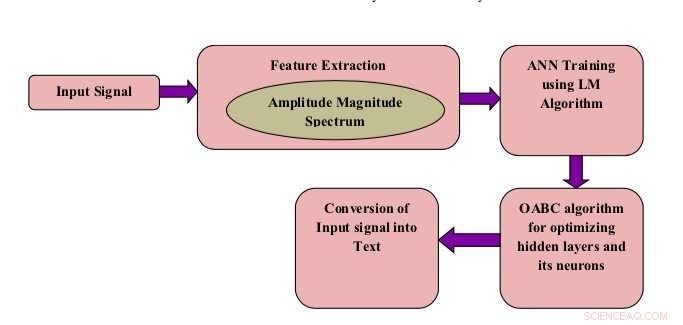
Schema a blocchi del modello proposto. Credito:Shukla e Jain.
Negli ultimi dieci anni o giù di lì, i progressi nell'apprendimento automatico hanno aperto la strada allo sviluppo di strumenti di riconoscimento vocale sempre più avanzati. Analizzando i file audio del linguaggio umano, questi strumenti possono imparare a identificare parole e frasi in diverse lingue, convertendoli in un formato leggibile dalla macchina.
Sebbene diversi modelli basati sull'apprendimento automatico abbiano ottenuto risultati promettenti nelle attività di riconoscimento vocale, non sempre funzionano bene in tutte le lingue. Ad esempio, quando una lingua ha un vocabolario con molte parole dal suono simile, le prestazioni dei sistemi di riconoscimento vocale possono diminuire considerevolmente.
Ricercatori del Mahatma Gandhi Mission's College of Engineering &Technology e del Jaypee Institute of Information Technology, in India, hanno sviluppato un sistema di riconoscimento vocale per affrontare questo problema. Questo nuovo sistema, presentato in un articolo pubblicato su Springer Link's Rivista internazionale di tecnologia del linguaggio , combina una rete neurale artificiale (ANN) con una tecnica di ottimizzazione nota come colonie di api artificiali di opposizione (OABC).
"In questo lavoro, la struttura predefinita delle ANN viene ridisegnata utilizzando l'algoritmo di Levenberg-Marquardt per recuperare un tasso di previsione ottimale con precisione, I ricercatori hanno scritto nel loro articolo. "Gli strati nascosti e i neuroni degli strati nascosti vengono ulteriormente ottimizzati utilizzando la tecnica di ottimizzazione delle colonie di api artificiali di opposizione".
Una caratteristica unica del sistema sviluppato dai ricercatori è che utilizza un algoritmo di ottimizzazione OABC per ottimizzare gli strati della ANN ei neuroni artificiali. Come suggerisce il nome, Gli algoritmi delle colonie di api artificiali (ABC) sono progettati per simulare il comportamento delle api da miele per affrontare una serie di problemi di ottimizzazione.
"In genere, gli algoritmi di ottimizzazione inizializzano casualmente le soluzioni nel dominio di corrispondenza, " hanno spiegato i ricercatori nel loro articolo. "Ma questa soluzione potrebbe trovarsi nella direzione opposta della soluzione migliore, aumentando così in modo significativo l'overhead computazionale. Quindi questa inizializzazione basata sull'opposizione è definita come OABC."
Il sistema sviluppato dai ricercatori considera le singole parole pronunciate da persone diverse come un segnale vocale in ingresso. Successivamente, estrae le cosiddette caratteristiche dello spettrogramma di modulazione di ampiezza (AM), che sono essenzialmente caratteristiche specifiche del suono.
Le caratteristiche estratte dal modello vengono quindi utilizzate per addestrare la ANN a riconoscere il linguaggio umano. Dopo essere stato addestrato su un ampio database di file audio, la RNA impara a prevedere parole isolate in nuovi campioni di linguaggio umano.
I ricercatori hanno testato il loro sistema su una serie di clip audio del parlato umano e lo hanno confrontato con tecniche di riconoscimento vocale più convenzionali. La loro tecnica ha superato tutti gli altri metodi, ottenendo punteggi di precisione notevoli.
"La sensibilità, specificità, e l'accuratezza del metodo proposto è del 90,41 percento, 99,66 percento e 99,36 percento, rispettivamente, che è migliore di tutti i metodi esistenti, " hanno scritto i ricercatori nel loro articolo.
Nel futuro, il sistema di riconoscimento vocale potrebbe essere utilizzato per ottenere una comunicazione uomo-macchina più efficace in una varietà di contesti. Inoltre, l'approccio utilizzato per sviluppare il sistema potrebbe ispirare altri team a progettare modelli simili, che combinano ANN e tecniche di ottimizzazione OABC.
© 2019 Science X Network














