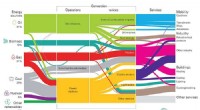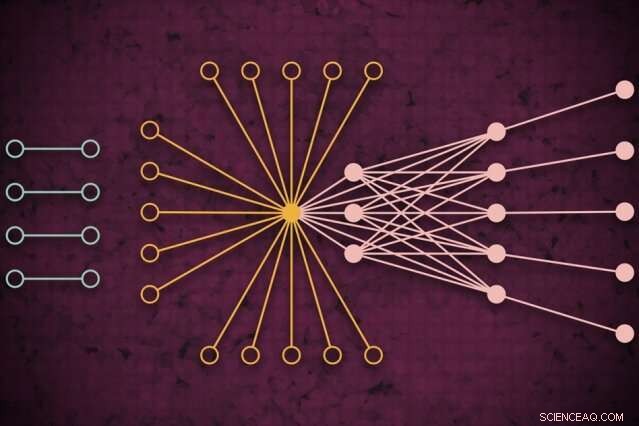
Utilizzando un sistema di supercalcolo, I ricercatori del MIT hanno sviluppato un modello che cattura come potrebbe essere il traffico web globale in un dato giorno, inclusi collegamenti isolati inediti (a sinistra) che si connettono raramente ma sembrano avere un impatto sul traffico web principale (a destra). Credito:MIT News
Utilizzando un sistema di supercalcolo, I ricercatori del MIT hanno sviluppato un modello che cattura l'aspetto del traffico web in tutto il mondo in un dato giorno, che può essere utilizzato come strumento di misurazione per la ricerca su Internet e molte altre applicazioni.
Comprendere i modelli di traffico web su così vasta scala, dicono i ricercatori, è utile per informare la politica di Internet, identificare e prevenire le interruzioni, difendersi dagli attacchi informatici, e progettare un'infrastruttura informatica più efficiente. Un documento che descrive l'approccio è stato presentato alla recente conferenza IEEE High Performance Extreme Computing.
Per il loro lavoro, i ricercatori hanno raccolto il più grande set di dati sul traffico Internet disponibile al pubblico, comprendente 50 miliardi di pacchetti di dati scambiati in diverse località del mondo in un periodo di diversi anni.
Hanno eseguito i dati attraverso una nuova pipeline di "rete neurale" che operava su 10, 000 processori del MIT SuperCloud, un sistema che combina le risorse informatiche del MIT Lincoln Laboratory e dell'Istituto. Quella pipeline ha addestrato automaticamente un modello che acquisisce la relazione per tutti i collegamenti nel set di dati, dai ping comuni a giganti come Google e Facebook, a collegamenti rari che si collegano solo brevemente ma sembrano avere un certo impatto sul traffico web.
Il modello può prendere qualsiasi enorme set di dati di rete e generare alcune misurazioni statistiche su come tutte le connessioni nella rete si influenzano a vicenda. Può essere utilizzato per rivelare informazioni sulla condivisione di file peer-to-peer, indirizzi IP dannosi e comportamenti di spamming, la distribuzione degli attacchi in settori critici, e colli di bottiglia del traffico per allocare meglio le risorse di elaborazione e mantenere il flusso dei dati.
Nel concetto, il lavoro è simile alla misurazione del fondo cosmico a microonde dello spazio, le onde radio quasi uniformi che viaggiano intorno al nostro universo che sono state un'importante fonte di informazioni per studiare i fenomeni nello spazio esterno. "Abbiamo costruito un modello accurato per misurare lo sfondo dell'universo virtuale di Internet, "dice Jeremy Kepner, un ricercatore presso il MIT Lincoln Laboratory Supercomputing Center e un astronomo di formazione. "Se vuoi rilevare qualsiasi variazione o anomalia, devi avere un buon modello dello sfondo."
Insieme a Kepner sul giornale ci sono:Kenjiro Cho dell'Internet Initiative Japan; KC Claffy del Center for Applied Internet Data Analysis presso l'Università della California a San Diego; Vijay Gadepally e Peter Michaleas del Supercomputing Center del Lincoln Laboratory; e Lauren Milechin, un ricercatore del Dipartimento della Terra del MIT, Scienze dell'atmosfera e planetarie.
Scomporre i dati
Nella ricerca su Internet, esperti studiano anomalie nel traffico web che possono indicare, ad esempio, minacce informatiche. Fare così, aiuta a capire prima come si presenta il traffico normale. Ma catturarlo è rimasto impegnativo. I tradizionali modelli di "analisi del traffico" possono analizzare solo piccoli campioni di pacchetti di dati scambiati tra sorgenti e destinazioni limitate dalla posizione. Ciò riduce la precisione del modello.
I ricercatori non stavano specificamente cercando di affrontare questo problema di analisi del traffico. Ma stavano sviluppando nuove tecniche che potevano essere utilizzate sul SuperCloud del MIT per elaborare enormi matrici di rete. Il traffico Internet è stato il banco di prova perfetto.
Le reti sono generalmente studiate sotto forma di grafici, con attori rappresentati da nodi, e collegamenti che rappresentano le connessioni tra i nodi. Con il traffico Internet, i nodi variano in dimensioni e posizione. I grandi supernodi sono hub popolari, come Google o Facebook. I nodi foglia si estendono da quel supernodo e hanno più connessioni tra loro e il supernodo. Al di fuori di quel "nucleo" di supernodi e nodi foglia ci sono nodi e collegamenti isolati, che si collegano tra loro solo raramente.
Catturare l'intera estensione di quei grafici è impossibile per i modelli tradizionali. "Non puoi toccare quei dati senza accedere a un supercomputer, "dice Kepner.
In collaborazione con il progetto Widely Integrated Distributed Environment (WIDE), fondata da diverse università giapponesi, e il Centro per l'analisi dei dati di Internet applicata (CAIDA), in California, i ricercatori del MIT hanno catturato il più grande set di dati di acquisizione di pacchetti al mondo per il traffico Internet. Il set di dati anonimizzato contiene quasi 50 miliardi di punti dati di origine e destinazione univoci tra i consumatori e varie app e servizi durante giorni casuali in varie località del Giappone e degli Stati Uniti, risalente al 2015.
Prima che potessero addestrare qualsiasi modello su quei dati, avevano bisogno di fare un'ampia pre-elaborazione. Fare così, hanno utilizzato software che hanno creato in precedenza, chiamato Dynamic Distributed Dimensional Data Mode (D4M), che utilizza alcune tecniche di media per calcolare e ordinare in modo efficiente i "dati ipersparsi" che contengono molto più spazio vuoto rispetto ai punti dati. I ricercatori hanno suddiviso i dati in unità di circa 100, 000 pacchetti su 10, 000 processori MIT SuperCloud. Ciò ha generato matrici più compatte di miliardi di righe e colonne di interazioni tra sorgenti e destinazioni.
Catturare valori anomali
Ma la stragrande maggioranza delle celle in questo set di dati ipersparso era ancora vuota. Per elaborare le matrici, il team ha eseguito una rete neurale sullo stesso 10, 000 core. Dietro le quinte, una tecnica di prova ed errore ha iniziato ad adattare i modelli alla totalità dei dati, creando una distribuzione di probabilità di modelli potenzialmente accurati.
Quindi, ha utilizzato una tecnica di correzione degli errori modificata per perfezionare ulteriormente i parametri di ciascun modello per acquisire quanti più dati possibile. Tradizionalmente, le tecniche di correzione degli errori nell'apprendimento automatico cercheranno di ridurre il significato di eventuali dati periferici al fine di adattare il modello a una normale distribuzione di probabilità, che lo rende complessivamente più accurato. Ma i ricercatori hanno usato alcuni trucchi matematici per assicurarsi che il modello vedesse ancora tutti i dati periferici, come i collegamenti isolati, come significativi per le misurazioni complessive.
Alla fine, la rete neurale genera essenzialmente un modello semplice, con solo due parametri, che descrive il set di dati sul traffico Internet, "da nodi veramente popolari a nodi isolati, e lo spettro completo di tutto ciò che sta in mezzo, "dice Kepner.
I ricercatori stanno ora contattando la comunità scientifica per trovare la loro prossima applicazione per il modello. Esperti, ad esempio, potrebbe esaminare il significato dei collegamenti isolati che i ricercatori hanno trovato nei loro esperimenti che sono rari ma sembrano avere un impatto sul traffico web nei nodi principali.
Al di là di Internet, la pipeline della rete neurale può essere utilizzata per analizzare qualsiasi rete ipersparsa, come le reti biologiche e sociali. "Ora abbiamo dato alla comunità scientifica uno strumento fantastico per le persone che vogliono costruire reti più robuste o rilevare anomalie delle reti, " dice Kepner. "Queste anomalie possono essere solo comportamenti normali di ciò che fanno gli utenti, o potrebbero essere persone che fanno cose che non vuoi."
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.