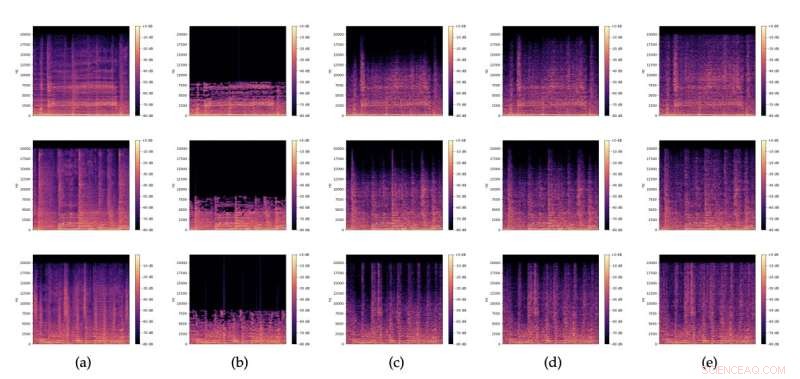
Spettrogrammi di (a) estratti audio originali, (b) corrispondenti versioni MP3 a 32 kbit/s e (c), (d), (e) restauri con rumore diverso z campionati casualmente da N (0,I). Credito:Lattner &Nistal.
Negli ultimi decenni, gli informatici hanno sviluppato tecnologie e strumenti sempre più avanzati per archiviare grandi quantità di file musicali e audio in dispositivi elettronici. Una pietra miliare particolare per l'archiviazione musicale è stato lo sviluppo della tecnologia MP3 (cioè MPEG-1 layer 3), una tecnica per comprimere sequenze sonore o brani in file molto piccoli che possono essere facilmente archiviati e trasferiti tra dispositivi.
La codifica, l'editing e la compressione di file multimediali, inclusi file PKZIP, JPEG, GIF, PNG, MP3, AAC, Cinepak e MPEG-2, si ottengono utilizzando una serie di tecnologie note come codec. I codec sono tecnologie di compressione con due componenti chiave:un codificatore che comprime i file e un decoder che li decomprime.
Esistono due tipi di codec, i cosiddetti codec lossless e lossy. Durante la decompressione, i codec lossless, come i codec PKZIP e PNG, riproducono esattamente lo stesso file dei file originali. I metodi di compressione con perdita, d'altra parte, producono un facsimile del file originale che suona (o assomiglia) all'originale ma occupa meno spazio di archiviazione nei dispositivi elettronici.
I codec audio lossy funzionano essenzialmente comprimendo i flussi audio digitali, rimuovendo alcuni dati e quindi decomprimendoli. In generale, la differenza tra il file originale e quello decompresso è difficile o impossibile da percepire per gli esseri umani.
Quando i codec con perdita di dati utilizzano velocità di compressione elevate, tuttavia, possono introdurre menomazioni e alterare sensibilmente i segnali audio. Di recente, gli informatici hanno cercato di superare questa limitazione dei codec con perdita di dati e di migliorare la qualità dei file compressi utilizzando tecniche di deep learning.
I ricercatori dei Sony Computer Science Laboratories (CSL) hanno recentemente sviluppato un nuovo metodo di apprendimento profondo per migliorare e ripristinare la qualità di brani e registrazioni audio fortemente compressi (ad esempio, file audio compressi da codec con perdita di dati con tassi di compressione elevati). Questo metodo, introdotto in un paper pre-pubblicato su arXiv, si basa sulle reti generative adversarial networks (GAN), modelli di machine learning in cui due reti neurali "competino" per fare previsioni sempre più accurate o affidabili.
"Molti lavori hanno affrontato il problema del miglioramento dell'audio e della rimozione degli artefatti da compressione utilizzando tecniche di deep learning", hanno scritto Stefan Lattner e Javier Nistal nel loro articolo. "Tuttavia, solo pochi lavori affrontano il ripristino di segnali audio fortemente compressi nel dominio musicale. In questo studio, testiamo un generatore stocastico per un'architettura di rete generativa contraddittoria (GAN) per questo compito."
Come altri GAN, il modello creato da Lattner e Nistal è composto da due modelli separati, noti come "generatore (G)" e "critico (D)". Il generatore riceve un estratto di un segnale audio musicale compresso MP3, rappresentato attraverso uno spettrogramma (cioè una rappresentazione visiva delle frequenze dello spettro di un segnale audio).
Il generatore impara continuamente a produrre una versione ripristinata di questo segnale originale, di dimensioni inferiori. Nel frattempo, il componente critico dell'architettura GAN impara a distinguere tra i file originali di alta qualità e le versioni ripristinate, individuando così le differenze tra di loro. In definitiva, le informazioni raccolte dal critico vengono utilizzate per migliorare la qualità dei file ripristinati, assicurando che i dati musicali o audio presenti nei file ripristinati siano il più fedeli possibile a quelli dell'originale.
Lattner e Nistal hanno valutato la loro architettura basata su GAN in una serie di test, volti a determinare se il loro modello potesse migliorare la qualità degli ingressi MP3 e generare campioni compressi di qualità superiore e più vicini a un file originale rispetto a quelli creati da altri modelli di base per la compressione audio. I loro risultati sono stati molto promettenti, poiché hanno scoperto che i ripristini del modello di file MP3 fortemente compressi (16 kbit/s e 32 kbit/s) erano in genere migliori dei file compressi originali, poiché suonavano meglio per ascoltatori umani esperti. Quando si utilizzano velocità di compressione più deboli (64 kbit/s mono), invece, il team ha riscontrato che il loro modello ha ottenuto risultati leggermente peggiori rispetto agli strumenti di compressione MP3 di base.
"Eseguiamo un'ampia valutazione dei diversi esperimenti utilizzando metriche oggettive e test di ascolto", hanno affermato Lattner e Nistal. "Troviamo che i modelli possono migliorare la qualità dei segnali audio rispetto alle versioni MP3 per 16 e 32 kbit/s e che i generatori stocastici sono in grado di generare output più vicini ai segnali originali rispetto a quelli dei generatori deterministici."
Nell'ambito del loro studio, i ricercatori hanno anche dimostrato che la loro architettura potrebbe generare e aggiungere con successo contenuti ad alta frequenza realistici che migliorano la qualità audio dei brani compressi. Il contenuto generato includeva elementi percussivi, una voce cantata che produceva sibilanti o esplosive (cioè suoni "s" e "t") e suoni di chitarra.
In futuro, il modello che hanno creato potrebbe aiutare a ridurre significativamente le dimensioni dei file musicali MP3 senza alterarne il contenuto o creare errori facilmente percepibili. Ciò potrebbe avere implicazioni significative per l'archiviazione e la trasmissione di musica sia su app di streaming (ad es. Spotify, Apple Music, ecc.) sia su moderni dispositivi elettronici, inclusi smartphone, tablet e computer. + Esplora ulteriormente
© 2022 Rete Science X














