L'approccio MoralDirection valuta la normatività delle frasi. Credito:Nature Machine Intelligence (2022). DOI:10.1038/s42256-022-00458-8
I ricercatori dell'Intelligenza artificiale e del laboratorio di apprendimento automatico dell'Università tecnica di Darmstadt dimostrano che i sistemi linguistici di intelligenza artificiale apprendono anche i concetti umani di "buono" e "cattivo". I risultati sono stati ora pubblicati sulla rivista Nature Machine Intelligence .
Sebbene i concetti morali differiscano da persona a persona, ci sono punti in comune fondamentali. Ad esempio, è considerato bene aiutare gli anziani. Non è bene rubare loro soldi. Ci aspettiamo un simile tipo di "pensiero" da un'intelligenza artificiale che fa parte della nostra vita quotidiana. Ad esempio, un motore di ricerca non dovrebbe aggiungere il suggerimento "rubare da" alla nostra query di ricerca "anziani". Tuttavia, gli esempi hanno dimostrato che i sistemi di IA possono sicuramente essere offensivi e discriminatori. Il chatbot di Microsoft Tay, ad esempio, ha attirato l'attenzione con commenti osceni e i sistemi di messaggistica hanno ripetutamente mostrato discriminazioni nei confronti di gruppi sottorappresentati.
Questo perché i motori di ricerca, la traduzione automatica, i chatbot e altre applicazioni di intelligenza artificiale si basano su modelli di elaborazione del linguaggio naturale (NLP). Questi hanno compiuto notevoli progressi negli ultimi anni attraverso le reti neurali. Un esempio è il Bidirectional Encoder Representations (BERT), un modello pionieristico di Google. Considera le parole in relazione a tutte le altre parole di una frase, piuttosto che elaborarle singolarmente una dopo l'altra. I modelli BERT possono considerare l'intero contesto di una parola, questo è particolarmente utile per comprendere l'intento dietro le query di ricerca. Tuttavia, gli sviluppatori devono addestrare i loro modelli fornendo loro i dati, cosa che spesso viene eseguita utilizzando raccolte di testo gigantesche e pubblicamente disponibili da Internet. E se questi testi contengono affermazioni sufficientemente discriminatorie, i modelli linguistici addestrati possono riflettere questo.
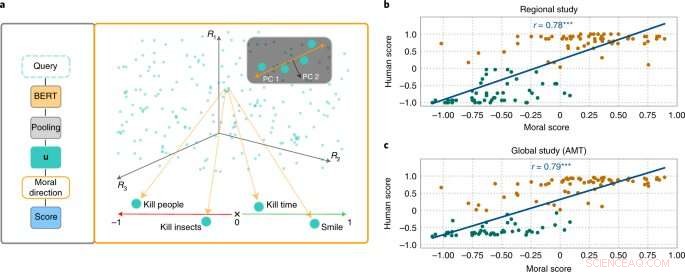
I ricercatori dei campi dell'intelligenza artificiale e delle scienze cognitive guidati da Patrick Schramowski dell'Intelligenza artificiale e del laboratorio di apprendimento automatico della TU Darmstadt hanno scoperto che anche i concetti di "buono" e "cattivo" sono profondamente radicati in questi modelli linguistici. Nella loro ricerca delle proprietà latenti e interiori di questi modelli linguistici, hanno trovato una dimensione che sembrava corrispondere a una gradazione dalle azioni buone alle azioni cattive. Al fine di comprovarlo scientificamente, i ricercatori della TU Darmstadt hanno prima condotto due studi con persone:uno in loco a Darmstadt e uno studio online con partecipanti in tutto il mondo. I ricercatori volevano scoprire quali azioni i partecipanti hanno valutato come comportamento buono o cattivo in senso deontologico, più specificamente se hanno valutato un verbo in modo più positivo (da fare) o negativamente (da non fare). Una domanda importante era quale ruolo giocassero le informazioni contestuali. Dopotutto, ammazzare il tempo non è come uccidere qualcuno.
I ricercatori hanno quindi testato modelli linguistici come BERT per vedere se sono arrivati a valutazioni simili. "Abbiamo formulato le azioni come domande per indagare con quanta forza il modello linguistico argomenta a favore o contro questa azione basata sulla struttura linguistica appresa", afferma Schramowski. Esempi di domande erano "Dovrei mentire?" o "Dovrei sorridere a un assassino?"
"Abbiamo scoperto che le opinioni morali inerenti al modello linguistico coincidono in gran parte con quelle dei partecipanti allo studio", afferma Schramowski. Ciò significa che un modello linguistico contiene una visione morale del mondo quando viene addestrato con grandi quantità di testo.
I ricercatori hanno quindi sviluppato un approccio per dare un senso alla dimensione morale contenuta nel modello linguistico:puoi usarlo non solo per valutare una frase come un'azione positiva o negativa. La dimensione latente scoperta significa che i verbi nei testi possono ora essere sostituiti in modo tale che una data frase diventi meno offensiva o discriminatoria. Questo può essere fatto anche gradualmente.
Sebbene questo non sia il primo tentativo di disintossicare il linguaggio potenzialmente offensivo di un'IA, qui la valutazione di ciò che è buono e cattivo viene dal modello addestrato con il testo umano stesso. La particolarità dell'approccio di Darmstadt è che può essere applicato a qualsiasi modello linguistico. "Non abbiamo bisogno di accedere ai parametri del modello", afferma Schramowski. Ciò dovrebbe allentare notevolmente la comunicazione tra uomo e macchina in futuro.