Uno degli oltre 7, 000 elenchi di nomi dai campi di concentramento nel Museo commemorativo dell'Olocausto degli Stati Uniti. Questa è una lista manoscritta di donne serbe e croate che sono state deportate nel campo di concentramento di Jasenovac. Credito:Museo commemorativo dell'Olocausto degli Stati Uniti
Il membro della facoltà di ingegneria aerospaziale Melkior Ornik è anche un matematico, un appassionato di storia, e un forte sostenitore dell'integrità quando si tratta di utilizzare la scienza dura nelle discussioni pubbliche. Così, quando nel suo feed di notizie è comparsa una storia su una coppia di ricercatori che hanno sviluppato un metodo statistico per analizzare i set di dati e l'hanno usato per confutare presumibilmente il numero delle vittime dell'Olocausto da un campo di concentramento in Croazia, ha naturalmente catturato la sua attenzione.
Ornik è professore presso il Dipartimento di ingegneria aerospaziale dell'Università dell'Illinois Urbana-Champaign. Ha proceduto a studiare la ricerca in profondità e ha utilizzato il metodo per rianalizzare gli stessi dati dal Museo dell'Olocausto degli Stati Uniti. Quindi ha scritto un documento di confutazione che smentiva i risultati dei ricercatori.
La confutazione di Ornik è pubblicata nella stessa rivista dell'articolo originale. Ha detto che l'editore gli ha chiesto di includere un elenco di risposte ad alcune delle potenziali domande che altri scienziati potrebbero avere quando leggono il suo articolo. Qualche settimana dopo, la rivista ha inserito una nota sull'articolo originale affermando che non approva o condivide le opinioni degli autori, e consiglia di leggere l'articolo di Ornik.
"Come scienziati, come ingegneri, Penso che sia nostro dovere correggere la scienza imperfetta e imperfetta, " ha detto Ornik. "C'è così tanto sforzo per convincere il pubblico e i responsabili politici a credere nella scienza, che quando un esperto di matematica dice di avere una prova, dà credito all'argomento. Ma quando le loro affermazioni sono dimostrabilmente false, non va bene per la scienza e non va bene per la società. Ecco perché è particolarmente importante che gli scienziati mettano in dubbio i risultati falsi quando li scopriamo".
Secondo Ornik, alcune persone promuovono l'idea che i campi di concentramento o non esistessero o non fossero usati per uccidere le persone, o che il numero di vittime attualmente ampiamente accettato è stato notevolmente gonfiato. La maggior parte degli storici non prende sul serio le affermazioni alla luce dei vasti dati e prove disponibili.
"Per gli autori del documento originale, affermare di aver trovato la prova matematica che l'elenco delle vittime di quel campo è stato fabbricato ha ovvie implicazioni storiche, " ha detto Ornik. "Penso, in una certa misura il danno è già stato fatto, ma ho sentito il bisogno di andare a verbale con le ipotesi, imprecisioni, e l'uso improprio dei dati grezzi del museo che ho trovato nella ricerca originale."
Il documento a cui ha risposto Ornik presenta un nuovo metodo per identificare le anomalie attraverso una serie di istogrammi. Ornik ha affermato di non contestare i meriti del metodo presentato nel documento originale, solo la sua applicazione al campo di concentramento di Jasenovac.
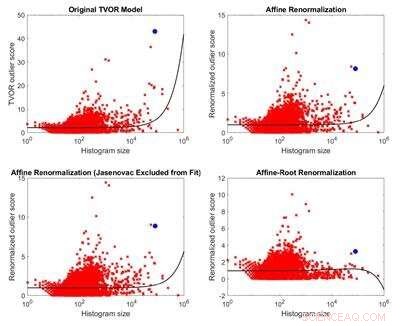
Confronto tra il modello di identificazione degli outlier originale e tre modelli da esso derivati. A causa dell'inapplicabilità delle sue ipotesi al set di dati considerato, il modello originale non ha alcun fondamento teorico. Tre modelli alternativi sono meno sbilanciati rispetto al modello originale e producono risultati opposti. Attestazione:Melkior Ornik
Ornik è diventato sospettoso delle conclusioni del documento perché i ricercatori hanno insinuato in un caso che un elenco più piccolo ha naturalmente un punteggio anomalo più piccolo, ma hanno confrontato i punteggi tra le dimensioni dell'elenco delle vittime per affermare che quello relativo a Jasenovac, uno dei più grandi, era problematico.
"Ho iniziato a cercare di vedere se c'era una sorta di pregiudizio per le dimensioni e se erano effettivamente più propensi ad assegnare il flag di essere problematico a un elenco più ampio o meno. E si scopre, nonostante le affermazioni degli autori, Li avevamo, " Ha detto Ornik. "Gli elenchi più grandi hanno maggiori probabilità di essere calcolati come problematici rispetto agli elenchi più piccoli quando il loro metodo viene applicato ai dati".
Ornico, che usa comunemente analisi statistiche simili nelle applicazioni aerospaziali, ha spiegato un'altra ragione per cui il loro argomento statistico non funziona.
"Quando guardi i dati, una raccolta di qualsiasi cosa, e vuoi scoprire un valore anomalo, qualcosa di diverso, devi presumere che tutti i dati provengano dalla stessa fonte, la stessa distribuzione. Fai un elenco delle vittime per anno di nascita. Darebbe un grafico delle età di ogni persona. Diciamo che il 10% ha più di 70 anni. Ora, quella distribuzione non sarebbe vera per un elenco di bambini deportati, Per esempio, perché quella lista, per definizione, è strutturalmente diverso. È anche diverso da un elenco di tutti coloro che hanno una carta d'identità. La carta d'identità viene rilasciata solo a persone che non sono bambini. Ancora, gli elenchi con cui questi ricercatori hanno lavorato provengono da una moltitudine di fonti e includono elenchi di bambini, elenchi di persone che si sposano, liste di prigionieri di guerra, cose che per definizione non possono provenire dalla stessa distribuzione."
Un altro grave errore nel documento originale, Ornik ha detto, è che alcuni elenchi duplicati sono stati trattati come due elenchi separati. Ciò significava che circa il 67 percento dell'intero database era in realtà sottoelenchi dell'elenco più grande.
"Il 7, Gli oltre 000 elenchi pubblicati online dal Museo dell'Olocausto non sono curati, " ha detto Ornik. "Per esempio, ci sono due elenchi che contengono esattamente gli stessi dati; uno è in cirillico e l'altro usa l'alfabeto latino. Ma li trattavano come due liste separate. Ci sono altri elenchi che contengono lo stesso nome, ma non c'è modo di sapere se sono la stessa persona o due persone diverse nate lo stesso giorno con nomi identici. Avrebbero potuto rimuovere gli errori molto eclatanti in cui un elenco è chiaramente duplicato, ma il resto, avresti bisogno di accedere ai dati storici originali."
Sia la carta originale che la carta di Ornik, "Commento su 'TVOR:trovare valori anomali di variazione totale discreti tra gli istogrammi, '" sono pubblicati in Accesso IEEE .














