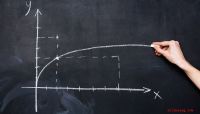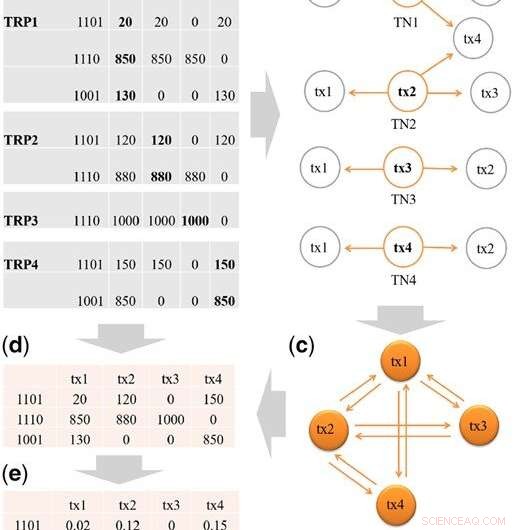
Passi per costruire la matrice di progetto di partenza X. (a) TRP di tx1, tx2, tx3 e tx4, e la sintesi dei modelli di occupazione binaria dai TRP. La trascrizione tx5 non passa il filtraggio (H = 2,5%) ed è filtrata da TRP1. In ogni schema binario, cifra 1 significa che ci sono letture provenienti da una eqclass, e 0 altrimenti. Per esempio, ci sono tre eqclass in TRP1:eqclass1, eqclass2 e eqclass3. Per eq1 il modello binario è 1101, che significa tre trascrizioni, cioè tx1, tx2 e tx4 hanno letture da eq1. (b) Trascrizione vicini (TN) da tx1 a tx4. (c) Illustrazione della costruzione del cluster di trascrizione (TC) dai TN. Raccogliamo prima i TN di tx1, tx2, tx3 e tx4, e quindi aggiungere le connessioni tra le trascrizioni nel TC. Per esempio, da TN1, aggiungiamo la connessione di tx1-tx2, tx1-tx3 e tx1-tx4. Alla fine, un TC conterrebbe tutte le connessioni tra le trascrizioni che condividono gli esoni. (d) L'insieme unico di modelli binari è mantenuto, quindi rimangono tre modelli unici:1101, 1001, 1110. Quindi inseriamo i conteggi letti da ciascun TRP di origine. Per esempio, per modello 1101, in TRP1 il conteggio delle letture è 20 per tx1, in TRP2 il conteggio delle letture è 120 per tx2 e in TRP4 il conteggio delle letture è 150 per tx4. (e) Le letture totali di ciascuna trascrizione in (d) sono standardizzate per sommare a 1 per creare la matrice di progettazione iniziale X. Credito:DOI:10.1093/bioinformatics/btz640
La tecnologia omica ad alto rendimento ha rivoluzionato la ricerca biologica e biomedica e sono stati prodotti grandi volumi di dati omici. Per questo, sono stati sviluppati strumenti computazionali per gestire e analizzare i dati omici e ci sono grandi sfide su come elaborare e interpretare i dati omici nel modo migliore. Wenjiang Deng ha lavorato per sviluppare nuove metodologie statistiche e algoritmi per l'analisi dei dati omici, utilizzando dati sul cancro simulati e reali per testare i metodi.
Potresti descrivere alcuni dei risultati nella tua tesi?
Sì, nel mio primo studio, identifichiamo diversi geni associati alla sopravvivenza dei pazienti con neuroblastoma ad alto rischio, dice Wenjiang Deng, dottorato di ricerca studente presso il Dipartimento di epidemiologia medica e biostatistica, MEB. Il neuroblastoma è il tumore più comune e più mortale nei bambini di età inferiore ai cinque anni. Riteniamo che i nostri risultati forniranno prove significative per il trattamento e la gestione dei pazienti. I nostri risultati possono anche essere significativi per comprendere i meccanismi fisiologici della malattia.
Come mai hai scelto di studiare questa particolare area?
Viviamo nell'era dei "big data, " e i dati di sequenziamento ad alto rendimento sono i "big data" predominanti nelle scienze della vita. Quando ho sentito per la prima volta il concetto di dati omici, Sono rimasto stupito dal suo enorme volume e dal grande potenziale nella ricerca medica. Al giorno d'oggi è abbastanza facile produrre dati di sequenziamento, ma abbiamo ancora bisogno di strumenti efficienti e precisi per analizzarli, così ho deciso di studiare lo sviluppo di algoritmi durante il mio periodo di dottorato. alunno.
Cosa farai dopo?
Dopo la mia difesa, Rimarrò a MEB per un po' per concludere i miei manoscritti. poi andrò a shenzhen, Cina, e iniziare a lavorare in una società di biotecnologie che mira a sviluppare nuovi metodi per la diagnosi precoce dei tumori. Spero che il nostro lavoro contribuirà alla salute generale degli esseri umani.