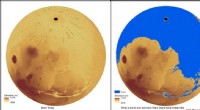
Il volume dei dati della sfida preparato dal team giapponese (al centro), rispetto al volume totale dell'universo reale osservabile dalla luce (a sinistra), e il volume di uno dei più grandi cataloghi di rilevamento galattico, la Sloan Digital Sky Survey (a destra). Da sinistra a destra, i volumi sarebbero equivalenti a cubi con spigoli di 75 miliardi di anni luce, 40 miliardi di anni luce, e 9 miliardi di anni luce. La marmorizzazione nella simulazione mostra aree di alta (rosso) e bassa (blu) densità. Credito:Takahiro Nishimichi
Gli astronomi hanno giocato a indovinare i numeri con implicazioni cosmologiche. Lavorando su un finto catalogo di galassie preparato da un team giapponese, due team americani hanno indovinato correttamente i parametri cosmologici utilizzati per generare il catalogo con una precisione dell'1%. Questo ci dà la certezza che i loro metodi saranno in grado di determinare i parametri corretti dell'universo reale quando applicati ai dati osservativi.
Le equazioni di base che governano l'evoluzione dell'universo possono essere derivate da calcoli teorici, ma alcuni dei numeri in quelle equazioni, i parametri cosmologici, può essere derivato solo attraverso le osservazioni. Parametri cosmologici legati alle parti non osservabili dell'universo, come la quantità di materia oscura o l'espansione dell'universo guidata dall'energia oscura, devono essere dedotte osservando i loro effetti sulla distribuzione delle galassie visibili. C'è sempre incertezza quando si lavora con la parte oscura dell'universo, ed è difficile essere sicuri che i modelli e l'analisi dei dati siano accurati.
Per testare l'analisi dei dati, un team giapponese guidato da Takahiro Nishimichi presso l'Università di Kyoto e il Kavli IPMU(nota) presso l'Università di Tokyo ha utilizzato il supercomputer ATERUI II presso l'Osservatorio Astronomico Nazionale del Giappone per creare 10 finti universi con un volume totale 100 volte maggiore anche del più estese indagini galattiche finora. Il grande volume, ampia gamma dinamica, e l'alta risoluzione ottenibile solo con il supercomputer più potente del mondo dedicato all'astronomia erano necessari per separare gli errori sistematici nei modelli di analisi da errori casuali dovuti a coincidenze insignificanti nei dati. I parametri cosmologici usati per evolvere questi finti universi sono stati scelti casualmente dalla gamma di valori ragionevolmente attesi. Il team giapponese ha preparato un catalogo che elenca le posizioni delle galassie nella simulazione simile ai cataloghi prodotti da veri telescopi che osservano il cielo. Il team giapponese ha quindi sfidato altri astronomi a indovinare i numeri utilizzati per generare il catalogo.
Due squadre americane hanno accettato la sfida. Lavorando in modo indipendente e utilizzando metodi diversi, entrambi i team hanno analizzato i dati giapponesi con strumenti utilizzati per vere e proprie indagini astronomiche. Ogni squadra aveva una sola possibilità di indovinare i numeri, ed entrambe le squadre hanno prodotto risposte entro l'1% dei valori reali. Ciò dimostra che questi metodi dovrebbero dare risultati corretti quando applicati a dati osservativi reali.
Quindi quali erano i numeri corretti? Sono ancora segreti in modo che più squadre possano giocare a indovinare i numeri. In questo modo i dati della sfida continueranno a supportare lo sviluppo e la sperimentazione di tecniche di analisi cosmica.
Questi risultati sono apparsi come Nishimichi et al. "Sfida cieca per la cosmologia di precisione con struttura su larga scala:risultati di una teoria di campo efficace per lo spettro di potenza delle galassie spaziali redshift" in Revisione fisica D il 28 dicembre 2020.