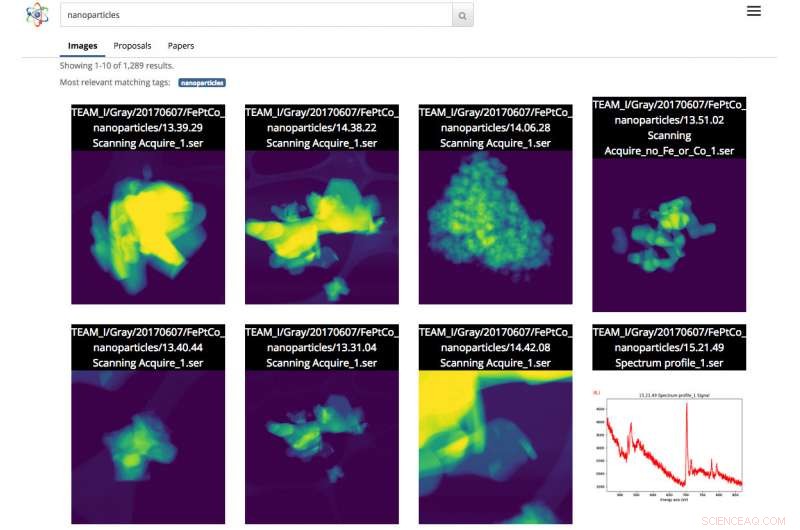
Screenshot dell'interfaccia di ricerca scientifica. In questo caso, l'utente ha effettuato una ricerca di immagini di nanoparticelle. Credito:Gonzalo Rodrigo, Berkeley Lab
Man mano che i set di dati scientifici aumentano sia in dimensioni che in complessità, la capacità di etichettare, filtrare e cercare questo diluvio di informazioni è diventato un lavoro laborioso, compito lungo e talvolta impossibile, senza l'ausilio di strumenti automatizzati.
Con questo in testa, un team di ricercatori del Lawrence Berkeley National Laboratory (Berkeley Lab) e dell'UC Berkeley stanno sviluppando strumenti di apprendimento automatico innovativi per estrarre informazioni contestuali da set di dati scientifici e generare automaticamente tag di metadati per ciascun file. Gli scienziati possono quindi cercare questi file tramite un motore di ricerca basato sul web per dati scientifici, chiamato ricerca scientifica, che il team di Berkeley sta costruendo.
Come prova di concetto, il team sta lavorando con il personale della fonderia molecolare del Dipartimento dell'energia (DOE), situato al Berkeley Lab, dimostrare i concetti di Science Search sulle immagini catturate dagli strumenti della struttura. Una versione beta della piattaforma è stata messa a disposizione dei ricercatori di Foundry.
"Uno strumento come Science Search ha il potenziale per rivoluzionare la nostra ricerca, "dice Colin Ophus, uno scienziato ricercatore della fonderia molecolare all'interno del Centro nazionale per la microscopia elettronica (NCEM) e collaboratore di ricerca scientifica. "Siamo una National User Facility finanziata dai contribuenti, e vorremmo rendere tutti i dati ampiamente disponibili, piuttosto che il piccolo numero di immagini scelte per la pubblicazione. Però, oggi, la maggior parte dei dati raccolti qui viene esaminata solo da una manciata di persone:i produttori di dati, compreso il PI (investigatore principale), i loro dottori di ricerca o dottorandi, perché attualmente non esiste un modo semplice per setacciare e condividere i dati. Rendendo questi dati grezzi facilmente ricercabili e condivisibili, via internet, Science Search potrebbe aprire questo serbatoio di "dati oscuri" a tutti gli scienziati e massimizzare l'impatto scientifico della nostra struttura".
Le sfide della ricerca di dati scientifici
Oggi, i motori di ricerca sono ubiquitariamente utilizzati per trovare informazioni su Internet, ma la ricerca di dati scientifici presenta una serie diversa di sfide. Per esempio, L'algoritmo di Google si basa su più di 200 indizi per ottenere una ricerca efficace. Questi indizi possono arrivare sotto forma di parole chiave su una pagina web, metadati nelle immagini o feedback del pubblico da miliardi di persone quando fanno clic sulle informazioni che stanno cercando. In contrasto, i dati scientifici si presentano in molte forme che sono radicalmente diverse da una normale pagina web, richiede un contesto specifico per la scienza e spesso manca anche dei metadati per fornire il contesto necessario per ricerche efficaci.
Presso strutture per utenti nazionali come la fonderia molecolare, ricercatori di tutto il mondo fanno richiesta di tempo e poi si recano a Berkeley per utilizzare gratuitamente strumenti estremamente specializzati. Ophus osserva che le attuali fotocamere sui microscopi della Fonderia possono raccogliere fino a un terabyte di dati in meno di 10 minuti. Gli utenti devono quindi setacciare manualmente questi dati per trovare immagini di qualità con "buona risoluzione" e salvare tali informazioni su un file system condiviso sicuro, come Dropbox, o su un disco rigido esterno che eventualmente portano a casa con sé per analizzare.
spesso, i ricercatori che vengono alla Fonderia Molecolare hanno solo un paio di giorni per raccogliere i loro dati. Poiché è molto noioso e richiede tempo aggiungere manualmente note a terabyte di dati scientifici e non esiste uno standard per farlo, la maggior parte dei ricercatori digita semplicemente le descrizioni abbreviate nel nome del file. Questo potrebbe avere senso per la persona che salva il file, ma spesso non ha molto senso per nessun altro.
"La mancanza di etichette di metadati reali alla fine causa problemi quando lo scienziato cerca di trovare i dati in un secondo momento o tenta di condividerli con altri, "dice Lavanya Ramakrishnan, uno scienziato del personale della divisione di ricerca computazionale (CRD) del Berkeley Lab e co-investigatore principale del progetto Science Search. "Ma con le tecniche di apprendimento automatico, possiamo fare in modo che i computer aiutino con ciò che è laborioso per gli utenti, inclusa l'aggiunta di tag ai dati. Quindi possiamo usare quei tag per cercare efficacemente i dati".
Per risolvere il problema dei metadati, il team del Berkeley Lab utilizza tecniche di apprendimento automatico per estrarre l'"ecosistema scientifico", inclusi i timestamp degli strumenti, log degli utenti della struttura, proposte scientifiche, pubblicazioni e strutture di file system, per informazioni contestuali. Le informazioni collettive provenienti da queste fonti, inclusa la data e l'ora dell'esperimento, note sulla risoluzione e sul filtro utilizzati e sulla richiesta di tempo dell'utente, tutto fornisce informazioni contestuali critiche. Il team del laboratorio di Berkeley ha messo insieme uno stack software innovativo che utilizza tecniche di apprendimento automatico, tra cui l'elaborazione del linguaggio naturale, per estrarre parole chiave contestuali sull'esperimento scientifico e creare automaticamente tag di metadati per i dati.
Per il proof of concept, Ophus ha condiviso i dati del microscopio elettronico TEAM 1 della Molecular Foundry all'NCEM che sono stati recentemente raccolti dal personale della struttura, con il team di ricerca scientifica. Si è anche offerto volontario per etichettare alcune migliaia di immagini per dare agli strumenti di apprendimento automatico alcune etichette da cui iniziare l'apprendimento. Anche se questo è un buon inizio, Il co-investigatore principale di Science Search Gunther Weber osserva che la maggior parte delle applicazioni di apprendimento automatico di successo richiedono in genere molti più dati e feedback per fornire risultati migliori. Per esempio, nel caso di motori di ricerca come Google, Weber osserva che i set di dati di formazione vengono creati e le tecniche di apprendimento automatico vengono convalidate quando miliardi di persone in tutto il mondo verificano la loro identità facendo clic su tutte le immagini con segnali stradali o vetrine dopo aver digitato le loro password, o su Facebook quando taggano i loro amici in un'immagine.
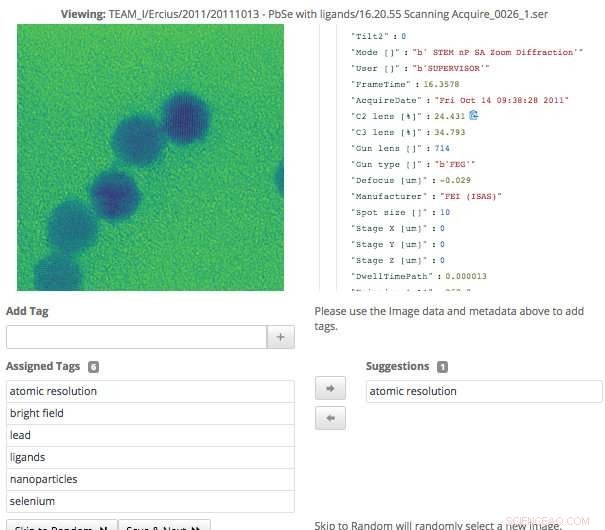
Questa schermata dell'interfaccia di ricerca scientifica mostra come gli utenti possono convalidare facilmente i tag di metadati che sono stati generati tramite l'apprendimento automatico, o aggiungere informazioni che non sono già state acquisite. Credito:Gonzalo Rodrigo, Berkeley Lab
"Nel caso dei dati scientifici, solo una manciata di esperti di dominio può creare set di formazione e convalidare tecniche di apprendimento automatico, quindi uno dei grandi problemi in corso che affrontiamo è un numero estremamente ridotto di set di allenamento, "dice Weber, che è anche uno scienziato del personale del CRD del Berkeley Lab.
Per vincere questa sfida, i ricercatori del Berkeley Lab hanno utilizzato il transfer learning per limitare i gradi di libertà, o conteggi dei parametri, sulle loro reti neurali convoluzionali (CNN). Il transfer learning è un metodo di machine learning in cui un modello sviluppato per un'attività viene riutilizzato come punto di partenza per un modello su una seconda attività, che consente all'utente di ottenere risultati più accurati da un set di allenamento più piccolo. Nel caso del microscopio TEAM I, i dati prodotti contengono informazioni sulla modalità di funzionamento in cui si trovava lo strumento al momento della raccolta. Con quelle informazioni, Weber è stato in grado di addestrare la rete neurale su quella classificazione in modo che potesse generare automaticamente l'etichetta della modalità di funzionamento. Quindi ha congelato quello strato convolutivo della rete, il che significava che avrebbe dovuto solo riqualificare gli strati densamente collegati. Questo approccio riduce efficacemente il numero di parametri sulla CNN, consentendo al team di ottenere risultati significativi dai propri dati di allenamento limitati.
Machine Learning per estrarre l'ecosistema scientifico
Oltre a generare tag di metadati tramite set di dati di addestramento, il team del Berkeley Lab ha anche sviluppato strumenti che utilizzano tecniche di apprendimento automatico per estrarre l'ecosistema scientifico per il contesto dei dati. Per esempio, il modulo di acquisizione dei dati può esaminare una moltitudine di fonti di informazioni dall'ecosistema scientifico, inclusi timestamp degli strumenti, log utente, proposte e pubblicazioni e identificare i punti in comune. Gli strumenti sviluppati al Berkeley Lab che utilizzano metodi di elaborazione del linguaggio naturale possono quindi identificare e classificare le parole che danno contesto ai dati e facilitare in seguito risultati significativi per gli utenti. L'utente vedrà qualcosa di simile alla pagina dei risultati di una ricerca su Internet, dove il contenuto con la maggior parte del testo che corrisponde alle parole di ricerca dell'utente apparirà più in alto nella pagina. Il sistema apprende anche dalle query degli utenti e dai risultati di ricerca su cui fanno clic.
Poiché gli strumenti scientifici stanno generando un insieme di dati in continua crescita, tutti gli aspetti del motore di ricerca scientifica del team di Berkeley dovevano essere scalabili per stare al passo con la velocità e la scala dei volumi di dati prodotti. Il team ha raggiunto questo obiettivo configurando il proprio sistema in un'istanza Spin sul supercomputer Cori presso il National Energy Research Scientific Computing Center (NERSC). Spin è una tecnologia edge-service basata su Docker sviluppata presso NERSC in grado di accedere ai sistemi di elaborazione ad alte prestazioni della struttura e allo storage sul back-end.
"Uno dei motivi per cui è possibile creare uno strumento come Science Search è il nostro accesso alle risorse del NERSC, "dice Gonzalo Rodrigo, un ricercatore post-dottorato del Berkeley Lab che sta lavorando sull'elaborazione del linguaggio naturale e sulle sfide infrastrutturali nella ricerca scientifica. "Dobbiamo immagazzinare, analizzare e recuperare set di dati davvero grandi, ed è utile avere accesso a una struttura di supercalcolo per fare il lavoro pesante per questi compiti. Spin di NERSC è un'ottima piattaforma per eseguire il nostro motore di ricerca che è un'applicazione rivolta all'utente che richiede l'accesso a grandi set di dati e dati analitici che possono essere archiviati solo su grandi sistemi di archiviazione di supercalcolo."
Un'interfaccia per la convalida e la ricerca dei dati
Quando il team di Berkeley Lab ha sviluppato l'interfaccia per consentire agli utenti di interagire con il proprio sistema, sapevano che avrebbe dovuto raggiungere un paio di obiettivi, compresa la ricerca efficace e consentendo l'input umano ai modelli di apprendimento automatico. Poiché il sistema si basa su esperti di dominio per aiutare a generare i dati di addestramento e convalidare l'output del modello di apprendimento automatico, l'interfaccia necessaria per facilitarlo.
"L'interfaccia di tagging che abbiamo sviluppato mostra i dati originali e i metadati disponibili, così come tutti i tag generati dalla macchina che abbiamo finora. Gli utenti esperti possono quindi sfogliare i dati e creare nuovi tag e rivedere eventuali tag generati dalla macchina per verificarne la precisione, "dice Matt Henderson, che è un ingegnere dei sistemi informatici in CRD e guida lo sforzo di sviluppo dell'interfaccia utente.
Per facilitare una ricerca efficace degli utenti sulla base delle informazioni disponibili, l'interfaccia di ricerca del team fornisce un meccanismo di query per i file disponibili, proposte e documenti che gli strumenti di apprendimento automatico sviluppati da Berkeley hanno analizzato ed estratto i tag. Ogni elemento del risultato di ricerca elencato rappresenta un riepilogo di tali dati, con una visualizzazione secondaria più dettagliata disponibile, comprese le informazioni sui tag che corrispondono a questo articolo. Il team sta attualmente esplorando come incorporare al meglio il feedback degli utenti per migliorare i modelli e i tag.
"Avere la capacità di esplorare i set di dati è importante per le scoperte scientifiche, e questa è la prima volta che si tenta qualcosa di simile a Science Search, " afferma Ramakrishnan. "La nostra visione finale è quella di costruire le fondamenta che alla fine supporteranno un 'Google' per i dati scientifici, dove i ricercatori possono persino cercare set di dati distribuiti. Il nostro lavoro attuale fornisce le basi necessarie per arrivare a quella visione ambiziosa".
"Berkeley Lab è davvero il luogo ideale per creare uno strumento come Science Search perché disponiamo di numerose strutture per gli utenti, come la Fonderia Molecolare, che hanno decenni di dati che darebbero ancora più valore alla comunità scientifica se i dati potessero essere ricercati e condivisi, "aggiunge Katie Antypas, che è il ricercatore principale di Science Search e capo del dipartimento dati del NERSC. "Inoltre, abbiamo un ottimo accesso alle competenze di apprendimento automatico nell'area di scienze informatiche del Berkeley Lab e alle risorse HPC del NERSC per sviluppare queste capacità".