Confronto delle classifiche dei concetti per un rapporto di Human Rights Watch. La colonna "Verità fondamentale" mostra le otto persone più frequentemente citate nel rapporto "La crisi umanitaria del Venezuela", mentre le altre colonne mostrano i valori restituiti da vari metodi di rilevamento. I valori che sono tra i concetti di verità fondamentale sono indicati da caselle scure. Il metodo context restituisce valori tutti rilevanti (anche se mancanti dall'articolo originale), mentre il metodo delle co-occorrenze restituisce molti concetti popolari ma irrilevanti (ad es. politici che rilasciano dichiarazioni generali sull'argomento). Credito:IBM
In IBM Research AI, abbiamo creato una soluzione basata sull'intelligenza artificiale per assistere gli analisti nella preparazione dei report. L'articolo che descrive questo lavoro ha recentemente vinto il premio per il miglior articolo al "In-Use" Track of the 2018 Extended Semantic Web Conference (ESWC).
Gli analisti hanno spesso il compito di preparare report completi e accurati su determinati argomenti o domande di alto livello, che possono essere utilizzati da organizzazioni, imprese, o agenzie governative per prendere decisioni informate, riducendo il rischio associato ai loro piani futuri. Per preparare tali rapporti, gli analisti devono identificare gli argomenti, le persone, organizzazioni, ed eventi relativi alle domande. Come esempio, al fine di redigere una relazione sulle conseguenze della Brexit sui mercati finanziari di Londra, un analista deve essere consapevole dei principali argomenti correlati (ad es. mercati finanziari, economia, Brexit, Brexit Divorzio Bill), persone e organizzazioni (ad es. L'Unione Europea, decisori nell'UE e nel Regno Unito, persone coinvolte nei negoziati sulla Brexit), ed eventi (es. incontri di negoziazione, Elezioni parlamentari all'interno dell'UE, eccetera.). Una soluzione assistita dall'intelligenza artificiale può aiutare gli analisti a preparare report completi ed evitare anche distorsioni basate sull'esperienza passata. Per esempio, un analista potrebbe perdere un'importante fonte di informazioni se non è stata utilizzata in modo efficace in passato.
Il team di induzione della conoscenza presso IBM Research AI ha creato la soluzione utilizzando il deep learning e i dati strutturati degli eventi. Il gruppo, guidato da Alfio Gliozzo, ha vinto anche il prestigioso premio Semantic Web Challenge lo scorso anno.
Incorporamenti semantici da database di eventi
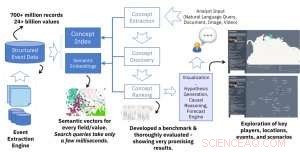
La principale novità tecnica di questo lavoro è la creazione di incorporamenti semantici da dati di eventi strutturati. L'input al nostro motore di incorporazione semantica è una grande fonte di dati strutturati (ad es. tabelle di database con milioni di righe) e l'output è un'ampia raccolta di vettori con una dimensione costante (ad es. 300) dove ogni vettore rappresenta il contesto semantico di un valore nei dati strutturati. L'idea di base è simile all'idea popolare e ampiamente utilizzata di incorporamenti di parole nell'elaborazione del linguaggio naturale, ma invece delle parole, rappresentiamo i valori nei dati strutturati. Il risultato è una soluzione potente che consente una ricerca semantica rapida ed efficace in diversi campi del database. Una singola query di ricerca richiede solo pochi millisecondi ma recupera i risultati in base all'estrazione di centinaia di milioni di record e miliardi di valori.
Mentre abbiamo sperimentato vari modelli di rete neurale per la costruzione di incorporamenti, abbiamo ottenuto risultati molto promettenti utilizzando un semplice adattamento del modello originale skip-gram word2vec. Questo è un efficiente modello di rete neurale superficiale basato su un'architettura che predice il contesto (parole circostanti) data una parola in un documento. Nel nostro lavoro, non si tratta di documenti di testo ma di record di database strutturati. Per questo, non abbiamo più bisogno di usare una finestra scorrevole di dimensione fissa o casuale per catturare il contesto. Nei dati strutturati, il contesto è definito da tutti i valori nella stessa riga indipendentemente dalla posizione della colonna, poiché due colonne adiacenti in un database sono correlate come qualsiasi altra due colonne. L'altra differenza nelle nostre impostazioni è la necessità di acquisire diversi campi (o colonne) nel database. Il nostro motore deve abilitare entrambe le query semantiche generali (ad es. restituire qualsiasi valore del database correlato al valore dato) e valori specifici del campo (cioè, restituiscono valori da un dato campo relativo al valore di input). Per questo, assegniamo un tipo ai vettori costruiti da ogni campo e costruiamo un indice che supporta query generiche o specifiche del tipo.
Credito:IBM
Per il lavoro descritto nel nostro articolo, abbiamo utilizzato tre database di eventi pubblicamente disponibili come input:GDELT, ICEWS, e Registro eventi. Globale, questi database sono costituiti da centinaia di milioni di record (oggetti JSON o righe di database) e miliardi di valori in vari campi (attributi). Utilizzando il nostro motore di incorporamento, ogni valore si trasforma in un vettore che rappresenta il contesto nei dati.
Una semplice query di recupero
Si può vedere come il contesto viene catturato dal nostro motore usando una semplice query di recupero. Per esempio, durante la ricerca del valore "Hilary Clinton" (errore di ortografia) nel campo "persona" in GDELT GKG, il primo vettore di successo o più simile è "Hilary Clinton" (errore di ortografia) nel campo "nome" e i successivi vettori più simili sono "Hillary Clinton" (ortografia corretta) nei campi "persona" e "nome". Ciò è dovuto al contesto molto simile del valore errato e dell'ortografia corretta, e anche i valori nei campi "nome" e "persona". Il resto dei risultati per la query di cui sopra include politici statunitensi, in particolare quelli attivi durante le ultime elezioni presidenziali, così come le organizzazioni collegate, persone con ruoli professionali simili in passato, e familiari.
Ricerca per similarità su query combinate
Certo, la nostra soluzione è in grado di ottenere molto di più di una semplice query di recupero. In particolare, è possibile combinare queste query per trasformare un insieme di valori estratti da una query in linguaggio naturale in un vettore ed eseguire una ricerca di similarità. Abbiamo valutato il risultato di questo approccio utilizzando un benchmark costruito da rapporti scritti da esperti umani, ed esaminato la capacità del nostro motore di restituire i concetti descritti nei report utilizzando il titolo del report come unico input. I risultati hanno mostrato chiaramente la superiorità del nostro approccio alla scoperta dei concetti basato sugli incorporamenti semantici rispetto a un approccio di base che si basa solo sulla co-occorrenza dei valori.
Nuove applicazioni nella scoperta dei concetti
Un aspetto molto interessante del nostro framework è che ad ogni valore e ad ogni campo viene assegnato un vettore che ne rappresenta il contesto, che consente nuove interessanti applicazioni. Per esempio, abbiamo incorporato le coordinate di latitudine e longitudine dagli eventi nei database nello stesso spazio semantico dei concetti, e ha lavorato con il Visual AI Lab guidato da Mauro Martino per costruire un framework di visualizzazione che evidenzi posizioni correlate su una mappa geografica data una domanda in linguaggio naturale. Un'altra interessante applicazione che stiamo attualmente studiando è l'utilizzo dei concetti recuperati e dei loro incorporamenti semantici come funzionalità per un modello di apprendimento automatico che l'analista deve costruire. Questo può essere utilizzato in un motore automatizzato di machine learning e data science (AutoML), e supportare gli analisti in un altro aspetto importante del loro lavoro. Stiamo pianificando di integrare questa soluzione in IBM Scenario Planning Advisor, un sistema di supporto alle decisioni per gli analisti del rischio.
Questa storia è stata ripubblicata per gentile concessione di IBM Research. Leggi la storia originale qui.