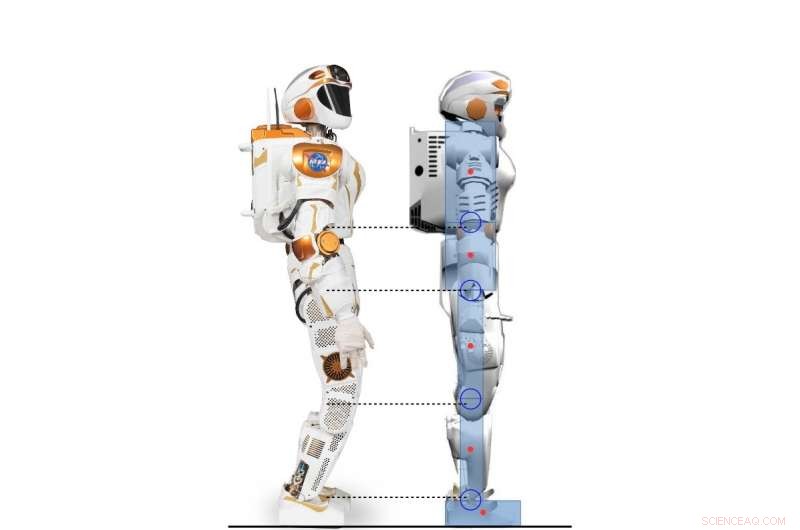
Vista laterale del robot Valkyrie e del personaggio umanoide 2D modellato secondo il robot Valkyrie. Credito:Yang, Komura &Li
I ricercatori dell'Università di Edimburgo hanno sviluppato un quadro gerarchico basato sull'apprendimento per rinforzo profondo (RL) che può acquisire una varietà di strategie per il controllo dell'equilibrio umanoide. Il loro quadro, delineato in un documento pre-pubblicato su arXiv e presentato alla International Conference on Humanoid Robotics del 2017, potrebbe eseguire comportamenti di bilanciamento molto più umani rispetto ai controller convenzionali.
Quando si sta in piedi o si cammina, gli esseri umani usano in modo innato ed efficace una serie di tecniche per il controllo non attuato che li aiutano a mantenere l'equilibrio. Questi includono l'inclinazione della punta e il rotolamento del tallone, che creano una migliore distanza dal suolo. Replicare comportamenti simili nei robot umanoidi potrebbe migliorare notevolmente le loro capacità motorie e di movimento.
"La nostra ricerca si concentra sull'uso della RL profonda per risolvere la locomozione dinamica di robot umanoidi, "Dottor Zhibin Li, un docente di robotica e controllo presso l'Università di Edimburgo, chi ha condotto lo studio, ha detto a TechXplore. "Nel passato, la locomozione è stata eseguita principalmente utilizzando approcci analitici convenzionali, basati su modelli, che sono limitate perché richiedono sforzo umano e conoscenza, e richiedono un'elevata potenza di calcolo per funzionare online."
Richiedendo meno sforzo umano e sintonizzazione manuale, le tecniche di apprendimento automatico potrebbero portare allo sviluppo di controller più efficaci e specifici rispetto agli approcci ingegneristici tradizionali. Un ulteriore vantaggio dell'utilizzo di RL è che il calcolo per questi strumenti può anche essere esternalizzato offline, con conseguente prestazioni online più veloci per sistemi di controllo dimensionali elevati, come i robot umanoidi.

Un robot Valkyrie simulato in posizione di inclinazione della punta/del tallone. Credito:Yang, Komura &Li
"Dati gli algoritmi RL profondi sempre più potenti, un numero crescente di studi di ricerca ha iniziato a utilizzare la RL profonda per risolvere compiti di controllo, poiché i recenti progressi negli algoritmi RL profondi progettati per il dominio di azione continua hanno portato avanti la possibilità di applicare compiti di controllo continuo di apprendimento per rinforzo che coinvolgono dinamiche complicate, " Il Dr. Li ha spiegato. "L'obiettivo principale della nostra ricerca era esplorare le possibilità di utilizzare l'apprendimento per rinforzo profondo per acquisire politiche di controllo versatili paragonabili o migliori degli approcci analitici utilizzando meno sforzo umano".
Il quadro sviluppato dal Dr. Li, in collaborazione con il Dr. Taku Komura e Ph.D. studente Chuanyu Yang, utilizza il deep RL per ottenere politiche di controllo di alto livello. Ricevere costantemente feedback sullo stato del robot, queste strategie consentono angoli di giunzione desiderati a una frequenza inferiore.
"A livello basso, i controllori proporzionali e derivativi (PD) sono utilizzati a una frequenza di controllo molto più elevata per garantire movimenti articolari stabili, " Il dottorando Chuanyu ha detto. "Gli input per il controller PD di basso livello sono gli angoli articolari desiderati prodotti dalla rete neurale di alto livello, e le uscite sono le coppie desiderate per i motori congiunti."
I ricercatori hanno testato le prestazioni del loro algoritmo e hanno ottenuto risultati molto promettenti. Hanno scoperto che il trasferimento della conoscenza umana dai metodi di ingegneria del controllo alla progettazione della ricompensa per gli algoritmi RL ha consentito strategie di controllo dell'equilibrio simili a quelle utilizzate dagli esseri umani. Inoltre, man mano che gli algoritmi RL migliorano attraverso un processo di tentativi ed errori, adattarsi automaticamente a nuove situazioni, la loro struttura richiede poca messa a punto manuale o altri interventi da parte di ingegneri umani.
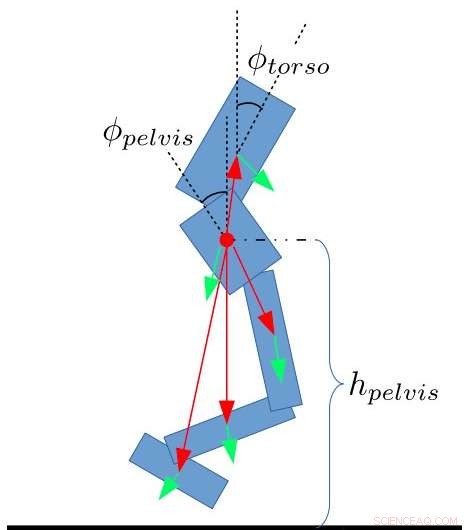
Caratteristiche di stato per il bipede. Yang, Komura &Li
"Il nostro studio mostra che l'apprendimento per rinforzo profondo può essere uno strumento potente per produrre risultati di bilanciamento paragonabili a quelli di un controller progettato dall'uomo con meno sforzo di sintonizzazione manuale e tempi più brevi, " Ha detto il dott. Li. "L'algoritmo di apprendimento per rinforzo profondo che abbiamo sviluppato è persino in grado di apprendere comportamenti simili a quelli umani emersi come inclinarsi intorno alle dita dei piedi o ai talloni, che la maggior parte dei metodi di ingegneria non è in grado di eseguire."
Il dottor Li e i suoi colleghi stanno ora lavorando a un'estensione del loro studio che applica la RL a un robot Valkyrie a corpo intero in una simulazione 3D. In questo nuovo sforzo di ricerca, sono stati in grado di generalizzare strategie di bilanciamento simili all'uomo per camminare e altri compiti di locomozione.
"Infine, vorremmo applicare questo quadro gerarchico di combinazione di apprendimento automatico e controllo del robot a veri robot umanoidi, così come ad altre piattaforme robotiche, " ha detto il dottor Li.
© 2018 Tech Xplore