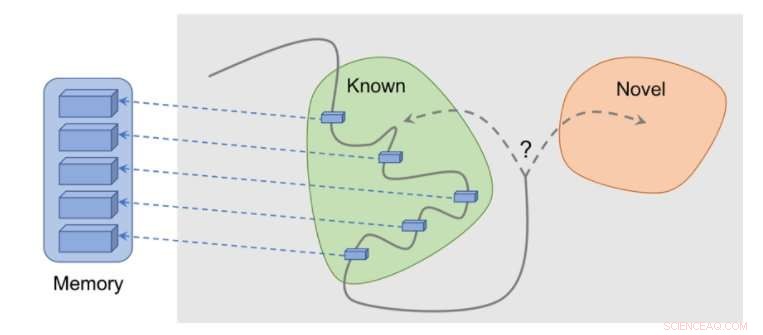
Come funziona il metodo:le osservazioni vengono aggiunte alla memoria, la ricompensa viene calcolata in base alla distanza della nostra osservazione attuale dall'osservazione più simile in memoria. L'agente riceve più ricompensa per aver visto osservazioni che non sono ancora rappresentate in memoria. Credito:Savinov et al.
Diverse attività del mondo reale hanno ricompense sparse e questo pone sfide per lo sviluppo di algoritmi di apprendimento per rinforzo (RL). Una soluzione a questo problema è consentire a un agente di creare autonomamente una ricompensa per se stesso, rendendo le ricompense più dense e più adatte all'apprendimento.
Ad esempio, ispirato dal comportamento curioso con cui gli animali esplorano il loro ambiente, l'osservazione di qualcosa di nuovo da parte di un algoritmo RL potrebbe essere ricompensata con un bonus. Questo bonus, riassunto con la vera ricompensa del compito, consentirebbe quindi agli algoritmi RL di apprendere da una ricompensa combinata.
Ricercatori di DeepMind, Google Brain e l'ETH di Zurigo hanno recentemente ideato un nuovo metodo di curiosità che utilizza la memoria episodica per formare questo bonus di novità. Questo bonus è determinato confrontando le osservazioni correnti e le osservazioni conservate in memoria.
"L'obiettivo principale del nostro lavoro era studiare nuovi modi basati sulla memoria per infondere agli agenti di apprendimento per rinforzo (RL) 'curiosità, ' con cui intendiamo una spinta ad esplorare l'ambiente anche in completa assenza di ricompense, " Tim Lillicrap di DeepMind e Nikolay Savinov di Google Brain hanno dichiarato a TechXplore in una e-mail. "La curiosità è stata affrontata in vari modi dalla comunità di ricerca, ma abbiamo ritenuto che diverse idee potessero trarre vantaggio da ulteriori esplorazioni".
Le idee chiave esplorate in questo recente articolo si basano su uno studio precedente condotto da Savinov, che proponeva una nuova architettura della memoria ispirata alla navigazione dei mammiferi. Questa architettura consente agli agenti di ripetere un percorso attraverso un ambiente utilizzando solo una procedura dettagliata visiva. Il nuovo metodo sviluppato dai ricercatori fa un ulteriore passo avanti, cercando di ottenere una buona esplorazione guidata dalla curiosità.
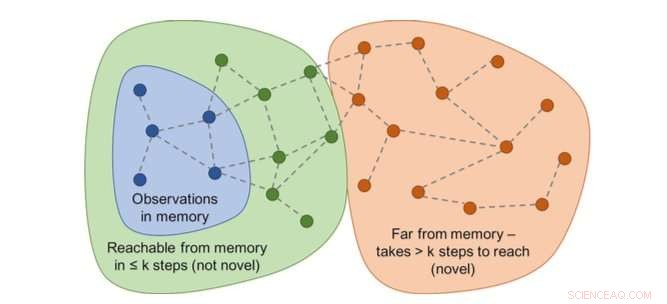
Il grafico delle raggiungibilità determinerebbe la novità. In pratica, questo grafico non è disponibile, quindi viene addestrato un approssimatore di rete neurale per stimare un numero di passaggi tra le osservazioni. Credito:Savinov et al.
"Mentre si agisce, l'agente immagazzina istanze di rappresentazioni di osservazione nella sua memoria episodica, " Dissero Lillicrap e Savinov. "Per determinare se l'osservazione attuale è nuova o meno, è paragonato a quelli in memoria. Se non si trova nulla di simile, l'osservazione corrente è considerata nuova e l'agente è ricompensato, altrimenti ottiene una ricompensa negativa. Questo incoraggia l'agente a esplorare un territorio sconosciuto, come essere curiosi."
I ricercatori hanno scoperto che confrontare coppie di osservazioni potrebbe essere complicato, poiché il controllo di una corrispondenza esatta è in definitiva privo di significato in ambienti realistici. Questo perché nelle situazioni del mondo reale, un agente osserva raramente la stessa cosa due volte.
"Anziché, abbiamo addestrato una rete neurale per prevedere se l'agente può raggiungere l'osservazione corrente da quelle in memoria eseguendo meno azioni rispetto a una soglia fissa; dire, cinque azioni, " Lillicrap e Savinov hanno spiegato. "Le osservazioni all'interno di queste cinque azioni sono considerate simili, mentre quelli che richiedono più azioni per effettuare una transizione sono considerati dissimili".
Lillicrap, Savinov e i loro colleghi hanno testato il loro approccio in VizDoom e DMLab, due ambienti 3D visivamente ricchi. In VizDoom, l'agente ha imparato a navigare con successo verso un obiettivo lontano almeno due volte più velocemente del metodo di curiosità all'avanguardia ICM. In DMLab, l'algoritmo ha generalizzato bene a nuovo, livelli di gioco generati proceduralmente, raggiungere l'obiettivo desiderato almeno due volte più frequentemente dell'ICM nei labirinti di prova con ricompense molto scarse.

Il metodo basato sulla sorpresa (ICM) consiste nell'etichettare costantemente i muri con un gadget di fantascienza simile a un laser invece di esplorare il labirinto. Questo comportamento è simile al cambio di canale descritto in precedenza:anche se il risultato del tagging è teoricamente prevedibile, non è facile e apparentemente richiede una profonda conoscenza della fisica che non è semplice acquisire per un agente generale. Credito:Savinov et al.
"Abbiamo notato un interessante inconveniente in uno dei metodi più popolari per incuriosire gli agenti, " Lillicrap e Savinov hanno detto. "Abbiamo scoperto che questo metodo, sulla base della sorpresa calcolata da un modello in lenta evoluzione che cerca di prevedere cosa accadrà dopo, può tradursi in una risposta di gratificazione immediata da parte dell'agente:invece di risolvere il compito da svolgere, sfrutterà azioni che portano a conseguenze imprevedibili per ottenere una ricompensa immediata."
Questo singolare avvenimento, noto anche come problemi di "couch-potato", implica che un agente trovi modi per gratificarsi istantaneamente sfruttando azioni che portano a conseguenze imprevedibili. Ad esempio, quando gli viene dato un telecomando della TV, l'agente non può fare altro che cambiare canale, anche se il suo compito originario era completamente diverso, come cercare un obiettivo in un labirinto.
"Questa mancanza può essere alleviata usando la memoria episodica insieme a una ragionevole misura di somiglianza di osservazione, che è il nostro contributo, " Lillicrap e Savinov hanno detto. "Questo apre la strada a un'esplorazione più intelligente".

Il nostro metodo mostra una ragionevole esplorazione. Credito:Savinov et al.
Il nuovo metodo della curiosità ideato da Lillicrap, Savinov, e i loro colleghi potrebbero aiutare a replicare abilità simili alla curiosità negli algoritmi RL, consentendo loro di creare autonomamente ricompense per se stessi. Nel futuro, i ricercatori vorrebbero utilizzare la memoria episodica non solo per concedere ricompense, ma anche per la pianificazione delle azioni.
"Per esempio, il contenuto recuperato dalla memoria può essere utilizzato per pensare a dove andare dopo?" Hanno detto Lillicrap e Savinov. "Questa è attualmente una grande sfida scientifica:se risolta, gli agenti sarebbero in grado di adattare rapidamente le strategie di esplorazione a nuovi ambienti, permettendo che l'apprendimento avvenga a un ritmo molto più veloce."
© 2018 Tech Xplore