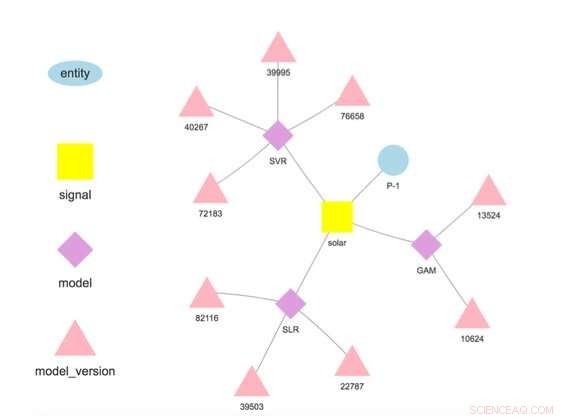
Figura 1. Gerarchia del modello per un'entità e un segnale selezionati. Credito:IBM
Questa settimana alla Conferenza Internazionale sul Data Mining, Lo scienziato di IBM Research-Ireland Francesco Fusco ha dimostrato IBM Research Castor, un sistema per la gestione di dati e modelli di serie temporali su larga scala e sul cloud. Le aziende di oggi corrono sulle previsioni. Che si tratti di un'intuizione di ciò che pensiamo accadrà o del prodotto di un'analisi accuratamente affinata, abbiamo un quadro di ciò che accadrà e agiamo di conseguenza. IBM Research Castor è per le aziende basate sull'IoT che necessitano di centinaia o migliaia di previsioni diverse per le serie temporali. Sebbene il modello per una previsione individuale possa essere piccolo, tenere il passo con la provenienza e le prestazioni di questo numero di modelli può essere una sfida. A differenza dei casi basati sull'intelligenza artificiale che utilizzano un numero limitato di modelli di grandi dimensioni per l'elaborazione delle immagini o il linguaggio naturale, questo lavoro mira alle applicazioni IoT che necessitano di un gran numero di modelli più piccoli.
Il nostro sistema fornisce un insieme ricco ma selettivo di funzionalità per dati e modelli di serie temporali. Acquisisce dati da dispositivi IoT o altre fonti. Fornisce l'accesso ai dati utilizzando la semantica, consentendo agli utenti di recuperare dati come questo:getTimeseries( myServer, "Negozio1234", "reddito orario").
Memorizza i modelli scritti in R o Python per l'addestramento e il punteggio. Ogni modello è associato a un'entità che descrive l'origine dei dati, come "Store1234" sopra, e un segnale che descrive ciò che viene misurato, come "entrate orarie". I modelli sono addestrati e valutati a frequenze definite dall'utente, e contrariamente a molte altre offerte, le previsioni vengono memorizzate automaticamente.
Gli scienziati dei dati distribuiscono modelli implementando un flusso di lavoro in quattro fasi:
Una volta distribuito il modello, il sistema esegue la formazione e il punteggio, memorizzare automaticamente il modello addestrato e i risultati della previsione. I dati utilizzati nella formazione e nel punteggio non devono necessariamente provenire dalla piattaforma, consentendo ai modelli di utilizzare dati provenienti da più fonti. Infatti, questa è una motivazione chiave per il nostro lavoro:fare previsioni a valore aggiunto basate su più fonti di dati. Per esempio, un'azienda può combinare alcuni dei propri dati con dati acquistati da terzi, come le previsioni del tempo, prevedere una quantità di interesse.
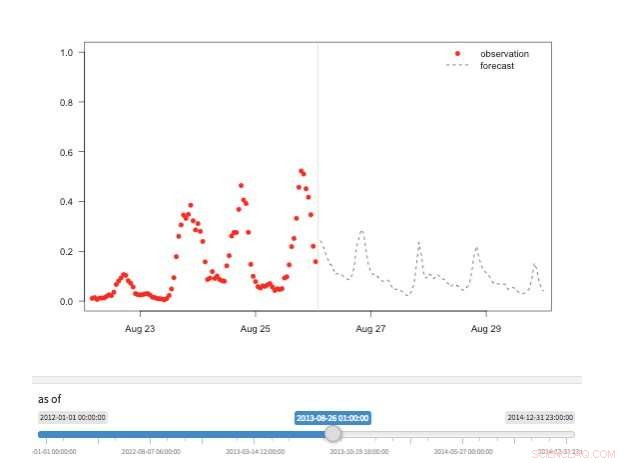
Figura 2. Vista "Macchina del tempo" che mostra le osservazioni e le previsioni disponibili per diversi punti della storia. Credito:IBM
Il nostro sistema memorizza i modelli separati dalla configurazione e dai parametri di runtime. Questa separazione permette la modifica di alcuni dettagli di un modello, come la chiave API per l'accesso ai dati di terze parti o la frequenza del punteggio, senza ridistribuzione. Diversi modelli per la stessa variabile target sono supportati e incoraggiati per consentire il confronto di previsioni da algoritmi diversi. I modelli possono essere concatenati in modo che l'output di un modello formi l'input per un altro come in un insieme. Un modello addestrato su un set di dati specifico rappresenta una versione del modello, che è anche tracciato. In tal modo è possibile stabilire la provenienza dei modelli e delle previsioni (Figura 1).
Sono disponibili diverse visualizzazioni per esplorare i valori di previsione. Naturalmente i valori stessi possono essere recuperati e visualizzati. Supportiamo anche una visualizzazione "macchina del tempo" che mostra le ultime previsioni e le ultime osservazioni (Figura 2). In questa visualizzazione interattiva, l'utente può selezionare diversi punti della storia e vedere quali informazioni erano disponibili in quel momento. Supportiamo anche una visualizzazione dell'evoluzione delle previsioni che mostra previsioni successive per lo stesso momento (Figura 3). In questo modo gli utenti possono vedere come sono cambiate le previsioni man mano che il tempo target si avvicinava.
Sotto il cappuccio, IBM Research Castor fa un uso massiccio dell'elaborazione serverless per fornire elasticità delle risorse e controllo dei costi. Le distribuzioni tipiche vedono i modelli addestrati ogni settimana o ogni mese e valutati ogni ora. Al momento dell'allenamento o del punteggio, viene creata una funzione serverless per ogni modello, consentendo a centinaia di modelli di allenarsi o segnare in parallelo al momento desiderato. Finito questo lavoro, la risorsa informatica scompare finché non è nuovamente necessaria. In un flusso di lavoro più convenzionale, le macchine virtuali o i contenitori cloud sono inattivi quando non sono in uso, ma continuano a generare costi.
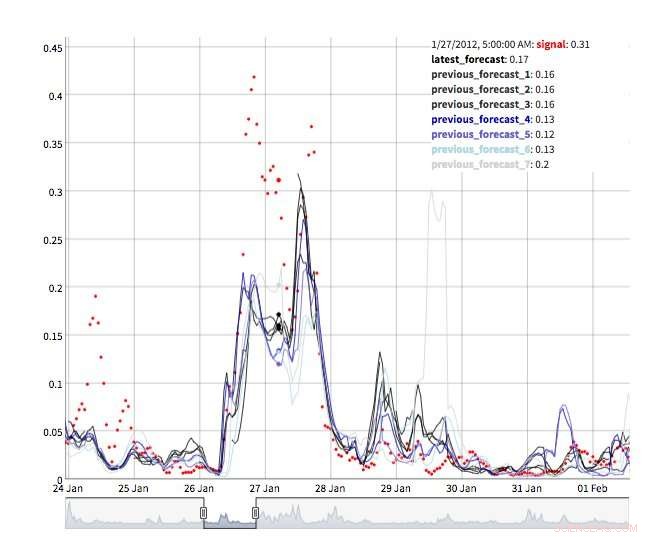
Figura 3. Evoluzione delle previsioni. Credito:IBM
IBM Research Castor si distribuisce in modo nativo su IBM Cloud utilizzando i servizi più recenti come DashDB di IBM, Comporre, Funzioni cloud, e Kubernetes per fornire un sistema robusto e affidabile. Con un account autorizzato su IBM Cloud, IBM Research Castor si implementa in pochi minuti, rendendolo ideale per proof-of-concept così come per progetti di lunga durata. Vengono forniti pacchetti client/SDK per Python e R in modo che i data scientist possano essere operativi rapidamente in un ambiente familiare e i team di visualizzazione possano sfruttare framework familiari come Django e Shiny. Se quelli non si adattano alla tua applicazione, è disponibile anche l'API di messaggistica basata su JSON.
Questa storia è stata ripubblicata per gentile concessione di IBM Research. Leggi la storia originale qui.