
Un sistema di "computer vision" sviluppato presso l'UCLA è in grado di identificare gli oggetti basandosi solo su scorci parziali, come usando questi frammenti di foto di una moto. Credito:Università della California, Los Angeles
Gli ingegneri dell'UCLA e della Stanford University hanno dimostrato un sistema informatico in grado di scoprire e identificare gli oggetti del mondo reale che "vede" sulla base dello stesso metodo di apprendimento visivo utilizzato dagli esseri umani.
Il sistema è un progresso in un tipo di tecnologia chiamata "visione artificiale, " che consente ai computer di leggere e identificare le immagini visive. Potrebbe essere un passo importante verso i sistemi generali di intelligenza artificiale:computer che apprendono da soli, sono intuitivi, prendere decisioni basate sul ragionamento e interagire con gli umani in un modo molto più umano. Sebbene gli attuali sistemi di visione artificiale con intelligenza artificiale siano sempre più potenti e capaci, sono specifici per il compito, il che significa che la loro capacità di identificare ciò che vedono è limitata da quanto sono stati addestrati e programmati dagli umani.
Anche i migliori sistemi di visione artificiale di oggi non sono in grado di creare un'immagine completa di un oggetto dopo averne visto solo alcune parti e i sistemi possono essere ingannati visualizzando l'oggetto in un ambiente sconosciuto. Gli ingegneri mirano a creare sistemi informatici con tali capacità, proprio come gli umani possono capire che stanno guardando un cane, anche se l'animale si nasconde dietro una sedia e sono visibili solo le zampe e la coda. umani, Certo, può anche intuire facilmente dove si trovano la testa del cane e il resto del suo corpo, ma questa capacità sfugge ancora alla maggior parte dei sistemi di intelligenza artificiale.
Gli attuali sistemi di visione artificiale non sono progettati per apprendere da soli. Devono essere addestrati esattamente su cosa imparare, di solito esaminando migliaia di immagini in cui gli oggetti che stanno cercando di identificare sono etichettati per loro. computer, Certo, inoltre non possono spiegare la loro logica per determinare cosa rappresenta l'oggetto in una foto:i sistemi basati sull'intelligenza artificiale non costruiscono un'immagine interna o un modello di buon senso degli oggetti appresi come fanno gli umani.
Il nuovo metodo degli ingegneri, descritto nel Atti dell'Accademia Nazionale delle Scienze , mostra un modo per aggirare queste carenze.
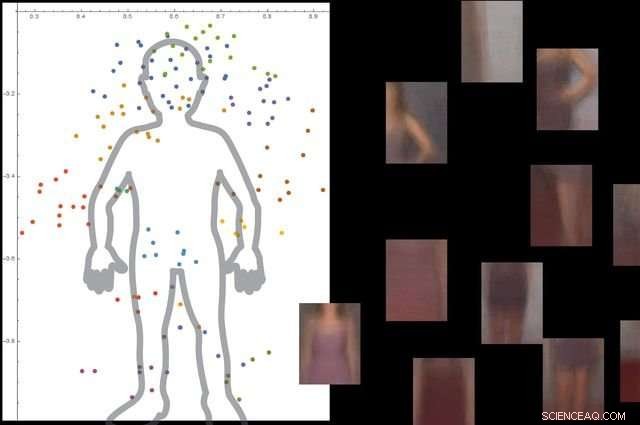
Il sistema capisce cos'è un corpo umano guardando migliaia di immagini con persone in esse, e quindi ignorando gli oggetti di sfondo non essenziali. Credito:Università della California, Los Angeles
L'approccio si compone di tre grandi fasi. Primo, il sistema scompone un'immagine in piccoli pezzi, che i ricercatori chiamano "viewlet". Secondo, il computer apprende come questi viewlet si incastrano per formare l'oggetto in questione. E infine, guarda quali altri oggetti ci sono nell'area circostante, e se le informazioni su quegli oggetti sono rilevanti o meno per descrivere e identificare l'oggetto primario.
Per aiutare il nuovo sistema a "imparare" di più come gli umani, gli ingegneri hanno deciso di immergerlo in una replica Internet dell'ambiente in cui vivono gli esseri umani.
"Fortunatamente, Internet fornisce due cose che aiutano un sistema di visione artificiale ispirato dal cervello ad apprendere nello stesso modo in cui lo fanno gli umani, " disse Vwani Roychowdhury, un professore dell'UCLA di ingegneria elettrica e informatica e ricercatore principale dello studio. "Uno è una ricchezza di immagini e video che ritraggono gli stessi tipi di oggetti. Il secondo è che quegli oggetti sono mostrati da molte prospettive:oscurati, a volo d'uccello, da vicino e sono collocati in tutti i diversi tipi di ambienti."
Per sviluppare il quadro, i ricercatori hanno tratto spunti dalla psicologia cognitiva e dalle neuroscienze.
"Cominciando da bambini, impariamo cos'è una cosa perché ne vediamo molti esempi, in molti contesti, " Roychowdhury ha detto. "Che l'apprendimento contestuale è una caratteristica fondamentale del nostro cervello, e ci aiuta a costruire modelli robusti di oggetti che fanno parte di una visione del mondo integrata in cui tutto è funzionalmente connesso".
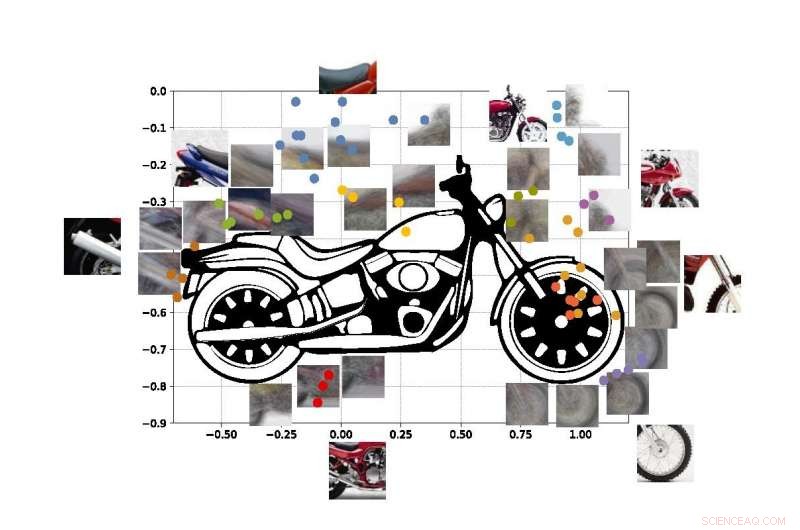
I punti colorati nella figura mostrano le coordinate stimate dei centri di alcuni viewlet della nostra moto SUVM. Ogni rappresentazione viewlet è un composto di viste/patch di esempio che hanno aspetti simili. Credito:Lichao Chen, Tianyi Wang, e Vwani Roychowdhury (Università della California, Los Angeles).
I ricercatori hanno testato il sistema con circa 9, 000 immagini, ciascuno che mostra persone e altri oggetti. La piattaforma è stata in grado di costruire un modello dettagliato del corpo umano senza una guida esterna e senza etichettare le immagini.
Gli ingegneri hanno eseguito test simili utilizzando immagini di motociclette, automobili e aerei. In tutti i casi, il loro sistema ha funzionato meglio o almeno altrettanto rispetto ai tradizionali sistemi di visione artificiale che sono stati sviluppati con molti anni di formazione.
Il co-autore senior dello studio è Thomas Kailath, un professore emerito di ingegneria elettrica a Stanford che è stato consigliere di dottorato di Roychowdhury negli anni '80. Altri autori sono gli ex studenti di dottorato dell'UCLA Lichao Chen (ora ingegnere di ricerca presso Google) e Sudhir Singh (che ha fondato un'azienda che costruisce compagni didattici robotici per bambini).
Singh, Roychowdhury e Kailath hanno precedentemente lavorato insieme per sviluppare uno dei primi motori di ricerca visivi automatizzati per la moda, lo StileEye ora chiuso, che ha dato origine ad alcune delle idee di base alla base della nuova ricerca.














