Attestazione:Prasad, Das &Bhowmick.
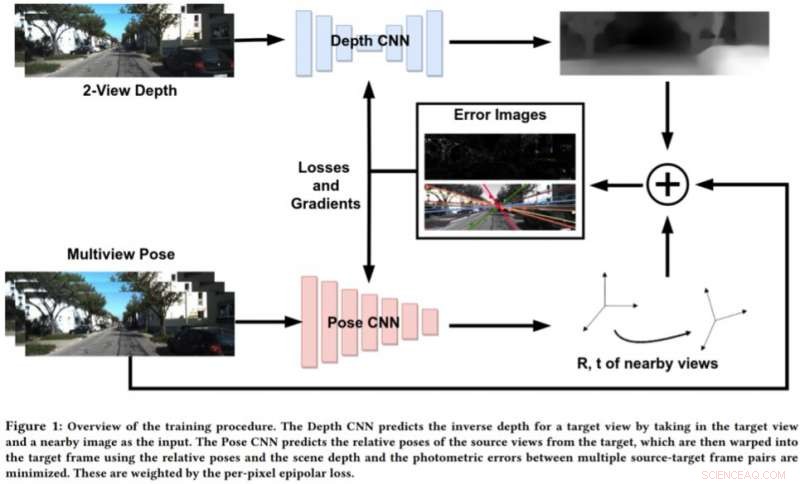
I ricercatori del gruppo Embedded Systems and Robotics presso TCS Research &Innovation hanno recentemente sviluppato una rete di profondità a due viste per dedurre la profondità e il movimento dell'ego da sequenze monoculare consecutive. Il loro approccio, presentato in un articolo pre-pubblicato su arXiv, incorpora anche i vincoli epipolari, che migliorano la comprensione geometrica della rete.
"La nostra idea principale era quella di cercare di prevedere la profondità in termini di pixel e il movimento della fotocamera direttamente da singole sequenze di immagini, "Dottor Brojeshwar Bhowmick, uno dei ricercatori che ha condotto lo studio, ha detto a TechXplore. "Tradizionalmente, la struttura da algoritmi di ricostruzione basati sul movimento fornisce output di profondità sparsa per punti di interesse salienti nell'immagine, che vengono tracciati su più immagini utilizzando la geometria multivista. Con il deep learning che sta guadagnando popolarità nelle attività di visione artificiale, abbiamo pensato di sfruttare i metodi esistenti per aiutare la nostra causa affrontando il problema in modo più fondamentale utilizzando una combinazione di concetti della geometria epipolare e dell'apprendimento profondo".
La maggior parte degli approcci di apprendimento profondo esistenti per prevedere la profondità monoculare e il movimento dell'ego ottimizza la coerenza fotometrica nelle sequenze di immagini deformando una vista in un'altra. Deducendo la profondità da una singola vista, però, questi metodi potrebbero non riuscire a catturare la relazione tra i pixel e quindi a fornire adeguate corrispondenze di pixel.
Per affrontare i limiti di questi approcci, Bhowmick e i suoi colleghi hanno sviluppato un nuovo approccio che combina la visione artificiale geometrica e i paradigmi dell'apprendimento profondo. Il loro approccio utilizza due reti neurali, uno per prevedere la profondità di una singola vista di riferimento e uno per prevedere le pose relative di un insieme di viste rispetto alla vista di riferimento.

Attestazione:Prasad, Das &Bhowmick.
"La scena dell'immagine target può essere ricostruita da una qualsiasi delle pose date deformandole in base alla profondità e alle pose relative, " Bhowmick ha spiegato. "Data questa immagine ricostruita e l'immagine di riferimento, calcoliamo l'errore nelle intensità dei pixel, che funge da nostra principale perdita. Aggiungiamo la novità di utilizzare la perdita epipolare per pixel, un concetto dalla geometria multivista, nella perdita complessiva, che garantisce corrispondenze migliori e ha il vantaggio aggiuntivo di non considerare gli oggetti in movimento nella scena che potrebbero altrimenti deteriorare l'apprendimento."
Invece di prevedere la profondità analizzando una singola immagine, questo nuovo approccio funziona analizzando una coppia di immagini da un video e apprendendo le relazioni tra i pixel per prevedere la profondità. Assomiglia in qualche modo ai tradizionali algoritmi SLAM/SfM, che può osservare i movimenti dei pixel nel tempo.
"I risultati più significativi del nostro studio sono che l'uso di due viste per prevedere la profondità funziona meglio di una singola immagine, e che anche una debole applicazione delle corrispondenze a livello di pixel tramite vincoli epipolari funziona bene, " Bhowmick ha detto. "Una volta che tali metodi maturano e migliorano nella generalizzabilità, potremmo applicarli per la percezione sui droni, dove si vorrebbe estrarre la massima informazione sensoriale consumando meno energia possibile, che può essere ottenuto utilizzando una singola fotocamera."
Nelle valutazioni preliminari, i ricercatori hanno scoperto che il loro metodo potrebbe prevedere la profondità con maggiore precisione rispetto agli approcci esistenti, producendo stime di profondità più nitide e stime di posa avanzate. Però, attualmente, il loro approccio può eseguire solo inferenze a livello di pixel. Il lavoro futuro potrebbe affrontare questa limitazione integrando la semantica della scena nel modello, che potrebbe portare a migliori correlazioni tra gli oggetti nella scena e le stime sia della profondità che del movimento dell'ego.
"Stiamo ulteriormente indagando sulla generalizzabilità di questo metodo e di altri metodi simili su varie scene, sia da interno che da esterno, " Bhowmick ha detto. "Attualmente, la maggior parte dei lavori si comporta bene sui dati esterni, come i dati di guida, ma si comportano molto male su sequenze indoor con movimenti arbitrari."
© 2019 Scienza X Rete