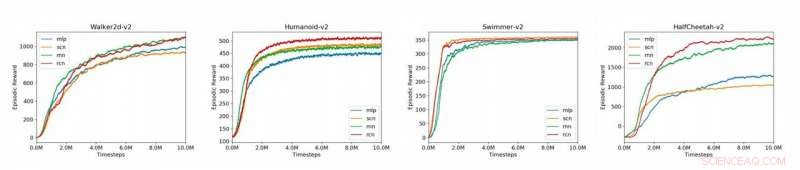
Grafici che confrontano i modelli di riferimento (MLP, SCN, RNN, RCN) per i 4 ambienti MuJoCo presentati nel paper (Humanoid-v2, HalfCheetah-v2, Walker2d-v2, Nuotatore-v2). Credito:Liu et al.
I generatori di pattern centrali (CPG) sono circuiti neurali biologici in grado di produrre output ritmici coordinati senza richiedere input ritmici. I CPG sono responsabili della maggior parte dei movimenti ritmici osservati negli organismi viventi, come camminare, respirare o nuotare.
Gli strumenti per modellare efficacemente gli output ritmici quando vengono forniti input aritmici potrebbero avere importanti applicazioni in una varietà di campi, comprese le neuroscienze, robotica e medicina. Nell'apprendimento per rinforzo, la maggior parte delle reti esistenti utilizzate per modellare le attività delle locomotive, come i modelli di riferimento del perceptron multistrato (MLP), non riescono a generare uscite ritmiche in assenza di ingressi ritmici.
Recenti studi hanno proposto l'uso di architetture in grado di suddividere la politica di una rete in componenti lineari e non lineari, come le reti di controllo strutturate (SCN), che si è scoperto che superano le MLP in una varietà di ambienti. Un SCN comprende un modello lineare per il controllo locale e un modulo non lineare per il controllo globale, i cui risultati sono combinati per produrre l'azione politica. Basandosi sul lavoro precedente con reti neurali ricorrenti (RNN) e SCN, un team di ricercatori della Stanford University ha recentemente ideato un nuovo approccio per modellare i CPG nell'apprendimento per rinforzo.
"I CPG sono circuiti neurali biologici in grado di produrre output ritmici in assenza di input ritmici, "Ademi Adeniji, uno dei ricercatori che ha condotto lo studio, ha detto a Tech Xplore. "Gli approcci esistenti per la modellazione dei CPG nell'apprendimento per rinforzo includono il percettrone multistrato (MLP), un semplice, rete neurale completamente connessa, e la rete di controllo strutturata (SCN), che ha moduli separati per il controllo locale e globale. Il nostro obiettivo di ricerca era migliorare queste linee di base consentendo al modello di catturare osservazioni precedenti, rendendolo meno soggetto a errori dovuti al rumore in ingresso."

Screenshot dell'ambiente HalfCheetah. Credito:Liu et al.
La rete di controllo ricorrente (RCN) sviluppata da Adeniji e dai suoi colleghi adotta l'architettura di un SCN, ma utilizza un RNN vaniglia per il controllo globale. Ciò consente al modello di acquisire localmente, controllo globale e dipendente dal tempo.
"Come SCN, il nostro RCN suddivide il flusso di informazioni in moduli lineari e non lineari, "Nathaniel Lee, uno dei ricercatori che ha condotto lo studio, ha detto a TechXplore. "Intuitivamente, il modulo lineare, effettivamente una trasformazione lineare, apprende le interazioni locali, mentre il modulo non lineare apprende le interazioni globali."
Gli approcci SCN utilizzano un MLP come modulo non lineare, mentre l'RCN ideato dai ricercatori sostituisce questo modulo con un RNN. Di conseguenza, il loro modello acquisisce una "memoria" di osservazioni passate, codificato dallo stato nascosto dell'RNN, che poi utilizza per generare azioni future.
I ricercatori hanno valutato il loro approccio sulla piattaforma OpenAI Gym, un ambiente fisico per l'apprendimento per rinforzo, così come su dinamiche multiarticolari con compiti a contratto (Mu-JoCo). Il loro RCN ha eguagliato o ha superato altri MLP e SCN di base in tutti gli ambienti testati, apprendere efficacemente il controllo locale e globale mentre acquisisce modelli da sequenze precedenti.

Screenshot dell'ambiente umanoide. Credito:Liu et al.
"I CPG sono responsabili di un vasto numero di modelli biologici ritmici, "Jason Zhao, un altro ricercatore coinvolto nello studio, disse. "La capacità di modellare il comportamento CPG può essere applicata con successo a campi come la medicina e la robotica. Speriamo anche che la nostra ricerca evidenzi l'efficacia del controllo locale/globale, nonché le architetture ricorrenti per modellare la generazione di modelli centrali nell'apprendimento per rinforzo".
I risultati raccolti dai ricercatori confermano il potenziale delle strutture simili a SCN per modellare i CPG per l'apprendimento per rinforzo. Il loro studio suggerisce anche che gli RNN sono particolarmente efficaci per modellare le attività delle locomotive e che la separazione dei moduli di controllo lineari e non lineari può migliorare significativamente le prestazioni di un modello.
"Finora, abbiamo addestrato il nostro modello solo utilizzando strategie evolutive (ES), un ottimizzatore off-gradiente, " ha detto Vincenzo Liu, uno dei ricercatori coinvolti nello studio. "Nel futuro, abbiamo in programma di esplorare le sue prestazioni durante l'addestramento con l'ottimizzazione della politica prossimale (PPO), un ottimizzatore a gradiente. Inoltre, i progressi nell'elaborazione del linguaggio naturale hanno dimostrato che le reti neurali convoluzionali sono efficaci sostituti delle reti neurali ricorrenti, sia in termini di prestazioni che di calcolo. Potremmo quindi considerare di sperimentare un'architettura di rete neurale a ritardo temporale, che applica la convoluzione 1-D lungo l'asse temporale delle osservazioni passate."
© 2019 Scienza X Rete














