Dieci pagine di riviste Dada classificate come “Dada” dalla rete neurale. Credito:Cornell University
Per fare una poesia dadaista, l'artista Tristan Tzara una volta disse:ritaglia ogni parola di un articolo di giornale. Metti le parole in un sacchetto e agita. Togli le parole dalla borsa una alla volta, e scrivili in questo ordine.
Questo metodo del "sacco di parole" non è del tutto diverso da come gli algoritmi di intelligenza artificiale identificano parole e immagini, suddividendoli in componenti un passo alla volta. La somiglianza ha ispirato i ricercatori di Cornell a esplorare se un algoritmo potesse essere addestrato per differenziare le riviste dadaiste digitalizzate dalle riviste d'avanguardia non Dada - un compito formidabile, visto che molti considerano Dada intrinsecamente indefinibile.
Ma l'algoritmo, una rete neurale convoluzionale tipicamente utilizzata per identificare immagini comuni, ha funzionato meglio del casuale. Ha identificato correttamente le pagine del diario Dada il 63% delle volte e le pagine non Dada l'86% delle volte.
"Il nostro obiettivo non è necessariamente ottenere la risposta 'giusta', ma piuttosto usare il calcolo per fornire un alieno, prospettiva defamiliarizzata, " hanno scritto i ricercatori in "Computational Cut-Ups:The Influence of Dada, "che ha pubblicato nel Rivista di studi periodici moderni a gennaio. "Può uno strumento progettato per identificare i cani essere riproposto per esplorare l'avanguardia?"
Hanno anche cercato di fornire un esempio di come potrebbero essere analizzate grandi raccolte di immagini, ha detto Laure Thompson, uno studente di dottorato in informatica, che ha co-autore dell'articolo con David Mimno, assistente professore di scienze dell'informazione.
Il text mining - la ricerca di grandi corpi di testo digitalizzato per determinate parole o frasi - è diventato ampiamente utilizzato nelle discipline umanistiche digitali, ma la ricerca di immagini è molto più difficile.
"Il testo ha funzioni molto utili:sono note come parole. E possiamo vederle molto rapidamente a causa degli spazi tra di loro, " ha detto Thompson. "Mentre un'immagine per un computer è solo una grande matrice di numeri, e questo è noto per non essere molto significativo."
Thompson e Mimno hanno addestrato la loro rete neurale su riviste dadaiste dall'archivio digitale Blue Mountain della Princeton University. Senza sapere nulla di Dada - un movimento d'avanguardia emerso in Europa dopo la prima guerra mondiale che ha cercato di capovolgere il materialismo e le convenzioni - l'algoritmo ha quindi tentato di classificare circa 33, 000 pagine di diario come Dada o non-Dada.
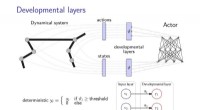
La rete impara a identificare le immagini attraverso strati progressivamente più complessi:i primi strati potrebbero individuare strutture semplici come bordi o angoli retti, mentre il livello finale tenterà di etichettare l'immagine come, dire, un cane da pastore.
In questo studio, il modello ha analizzato il penultimo strato, che comprendeva una serie di numeri piuttosto che etichette come "cane da pastore". Mimno e Thompson si riferivano a questi strati numerici come "ritagli computazionali, " un cenno al concetto dadaista di "borsa di parole".
L'algoritmo "può essere quasi l'antitesi dell'arte, ma è anche giocare con tutte queste metodologie che apparivano in Dada stesso, "ha detto Thompson.
Sebbene non sapessero come l'algoritmo prendesse le sue decisioni, i ricercatori hanno lavorato a ritroso dai risultati. Hanno scoperto che la rete associava Dada al colore rosso, alto contrasto e bordi prominenti. Tendeva a classificare le pagine con immagini e fotografie realistiche come non-Dada, hanno trovato.
Degli altri generi analizzati dall'algoritmo, spesso identificava erroneamente il cubismo come Dada - il che aveva senso per i ricercatori, poiché il cubismo ha fortemente influenzato l'arte dada.
Prima di condurre l'esperimento Dada, i ricercatori hanno testato il loro concetto su pagine contenenti musica. L'algoritmo ha identificato il 67 per cento dei 3, 450 pagine con spartiti musicali come "musica, " e il 96 per cento dei 55, 007 pagine senza musica come "non musica". Hanno scoperto che il modello tendeva a classificare le pagine in modo ordinato, tavoli orizzontali come musica, e pagine con colori o immagini come "non musica".
"Se vuoi proiettare sentimenti su questi modelli, sono piuttosto pigri, " ha detto Thompson. Ad esempio, i ricercatori hanno scoperto che se si addestra un modello per identificare le immagini dei pesci, e tutte le immagini fornite mostrano persone che tengono in mano dei pesci, probabilmente classificherà tutte le immagini con persone che tengono cose come pesci.
Le classificazioni del modello fanno luce su quali caratteristiche possono definire Dada, i ricercatori hanno detto, anche se l'idea di usare una macchina per vedere l'arte è semplicistica e forse assurda.
"Questo è in parte uno sforzo ironico. Non stiamo cercando di essere super seri, che questo classificatore batterà tutti gli storici dell'arte nell'identificare ciò che rende veramente Dada Dada, "Ha detto Thompson. "La modella non sa nulla di Dada, ma può ancora aiutare a fornire un'ulteriore prospettiva nel pensarci".