
I ricercatori considerano il problema della navigazione da una posizione di partenza a una posizione di arrivo. Il loro approccio (WayPtNav) consiste in un modulo di percezione basato sull'apprendimento e un modulo di pianificazione basato su modelli dinamici. Il modulo di percezione prevede un waypoint basato sull'attuale osservazione dell'immagine RGB in prima persona. Questo waypoint viene utilizzato dal modulo di pianificazione basato su modello per progettare un controller che regoli in modo uniforme il sistema fino a questo waypoint. Questo processo viene ripetuto per l'immagine successiva finché il robot non raggiunge l'obiettivo. Credito:Bansal e al.
I ricercatori della UC Berkeley e di Facebook AI Research hanno recentemente sviluppato un nuovo approccio per la navigazione dei robot in ambienti sconosciuti. Il loro approccio, presentato in un articolo pre-pubblicato su arXiv, combina tecniche di controllo basate su modelli con la percezione basata sull'apprendimento.
Lo sviluppo di strumenti che consentono ai robot di navigare negli ambienti circostanti è una sfida chiave e continua nel campo della robotica. Negli ultimi decenni, i ricercatori hanno cercato di affrontare questo problema in vari modi.
La comunità di ricerca sul controllo ha principalmente studiato la navigazione per un agente (o sistema) noto all'interno di un ambiente noto. In questi casi, sono disponibili un modello dinamico dell'agente e una mappa geometrica dell'ambiente in cui navigherà, quindi è possibile utilizzare schemi di controllo ottimale per ottenere traiettorie lisce e prive di collisioni affinché il robot raggiunga la posizione desiderata.
Questi schemi sono tipicamente usati per controllare un certo numero di sistemi fisici reali, come aeroplani o robot industriali. Però, questi approcci sono alquanto limitati, in quanto richiedono una conoscenza esplicita dell'ambiente in cui un sistema navigherà. Nella comunità della ricerca sull'apprendimento, d'altra parte, la navigazione robotica è generalmente studiata per un agente sconosciuto che esplora un ambiente sconosciuto. Ciò significa che un sistema acquisisce criteri per mappare direttamente le letture dei sensori di bordo per controllare i comandi in modo end-to-end.
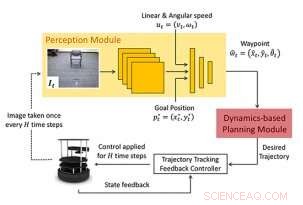
Quadro proposto:il nuovo approccio alla navigazione consiste in un modulo di percezione basato sull'apprendimento e un modulo di pianificazione basato su modelli dinamici. Il modulo di percezione consiste in una CNN che emette uno stato successivo o un waypoint desiderati. Questo waypoint viene utilizzato dal modulo di pianificazione basato su modello per progettare un controller per regolare agevolmente il sistema sul waypoint. Credito:Bansal e al.
Questi approcci possono avere diversi vantaggi, in quanto consentono di apprendere le politiche senza alcuna conoscenza del sistema e dell'ambiente in cui navigherà. Ciò nonostante, studi precedenti suggeriscono che queste tecniche non si generalizzano bene tra diversi agenti. Inoltre, l'apprendimento di tali politiche spesso richiede un vasto numero di campioni di formazione.
"In questo documento, studiamo la navigazione del robot in ambienti statici sotto l'assunzione di una perfetta misurazione dello stato del robot, " I ricercatori hanno scritto nel loro articolo. "Facciamo l'osservazione cruciale che i problemi più interessanti coinvolgono un sistema noto in un ambiente sconosciuto. Questa osservazione motiva la progettazione di un approccio fattorizzato che utilizza l'apprendimento per affrontare ambienti sconosciuti e sfrutta il controllo ottimale utilizzando dinamiche di sistema note per produrre una locomozione fluida".
Il team di ricercatori dell'UC Berkeley e di Facebook ha addestrato un modello basato sulla rete neurale convoluzionale (CNN) su politiche di alto livello, che utilizzano le attuali osservazioni di immagini RGB per produrre una sequenza di stati intermedi, o 'waypoint'. Questi waypoint alla fine guidano un robot nella posizione desiderata seguendo un percorso privo di collisioni, in ambienti precedentemente sconosciuti.
Il loro approccio, navigazione basata su waypoint doppiato (WayPtNav), essenzialmente accoppia tecniche di controllo basate su modelli con la percezione basata sull'apprendimento. Il modulo di percezione basato sull'apprendimento genera waypoint, che guidano il robot verso la sua posizione di destinazione attraverso un percorso privo di collisioni. Il pianificatore basato su modelli, d'altra parte, utilizza questi waypoint per generare una traiettoria fluida e dinamicamente fattibile, che viene quindi eseguito sul sistema utilizzando il controllo in retroazione.
I ricercatori hanno valutato il loro approccio su un banco di prova hardware, chiamato TurtleBot2. I loro test hanno raccolto risultati molto promettenti, con WayPtNav che consente la navigazione in ambienti disordinati e dinamici, mentre supera anche un approccio di apprendimento end-to-end.
"I nostri esperimenti in ambienti disordinati simulati del mondo reale e su un veicolo terrestre reale dimostrano che l'approccio proposto può raggiungere le posizioni degli obiettivi in modo più affidabile ed efficiente in ambienti nuovi rispetto a un'alternativa basata sull'apprendimento puramente end-to-end, " hanno scritto i ricercatori.
Il nuovo approccio presentato da questo team di ricercatori potrebbe migliorare la navigazione dei robot in nuovi ambienti interni. Studi futuri potrebbero cercare di migliorare ulteriormente WayPtNav, affrontare alcuni dei suoi limiti attuali.
"Il nostro approccio proposto presuppone una stima dello stato del robot perfetto e impiega una politica puramente reattiva, " hanno spiegato i ricercatori. "Questi presupposti e scelte potrebbero non essere ottimali, soprattutto per compiti a lungo raggio. Incorporare la memoria spaziale o visiva per affrontare queste limitazioni sarebbe fruttuose direzioni future".
© 2019 Scienza X Rete














