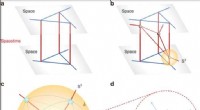
Pagina da una versione francese del "Narrenschiff" (La nave dei folli). Questi vecchi caratteri possono essere convertiti in modo affidabile in testo leggibile dal computer con OCR4all. Credito:Biblioteca statale e universitaria di Dresda, CC BY-SA 4.0
Gli storici e gli studiosi di altre discipline umanistiche hanno spesso a che fare con oggetti di ricerca difficili:opere a stampa secolari, difficili da decifrare e spesso in uno stato di conservazione insoddisfacente. Molti di questi documenti sono stati ora digitalizzati, di solito fotografati o scansionati, e sono disponibili online in tutto il mondo. Per scopi di ricerca, questo è già un passo avanti.
Però, c'è ancora una sfida da vincere:portare i vecchi caratteri digitalizzati in una forma moderna con un software di riconoscimento del testo leggibile sia per i non specialisti che per i computer. Scienziati del Centro di Filologia e Digitalità della Julius-Maximilians-Universität Würzburg (JMU) in Baviera, Germania, hanno dato un contributo significativo all'ulteriore sviluppo in questo campo.
Con OCR4all, il team di ricerca JMU sta mettendo a disposizione della comunità scientifica un nuovo strumento. Converte le stampe storiche digitalizzate con un tasso di errore inferiore all'uno percento in testi leggibili da computer. E offre un'interfaccia utente grafica che non richiede competenze IT. Con strumenti precedenti di questo tipo, la facilità d'uso non era sempre scontata, poiché gli utenti dovevano lavorare principalmente con i comandi di programmazione.
Sviluppato in collaborazione con le discipline umanistiche
Il nuovo strumento OCR4all è stato sviluppato sotto la direzione di Christian Reul insieme ai suoi colleghi di informatica, il professor Frank Puppe (Chair of Artificial Intelligence and Applied computer science) e Christoph Wick, nonché Uwe Springmann (esperto di Digital Humanities) e numerosi studenti e assistenti.
OCR4all nasce dal progetto JMU Kallimachos, che è finanziato dal Ministero federale tedesco dell'istruzione e della ricerca. Questa cooperazione tra discipline umanistiche e informatica sarà proseguita e istituzionalizzata nel nuovo JMU Center for Philology and Digitality.
Nello sviluppo di OCR4all, scienziati informatici hanno collaborato con le discipline umanistiche della JMU, inclusi studi tedeschi e romanzeschi e studi di letteratura nel progetto "Narragonien digital". L'obiettivo era quello di digitalizzare il "Narrenschiff, " una satira morale di Sebastian Brant, un bestseller del XV secolo tradotto in molte lingue. Per di più, OCR4all è stato spesso utilizzato nel Kolleg della JMU "Medieval and Early Modern Times".
OCR4all è disponibile gratuitamente al pubblico sulla piattaforma GitHub (con istruzioni ed esempi):https://github.com/OCR4all
Ogni tipografia aveva il suo carattere
Christian Reul spiega le sfide legate allo sviluppo di OCR4all:Il riconoscimento automatico del testo (OCR =Optical Character Recognition) ha funzionato molto bene per i caratteri moderni ormai da qualche tempo. Però, questo non è stato ancora il caso per i caratteri storici.
"Uno dei problemi più grandi era la tipografia, " dice Reul. Uno dei motivi è che i primi stampatori del XV secolo non usavano caratteri uniformi. "I loro timbri da stampa erano tutti intagliati da loro stessi, ogni tipografia aveva praticamente le sue lettere."
Tassi di errore inferiori all'uno percento
Sia "e" o "c, " se "v" o "r" - spesso non è facile distinguere nelle vecchie stampe, ma il software può imparare a riconoscere tali sottigliezze. Fare così, deve essere addestrato su materiale campione. Nel suo lavoro, Reul ha sviluppato metodi per rendere la formazione più efficiente. In un caso studio con sei stampe storiche dagli anni 1476 al 1572, il tasso medio di errore nel riconoscimento automatico del testo è stato ridotto dal 3,9 all'1,7 percento.
Non solo è stata migliorata la metodologia, Christoph Wick, informatico della JMU, ha ulteriormente perfezionato in modo decisivo la componente tecnica sviluppando lo strumento Calamari OCR, che è anche disponibile gratuitamente e da allora è stato completamente integrato in OCR4all, promettendo risultati ancora migliori. Ora, anche per le opere a stampa più antiche, tassi di errore inferiori all'uno per cento possono essere raggiunti in generale.
Progetti lessicali
Reul ha anche convinto i partner esterni della qualità della ricerca OCR di Würzburg. In collaborazione con lo "Zentrum für digitale Lexikographie der deutschen Sprache" (Berlino), Il "Wörterbuch der deutschen Sprache" (Dizionario della lingua tedesca) di Daniel Sanders è stato indicizzato digitalmente, ed è attualmente in preparazione una pubblicazione scientifica su questo lavoro. Le varie righe di questo testo contengono spesso caratteri diversi, rappresentare diverse informazioni semantiche. Qui, l'approccio esistente al riconoscimento dei caratteri è stato esteso in modo tale che non solo il testo, ma anche la tipografia e quindi la complessa struttura dei contenuti del lessico possano essere riprodotti in modo molto preciso.
L'informatico di Würzburg completerà presto la sua tesi di dottorato, ma è anche disposto a continuare a lavorare con l'OCR in futuro:"L'informatica dietro l'OCR è estremamente eccitante, " dice. Un possibile progetto nel prossimo futuro:i creatori di "Idiotikon, " un dizionario della lingua svizzero-tedesca, hanno indicato il loro interesse per la collaborazione poiché potrebbero aver bisogno delle conoscenze specialistiche del Würzburg.