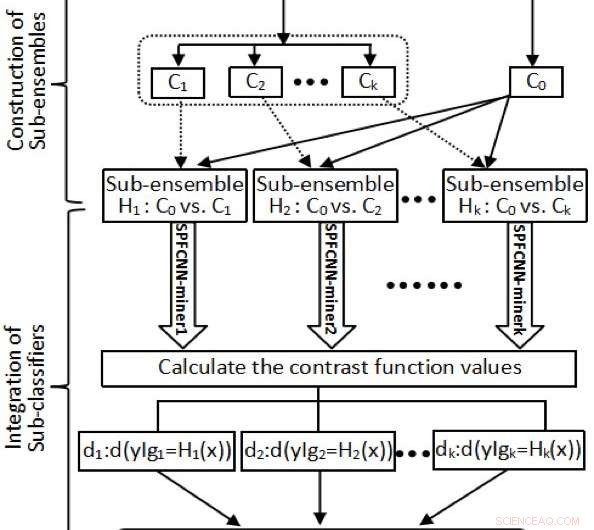
Il diagramma di flusso se MLF. Credito:Zhao et al.
I ricercatori dell'Università di Chongqing in Cina hanno recentemente sviluppato un classificatore di meta-apprendimento sensibile ai costi che può essere utilizzato quando i dati di formazione disponibili sono ad alta dimensione o limitati. Il loro classificatore, chiamato SPFCNN-Miner, è stato presentato in un articolo pubblicato su Elsevier's Sistemi informatici di futura generazione .
Sebbene i classificatori di apprendimento automatico si siano dimostrati efficaci in una varietà di compiti, per ottenere risultati ottimali, spesso richiedono una grande quantità di dati di addestramento. Quando i dati sono ad alta dimensionalità, limitato o sbilanciato, la maggior parte dei metodi di classificazione non è in grado di ottenere prestazioni soddisfacenti. Nel loro studio, il team di ricercatori dell'Università di Chongqing si è proposto di comprendere meglio queste sfide relative ai dati e di sviluppare un classificatore in grado di superarle.
"Abbiamo utilizzato reti siamesi adatte per l'apprendimento a breve termine in cui sono disponibili pochi dati per apprendere dati ad alta dimensionalità e limitati, e applicare l'idea di combinare approcci "superficiali" e "profondi" per progettare reti siamesi parallele in grado di estrarre meglio funzionalità semplici o complesse da una varietà di set di dati, "Linchang Zhao, uno dei ricercatori che ha condotto lo studio, ha detto a TechXplore. "Gli obiettivi principali del nostro studio erano risolvere il problema dello sbilanciamento delle classi di dati e ottenere i migliori risultati di classificazione possibili su tali set di dati".
Zhao e i suoi colleghi hanno sviluppato una rete neurale siamese parallela completamente connessa (SPFCNN) e l'hanno applicata a problemi con distribuzioni di dati sbilanciate in classi. Per trasformare il loro SPFCNN insensibile ai costi in un approccio sensibile ai costi, hanno usato una tecnica chiamata "apprendimento sensibile ai costi".
Primo, i ricercatori hanno diviso il gruppo di maggioranza in un set di dati basato sulle caratteristiche trasformate del prodotto interno. Ciò ha assicurato che la dimensione di ciascun sottogruppo in un gruppo di maggioranza fosse vicina a quella del gruppo di minoranza. Inoltre, hanno strutturato alcuni sottogruppi utilizzando il gruppo di minoranza rispetto a ciascuna partizione ottenuta.
"Prossimo, abbiamo applicato n SPFCNN-miner a tutti i sottogruppi, ogni punto campione X J può essere espresso dalle sue misure corrispondenti (d j1 , …, D jn ), ogni sottoclassificatore può essere trasformato in una misura della funzione di perdita di contrasto adattando l'SPFCNN, " Zhao ha spiegato. "Finalmente, n I minatori SPFCNN sono stati integrati come classificatore finale in base ai valori della funzione contrastiva."
L'approccio ideato da Zhao e dai suoi colleghi presenta numerosi vantaggi che lo distinguono dagli altri classificatori. Primo, la loro funzione Meta-Learner (MLF) può essere utilizzata per partizionare il gruppo di maggioranza in un set di dati basato sulle caratteristiche trasformate del prodotto interno, che risulta nei dati trasformati contenenti informazioni relative alle distanze e agli angoli tra gli elementi nei gruppi di minoranza e maggioranza.
"Gli angoli tra il gruppo di maggioranza e il gruppo di minoranza possono essere visti come l'espressione di posizioni correlate e quindi rappresentano la direzione correlata del gruppo di maggioranza al gruppo di minoranza, " Ha spiegato Zhao.
Un ulteriore vantaggio del nuovo classificatore SPFCNN-Miner è che, come altre reti siamesi, può estrarre efficacemente le funzionalità di più alto livello da una piccola quantità di campioni per l'apprendimento in pochi colpi. Inoltre, le reti siamesi parallele sono progettate per apprendere in modo adattivo caratteristiche semplici o complesse da diverse dimensioni di attributi di dati.
Zhao e i suoi colleghi hanno valutato il loro approccio in una serie di test computazionali, utilizzando entrambe le versioni del classificatore SPFCNN non sensibili ai costi e sensibili ai costi. Hanno scoperto che l'approccio sensibile ai costi ha superato tutti i classificatori con cui lo hanno confrontato.
"I risultati sperimentali mostrano che il nostro SPFCNN è un approccio competitivo ed è in grado di migliorare le prestazioni di classificazione in modo più significativo rispetto agli approcci di riferimento, " ha detto Zhao. "Abbiamo scoperto che le prestazioni del nostro modello non sono migliorate con l'aumento della dimensione del campione, ma è stato fortemente influenzato dal tasso di squilibrio. Le prestazioni ottenute incorporando l'apprendimento sensibile ai costi nel nostro modello sono più stabili".
Lo studio condotto da Zhao e dai suoi colleghi introduce un nuovo metodo che potrebbe essere utilizzato dai ricercatori per migliorare le prestazioni dei classificatori quando i dati sono limitati o sbilanciati. Inoltre, i loro risultati suggeriscono che bilanciare il numero di campioni positivi e negativi può essere più efficace rispetto alla generazione di un numero maggiore di campioni artificiali. Ad esempio, il loro approccio può integrare diversi costi di classificazione errata mentre completa un'attività di classificazione, il che lo rende più robusto rispetto ad altre tecniche utilizzate per affrontare problemi sbilanciati problemi relativi ai dati.
"Nel futuro, prevediamo di utilizzare tecniche come matrici random walk, condivisione del peso circolante e codifica Huffman per comprimere il nostro modello, e la tecnologia debolmente connessa o il metodo di potatura-quantizzazione in parallelo sarà utilizzata per alleggerire il modello SPFCNN proposto, " Ha detto Zhao.
© 2019 Scienza X Rete