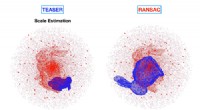
Risultati di pura strategia di difesa sotto attacco ottimale. Credito:Ou &Samavi.
Gli attacchi di avvelenamento sono tra le maggiori minacce alla sicurezza per i modelli di machine learning (ML). In questo tipo di attacco, un avversario cerca di controllare una frazione dei dati utilizzati per addestrare le reti neurali e inietta punti dati dannosi per ostacolare le prestazioni di un modello.
Sebbene i ricercatori abbiano cercato di sviluppare tecniche in grado di rilevare o contrastare questi attacchi, l'efficacia di queste tecniche spesso dipende da quando e come vengono applicate. Inoltre, a volte l'applicazione di tecniche di filtraggio per schermare i modelli ML contro gli attacchi di avvelenamento può ridurne l'accuratezza, impedendo loro di analizzare dati autentici e corrotti.
In un recente studio, i ricercatori della McMaster University in Canada hanno utilizzato con successo la teoria dei giochi per modellare scenari di attacco di avvelenamento. Le loro scoperte, delineato in un documento pre-pubblicato su arXiv, dimostra l'inesistenza di una strategia pura equilibrio di Nash, il che implica che ogni giocatore scelga ripetutamente la stessa strategia nel "gioco" dell'attaccante e del difensore.
Lo studio dei comportamenti sia degli aggressori che dei difensori quando si verificano attacchi di avvelenamento potrebbe aiutare a sviluppare algoritmi di machine learning che sono più protetti contro di loro e tuttavia mantengono la loro precisione. Nel loro studio, i ricercatori hanno cercato di modellare gli attacchi di avvelenamento nel contesto della teoria dei giochi, una branca della matematica che si occupa di una migliore comprensione delle strategie utilizzate in situazioni competitive (ad esempio i giochi), dove un risultato dipende molto dalle scelte di coloro che sono coinvolti (cioè i partecipanti).
"L'obiettivo di questo articolo è trovare l'equilibrio di Nash (NE) del modello di gioco di attacco e difesa da avvelenamento, "Yifan Ou e Reza Samavi, i due ricercatori che hanno condotto lo studio, spiegare nel loro documento. "Identificare la strategia NE ci permetterà di trovare la forza del filtro ottimale dell'algoritmo di difesa, così come l'impatto risultante sul modello ML quando sia l'attaccante che il difensore utilizzano strategie ottimali".
Nella teoria dei giochi, NE è uno stato stabile di un sistema che implica interazioni competitive tra diversi partecipanti (ad esempio un gioco). Quando si verifica NE, nessun partecipante può guadagnare nulla da un cambio di strategia unilaterale se la strategia dell'altro giocatore/giocatori rimane invariata.
Nel loro studio, Ou e Samavi hanno cercato di trovare il NE nel contesto di attacchi di avvelenamento e strategie di difesa. Primo, hanno usato la teoria dei giochi per modellare le dinamiche degli attacchi di avvelenamento e hanno dimostrato che un NE puro non esiste in un tale modello. Successivamente, hanno proposto una strategia mista NE per questo particolare modello di gioco e ne hanno mostrato l'efficacia in un contesto sperimentale.
"Abbiamo usato la teoria dei giochi per modellare le strategie dell'attaccante e del difensore negli scenari di attacco di avvelenamento, " hanno scritto i ricercatori nel loro articolo. "Abbiamo dimostrato l'inesistenza della pura strategia NE, proposto un'estensione mista del nostro modello di gioco e un algoritmo per approssimare la strategia NE per il difensore, poi dimostrato l'efficacia della strategia di difesa mista generata dall'algoritmo."
Nel futuro, i ricercatori vorrebbero studiare un approccio più generale per affrontare gli attacchi di avvelenamento, che comporta il rilevamento e il rifiuto di campioni utilizzando algoritmi di auditing. Questo approccio alternativo potrebbe essere particolarmente efficace per aggiornare e migliorare un modello addestrato in situazioni in cui si cerca il feedback degli utenti online.
© 2019 Science X Network