
Per anni, i ricercatori del MIT e della Brown University hanno sviluppato un sistema interattivo che consente agli utenti di trascinare e rilasciare e manipolare i dati su qualsiasi touchscreen, inclusi smartphone e lavagne interattive. Ora, hanno incluso uno strumento che genera istantaneamente e automaticamente modelli di apprendimento automatico per eseguire attività di previsione su quei dati. Credito:Melanie Gonick
Nel Uomo di ferro film, Tony Stark usa un computer olografico per proiettare dati 3D nel nulla, manipolarli con le sue mani, e trova soluzioni ai suoi problemi da supereroe. Nella stessa vena, ricercatori del MIT e della Brown University hanno ora sviluppato un sistema per l'analisi interattiva dei dati che funziona su touchscreen e consente a tutti, non solo ai geni, miliardario, filantropi playboy:affrontano problemi del mondo reale.
Per anni, i ricercatori hanno sviluppato un sistema interattivo di scienza dei dati chiamato Northstar, che funziona nel cloud ma ha un'interfaccia che supporta qualsiasi dispositivo touchscreen, inclusi smartphone e grandi lavagne interattive. Gli utenti alimentano i set di dati di sistema, e manipolare, combinare, ed estrai funzionalità su un'interfaccia intuitiva, usando le dita o una penna digitale, per scoprire tendenze e modelli.
In un documento presentato alla conferenza ACM SIGMOD, i ricercatori descrivono in dettaglio un nuovo componente di Northstar, chiamato VDS per "scienziato dei dati virtuali, " che genera istantaneamente modelli di apprendimento automatico per eseguire attività di previsione sui propri set di dati. Medici, ad esempio, può utilizzare il sistema per aiutare a prevedere quali pazienti hanno maggiori probabilità di avere determinate malattie, mentre gli imprenditori potrebbero voler prevedere le vendite. Se si utilizza una lavagna interattiva, tutti possono anche collaborare in tempo reale.
L'obiettivo è democratizzare la scienza dei dati semplificando l'esecuzione di analisi complesse, rapido e preciso.
"Anche il proprietario di una caffetteria che non conosce la scienza dei dati dovrebbe essere in grado di prevedere le proprie vendite nelle prossime settimane per capire quanto caffè comprare, " dice Tim Kraska, co-autore e capo del progetto Northstar di lunga data, professore associato di ingegneria elettrica e informatica presso il Computer Science and Artificial Intelligence Laboratory (CSAIL) del MIT e co-direttore fondatore del nuovo Data System and AI Lab (DSAIL). "Nelle aziende che hanno data scientist, c'è un sacco di avanti e indietro tra scienziati di dati e non esperti, quindi possiamo anche portarli in una stanza per fare analisi insieme."
VDS si basa su una tecnica sempre più popolare nell'intelligenza artificiale chiamata apprendimento automatico automatico (AutoML), che consente alle persone con un know-how limitato di scienza dei dati di addestrare modelli di intelligenza artificiale per fare previsioni basate sui loro set di dati. Attualmente, lo strumento guida la competizione DARPA D3M Automatic Machine Learning, che ogni sei mesi decide lo strumento AutoML più performante.
Ad unirsi a Kraska sulla carta sono:il primo autore Zeyuan Shang, uno studente laureato, ed Emanuel Zgraggen, un postdoc e principale collaboratore di Northstar, entrambi EECS, CSAIL, e DSAIL; Benedetto Buratti, Yeounoh Chung, Philipp Eichmann, ed Eli Upfal, tutto marrone; e Carsten Binnig che si è recentemente trasferito da Brown all'Università tecnica di Darmstadt in Germania.

Credito:Melanie Gonick
Una "tela illimitata" per l'analisi
Il nuovo lavoro si basa su anni di collaborazione su Northstar tra i ricercatori del MIT e Brown. In quattro anni, i ricercatori hanno pubblicato numerosi articoli che descrivono in dettaglio i componenti di Northstar, compresa l'interfaccia interattiva, operazioni su più piattaforme, accelerare i risultati, e studi sul comportamento degli utenti.
Northstar inizia come uno spazio vuoto, interfaccia bianca. Gli utenti caricano set di dati nel sistema, che appaiono in una casella "dataset" a sinistra. Eventuali etichette dati popoleranno automaticamente una casella "attributi" separata di seguito. C'è anche una casella "operatori" che contiene vari algoritmi, così come il nuovo strumento AutoML. Tutti i dati vengono archiviati e analizzati nel cloud.
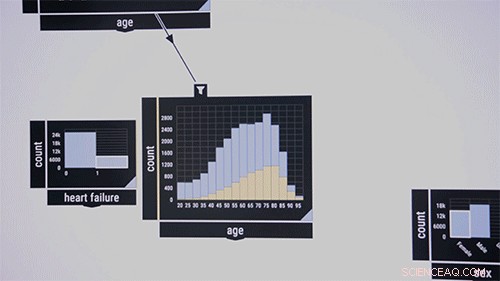
Ai ricercatori piace dimostrare il sistema su un set di dati pubblico che contiene informazioni sui pazienti delle unità di terapia intensiva. Prendi in considerazione i ricercatori medici che desiderano esaminare le concomitanze di determinate malattie in determinati gruppi di età. Trascinano e rilasciano al centro dell'interfaccia un algoritmo di controllo del modello, che inizialmente appare come una casella vuota. Come ingresso, si spostano nella scatola delle caratteristiche della malattia etichettate, dire, "sangue, " "infettivo, " e "metabolico". Le percentuali di tali malattie nel set di dati vengono visualizzate nella casella. Quindi, trascinano la funzione "età" nell'interfaccia, che mostra un grafico a barre della distribuzione per età del paziente. Tracciare una linea tra i due riquadri li collega tra loro. Circolando le fasce d'età, l'algoritmo calcola immediatamente la co-occorrenza delle tre malattie nella fascia di età.
"È come un grande, tela illimitata dove puoi stendere come vuoi tutto, "dice Zgraggen, chi è l'inventore chiave dell'interfaccia interattiva di Northstar. "Quindi, puoi collegare le cose insieme per creare domande più complesse sui tuoi dati."
Approssimazione di AutoML
Con VDS, gli utenti possono ora anche eseguire analisi predittive su quei dati ottenendo modelli personalizzati per le loro attività, come la previsione dei dati, classificazione delle immagini, o analizzando strutture grafiche complesse.
Utilizzando l'esempio precedente, affermano che i ricercatori medici vogliono prevedere quali pazienti potrebbero avere malattie del sangue in base a tutte le caratteristiche del set di dati. Trascinano e rilasciano "AutoML" dall'elenco degli algoritmi. Prima produrrà una scatola vuota, ma con una scheda "target", sotto il quale avrebbero lasciato cadere la funzione "sangue". Il sistema troverà automaticamente le pipeline di machine learning più performanti, presentati come schede con percentuali di accuratezza costantemente aggiornate. Gli utenti possono interrompere il processo in qualsiasi momento, affinare la ricerca, ed esaminare i tassi di errore di ciascun modello, struttura, calcoli, e altre cose.
Credito:Melanie Gonick
Secondo i ricercatori, VDS è lo strumento AutoML interattivo più veloce fino ad oggi, Grazie, in parte, al loro "motore di stima" personalizzato. Il motore si trova tra l'interfaccia e il cloud storage. Il motore sfrutta la creazione automatica di diversi campioni rappresentativi di un set di dati che possono essere elaborati progressivamente per produrre risultati di alta qualità in pochi secondi.
"Insieme ai miei coautori ho passato due anni a progettare VDS per imitare il modo in cui pensa uno scienziato dei dati, "Shang dice, il che significa che identifica istantaneamente quali modelli e passaggi di pre-elaborazione dovrebbe o non dovrebbe essere eseguito su determinate attività, basato su varie regole codificate. Prima sceglie da un ampio elenco di quelle possibili pipeline di apprendimento automatico ed esegue simulazioni sul set di esempio. Così facendo, ricorda i risultati e affina la sua selezione. Dopo aver fornito risultati approssimativi veloci, il sistema perfeziona i risultati nel back-end. Ma i numeri finali sono di solito molto vicini alla prima approssimazione.
"Per l'utilizzo di un predittore, non vuoi aspettare quattro ore per riavere i tuoi primi risultati. Vuoi già vedere cosa sta succedendo e, se rilevi un errore, puoi correggerlo immediatamente. Normalmente non è possibile in nessun altro sistema, " Dice Kraska. Il precedente studio sugli utenti dei ricercatori, infatti, "dimostra che nel momento in cui ritardi nel fornire risultati agli utenti, iniziano a perdere il coinvolgimento con il sistema."
I ricercatori hanno valutato lo strumento su 300 set di dati del mondo reale. Rispetto ad altri sistemi AutoML all'avanguardia, Le approssimazioni di VDS erano altrettanto accurate, ma sono stati generati in pochi secondi, che è molto più veloce di altri strumenti, che funzionano in pochi minuti o ore.
Prossimo, i ricercatori stanno cercando di aggiungere una funzione che avverta gli utenti di potenziali errori o distorsioni dei dati. Ad esempio, per proteggere la privacy del paziente, sometimes researchers will label medical datasets with patients aged 0 (if they do not know the age) and 200 (if a patient is over 95 years old). But novices may not recognize such errors, which could completely throw off their analytics.
"If you're a new user, you may get results and think they're great, " Kraska says. "But we can warn people that there, infatti, may be some outliers in the dataset that may indicate a problem."
This story is republished courtesy of MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.














