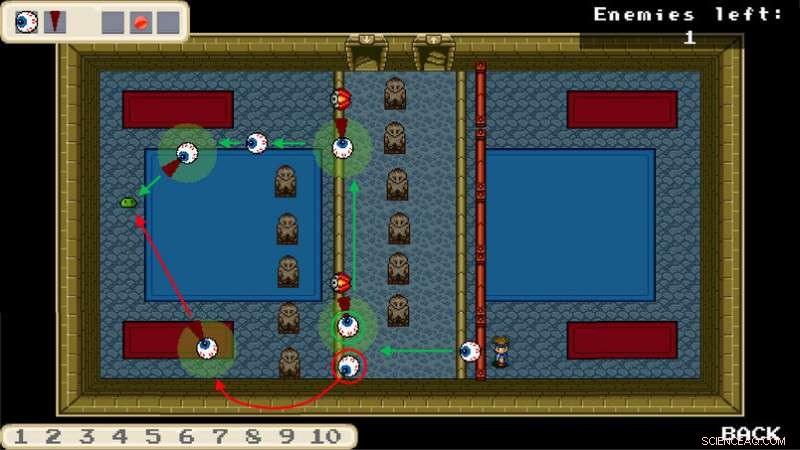
Esempio di un agente di apprendimento in un gioco per computer:il personaggio è controllato da un giocatore umano. Gli occhi sono gli agenti. Il giocatore dovrebbe guidare gli agenti in modo tale che eseguano un compito, per esempio senza imbattersi prima in un ostacolo. La formazione si basa su un processo di machine learning; tutto ciò che il giocatore fa è delineare requisiti approssimativi. Credito:RUB, Institut für Neuroinformatik
I processi alla base dell'intelligenza artificiale oggi sono infatti piuttosto stupidi. I ricercatori di Bochum stanno cercando di renderli più intelligenti.
Cambiamento radicale, rivoluzione, megatrend, forse anche un rischio:l'intelligenza artificiale è penetrata in tutti i segmenti industriali e tiene occupati i media. I ricercatori del RUB Institute for Neural Computation lo studiano da 25 anni. Il loro principio guida è:affinché le macchine siano veramente intelligenti, i nuovi approcci devono prima rendere l'apprendimento automatico più efficiente e flessibile.
"Ci sono due tipi di apprendimento automatico che hanno successo oggi:reti neurali profonde, noto anche come Deep Learning, così come l'apprendimento per rinforzo, " spiega il professor Laurenz Wiskott, Cattedra di Teoria dei Sistemi Neuronali.
Le reti neurali sono in grado di prendere decisioni complesse. Sono spesso utilizzati nelle applicazioni di riconoscimento delle immagini. "Loro possono, Per esempio, dire dalle foto se il soggetto è un uomo o una donna, "dice Wiskott.
L'architettura di tali reti è ispirata a reti di cellule nervose, o neuroni, nel nostro cervello. I neuroni ricevono segnali tramite diversi canali di input e quindi decidono se passare il segnale sotto forma di impulso elettrico ai neuroni successivi o meno.
Anche le reti neurali ricevono diversi segnali in ingresso, ad esempio pixel. In un primo passo, molti neuroni artificiali calcolano un segnale in uscita da diversi segnali in ingresso semplicemente moltiplicando gli ingressi per pesi diversi ma costanti e poi sommandoli. Ognuna di queste operazioni aritmetiche risulta in un valore che – per restare nell'esempio dell'uomo/donna – contribuisce un po' alla decisione per donna o uomo. "Il risultato è leggermente alterato, però, impostando i risultati negativi a zero. Questo, pure, viene copiato dalle cellule nervose ed è essenziale per le prestazioni delle reti neurali, " spiega Laurenz Wiskott.
La stessa cosa accade di nuovo nel livello successivo, fino a quando la rete non prende una decisione nella fase finale. Più fasi ci sono nel processo, più è potente:le reti neurali con più di 100 stadi non sono rare. Le reti neurali spesso risolvono i compiti di discriminazione meglio degli umani.
L'effetto di apprendimento di tali reti si basa sulla scelta dei giusti fattori di ponderazione, che inizialmente vengono scelti a caso. "Per formare una rete del genere, i segnali di ingresso e quale dovrebbe essere la decisione finale sono specificati fin dall'inizio, " elabora Laurenz Wiskott. Così, la rete è in grado di adeguare gradualmente i fattori di ponderazione al fine di prendere finalmente la decisione corretta con la massima probabilità.
Insegnamento rafforzativo, d'altra parte, si ispira alla psicologia. Qui, ogni decisione presa dall'algoritmo – gli esperti lo chiamano l'agente – viene premiata o punita. "Immagina una griglia con l'agente al centro, " illustra Laurenz Wiskott. "Il suo obiettivo è raggiungere la casella in alto a sinistra per il percorso più breve possibile, ma non lo sa". L'unica cosa che l'agente vuole è ottenere il maggior numero di ricompense possibili, altrimenti è ignorante. All'inizio, si sposterà su tutta la linea a caso, e ogni passo che non raggiunge l'obiettivo sarà punito. Solo il passo verso l'obiettivo si traduce in una ricompensa.

Quale percorso dovrebbe prendere il robot? Questa decisione si basa su innumerevoli operazioni aritmetiche. Credito:Roberto Schirdewahn
Per imparare, l'agente assegna un valore a ciascun campo indicando quanti passaggi mancano da quella posizione al suo obiettivo. Inizialmente, questi valori sono casuali. Più esperienza acquisisce l'agente sulla sua tavola, meglio è in grado di adattare questi valori alle condizioni di vita reale. Dopo numerose corse, è in grado di trovare il modo più veloce per raggiungere il suo obiettivo e, di conseguenza, alla ricompensa.
"Il problema con questi processi di apprendimento automatico è che sono piuttosto stupidi, " dice Laurenz Wiskott. "Le tecniche sottostanti risalgono agli anni '80. L'unico motivo del loro attuale successo è che oggi abbiamo più capacità di calcolo e più dati a nostra disposizione." Per questo motivo, è possibile eseguire rapidamente innumerevoli volte i processi di apprendimento virtualmente inefficienti e alimentare le reti neurali con una pletora di immagini e descrizioni di immagini per addestrarle.
"Quello che vogliamo sapere è:come possiamo evitare tutto questo tempo, formazione senza senso? E soprattutto:come possiamo rendere l'apprendimento automatico più flessibile?" come dice succintamente Wiskott. L'intelligenza artificiale può essere superiore agli umani esattamente nell'unico compito per cui è stata addestrata, ma non può generalizzare o trasferire le sue conoscenze a compiti correlati.
Ecco perché i ricercatori dell'Institute for Neural Computation si stanno concentrando su nuove strategie che aiutino le macchine a scoprire le strutture in modo autonomo. "A tal fine, applichiamo il principio dell'apprendimento non supervisionato, " afferma Laurenz Wiskott. Mentre le reti neurali profonde e l'apprendimento per rinforzo si basano sulla presentazione del risultato desiderato o sul premiare o punire ogni passaggio, i ricercatori lasciano gli algoritmi di apprendimento in gran parte soli con il loro input.
"Un compito potrebbe essere, Per esempio, formare grappoli, " spiega Wiskott. A questo scopo, al computer viene richiesto di raggruppare dati simili. Per quanto riguarda i punti in uno spazio tridimensionale, questo significherebbe raggruppare punti le cui coordinate sono vicine tra loro. Se la distanza tra le coordinate è maggiore, sarebbero stati assegnati a diversi gruppi.
"Tornando all'esempio delle immagini di persone, si potrebbe guardare il risultato dopo il raggruppamento e probabilmente scoprire che il computer ha messo insieme un gruppo con immagini di uomini e un gruppo con immagini di donne, " elabora Laurenz Wiskott. "Un grande vantaggio è che tutto ciò che serve all'inizio sono le foto, piuttosto che una didascalia dell'immagine che contiene la soluzione all'enigma per scopi di formazione, com'era."
Il principio di lentezza
Inoltre, questo metodo offre maggiore flessibilità, perché tale formazione di cluster è applicabile non solo per le immagini di persone, ma anche per quelli delle auto, impianti, case o altri oggetti.
Un altro approccio perseguito da Wiskott è il principio di lentezza. Qui, non sono le foto che costituiscono il segnale in ingresso, ma immagini in movimento:se da un video vengono estratte tutte le caratteristiche che cambiano molto lentamente, emergono strutture che aiutano a costruire una rappresentazione astratta dell'ambiente. "Qui, pure, il punto è prestrutturare i dati di input, " sottolinea Laurenz Wiskott. Alla fine, i ricercatori combinano tali approcci in modo modulare con i metodi di apprendimento supervisionato, al fine di creare applicazioni più flessibili ma comunque molto accurate.
"Una maggiore flessibilità si traduce naturalmente in una perdita di prestazioni, " ammette il ricercatore. Ma alla lunga, la flessibilità è indispensabile se vogliamo sviluppare robot in grado di gestire nuove situazioni."














