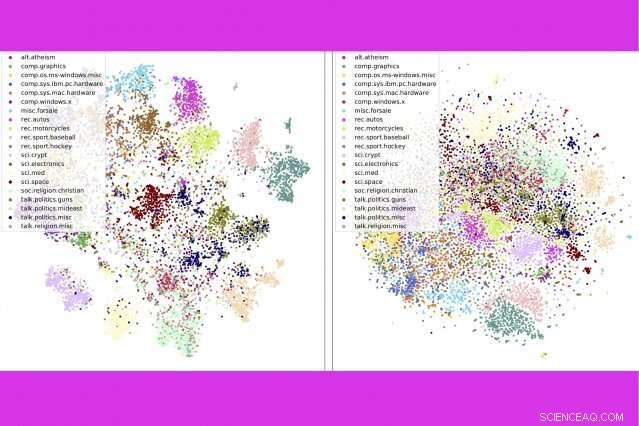
In un nuovo studio, i ricercatori del MIT e dell'IBM combinano tre popolari strumenti di analisi del testo:modellazione di argomenti, incorporamenti di parole, e trasporto ottimale — per confrontare migliaia di documenti al secondo. Qui, mostrano che il loro metodo (a sinistra) raggruppa i post dei newsgroup per categoria in modo più stretto rispetto a un metodo concorrente. Credito:Massachusetts Institute of Technology
Con miliardi di libri, nuove storie, e documenti in linea, non c'è mai stato un momento migliore per leggere, se hai tempo per vagliare tutte le opzioni. "C'è un sacco di testo su Internet, "dice Giustino Salomone, un assistente professore al MIT. "Qualsiasi cosa per aiutare a tagliare tutto quel materiale è estremamente utile."
Con il MIT-IBM Watson AI Lab e il suo Geometric Data Processing Group al MIT, Solomon ha recentemente presentato una nuova tecnica per tagliare enormi quantità di testo alla Conferenza sui sistemi di elaborazione delle informazioni neurali (NeurIPS). Il loro metodo combina tre popolari strumenti di analisi del testo:modellazione di argomenti, incorporamenti di parole, e trasporto ottimale, per consegnare meglio, risultati più rapidi rispetto ai metodi concorrenti su un benchmark popolare per la classificazione dei documenti.
Se un algoritmo sa cosa ti è piaciuto in passato, può scansionare milioni di possibilità per qualcosa di simile. Man mano che le tecniche di elaborazione del linguaggio naturale migliorano, quei suggerimenti "potrebbero piacerti anche" stanno diventando più rapidi e più pertinenti.
Nel metodo presentato a NeurIPS, un algoritmo riassume una raccolta di dire, libri, in argomenti basati su parole di uso comune nella raccolta. Quindi divide ogni libro nei suoi 5-15 argomenti più importanti, con una stima di quanto ogni argomento contribuisce complessivamente al libro.
Per confrontare i libri, i ricercatori utilizzano altri due strumenti:word embedding, una tecnica che trasforma le parole in elenchi di numeri per riflettere la loro somiglianza nell'uso popolare, e trasporto ottimale, un framework per calcolare il modo più efficiente di spostare oggetti, o punti dati, tra più destinazioni.
Gli incorporamenti di parole consentono di sfruttare due volte il trasporto ottimale:prima per confrontare gli argomenti all'interno della raccolta nel suo insieme, poi, all'interno di qualsiasi coppia di libri, per misurare quanto strettamente i temi comuni si sovrappongono.
La tecnica funziona particolarmente bene durante la scansione di grandi raccolte di libri e documenti lunghi. Nello studio, i ricercatori offrono l'esempio di "The Great War Syndicate, di Frank Stockton, " un romanzo americano del XIX secolo che ha anticipato l'avvento delle armi nucleari. Se stai cercando un libro simile, un modello tematico aiuterebbe a identificare i temi dominanti condivisi con altri libri, in questo caso, nautico, elementare, e marziale.
Ma un modello tematico da solo non identificherebbe la conferenza di Thomas Huxley del 1863, "La condizione passata della natura organica, " come una buona partita. Lo scrittore era un campione della teoria dell'evoluzione di Charles Darwin, e la sua lezione, condito con menzioni di fossili e sedimentazione, riflette idee emergenti sulla geologia. Quando i temi della conferenza di Huxley vengono abbinati al romanzo di Stockton tramite un trasporto ottimale, emergono alcuni motivi trasversali:la geografia di Huxley, flora Fauna, e i temi della conoscenza si avvicinano strettamente alla nautica di Stockton, elementare, e temi marziali, rispettivamente.
Libri di modellazione per i loro argomenti rappresentativi, piuttosto che singole parole, rende possibili confronti di alto livello. "Se chiedi a qualcuno di confrontare due libri, scompongono ciascuno in concetti di facile comprensione, e poi confrontare i concetti, ", afferma l'autore principale dello studio Mikhail Yurochkin, un ricercatore presso IBM.
Il risultato è più veloce, confronti più accurati, lo studio mostra. I ricercatori hanno confrontato 1, 720 paia di libri nel set di dati del progetto Gutenberg in un secondo, più di 800 volte più veloce del metodo migliore.
La tecnica fa anche un lavoro migliore nell'ordinamento accurato dei documenti rispetto ai metodi concorrenti, ad esempio raggruppare i libri nel dataset di Gutenberg per autore, recensioni di prodotti su Amazon per reparto, e le storie sportive della BBC per sport. In una serie di visualizzazioni, gli autori mostrano che il loro metodo raggruppa ordinatamente i documenti per tipo.
Oltre a classificare i documenti in modo rapido e accurato, il metodo offre una finestra sul processo decisionale del modello. Attraverso l'elenco di argomenti che appaiono, gli utenti possono vedere perché il modello consiglia un documento.
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.