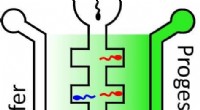
I ricercatori del MIT hanno creato un sistema di generazione di testo automatizzato che individua e sostituisce informazioni specifiche nelle frasi di Wikipedia pertinenti, mantenendo il linguaggio simile a come gli umani scrivono e modificano. Credito:Christine Daniloff, MIT
Un sistema creato dai ricercatori del MIT potrebbe essere utilizzato per aggiornare automaticamente le incongruenze fattuali negli articoli di Wikipedia, riducendo il tempo e gli sforzi spesi dagli editor umani che ora eseguono l'attività manualmente.
Wikipedia comprende milioni di articoli che necessitano costantemente di modifiche per riflettere nuove informazioni. Ciò può comportare espansioni di articoli, importanti riscritture, o più modifiche di routine come l'aggiornamento dei numeri, date, nomi, e luoghi. Attualmente, gli esseri umani di tutto il mondo offrono volontariamente il loro tempo per apportare queste modifiche.
In un documento presentato alla Conferenza AAAI sull'intelligenza artificiale, i ricercatori descrivono un sistema di generazione di testo che individua e sostituisce informazioni specifiche nelle frasi di Wikipedia pertinenti, mantenendo il linguaggio simile a come gli umani scrivono e modificano.
L'idea è che gli umani digitino in un'interfaccia una frase non strutturata con informazioni aggiornate, senza doversi preoccupare dello stile o della grammatica. Il sistema cercherà quindi Wikipedia, individuare la pagina appropriata e la frase obsoleta, e riscriverlo in modo umano. Nel futuro, dicono i ricercatori, esiste la possibilità di creare un sistema completamente automatizzato che identifichi e utilizzi le informazioni più recenti dal Web per produrre frasi riscritte negli articoli di Wikipedia corrispondenti che riflettono le informazioni aggiornate.
"Ci sono così tanti aggiornamenti costantemente necessari per gli articoli di Wikipedia. Sarebbe utile modificare automaticamente parti esatte degli articoli, con poco o nessun intervento umano, "dice Darsh Shah, un dottorato di ricerca studente del Laboratorio di Informatica e Intelligenza Artificiale (CSAIL) e uno degli autori principali. "Invece di centinaia di persone che lavorano per modificare ogni articolo di Wikipedia, allora te ne serviranno solo pochi, perché il modello lo sta aiutando o lo fa automaticamente. Ciò offre notevoli miglioramenti in termini di efficienza."
Esistono molti altri bot che apportano modifiche automatiche a Wikipedia. Tipicamente, coloro che lavorano sulla mitigazione del vandalismo o sull'inserimento di alcune informazioni strettamente definite in modelli predefiniti, Scià dice. Il modello dei ricercatori lui dice, risolve un problema di intelligenza artificiale più difficile:dato un nuovo pezzo di informazione non strutturata, il modello modifica automaticamente la frase in modo umano. "Le altre attività [bot] sono più basate su regole, mentre questo è un compito che richiede di ragionare su parti contraddittorie in due frasi e di generare un pezzo di testo coerente, " lui dice.
Il sistema può essere utilizzato anche per altre applicazioni di generazione di testo, afferma Tal Schuster, co-autore e studente laureato CSAIL. Nella loro carta, i ricercatori lo hanno anche usato per sintetizzare automaticamente le frasi in un popolare set di dati di verifica dei fatti che ha contribuito a ridurre i pregiudizi, senza raccogliere manualmente ulteriori dati. "Per di qua, le prestazioni migliorano per i modelli di verifica automatica dei fatti che si addestrano sul set di dati per, dire, rilevamento di notizie false, "dice Schuster.
Shah e Schuster hanno lavorato al documento con la loro consulente accademica Regina Barzilay, il Delta Electronics Professore di Ingegneria Elettrica e Informatica e un docente in CSAIL.
Mascheramento e fusione della neutralità
Dietro il sistema c'è un bel po' di ingegnosità per la generazione di testo nell'identificare informazioni contraddittorie tra, e poi fondersi insieme, due frasi separate. Prende come input una frase "obsoleta" da un articolo di Wikipedia, più una frase "reclamo" separata che contiene le informazioni aggiornate e contrastanti. Il sistema deve eliminare e conservare automaticamente parole specifiche nella frase obsoleta, sulla base delle informazioni contenute nel reclamo, per aggiornare i fatti ma mantenere lo stile e la grammatica. È un compito facile per gli umani, ma una novità nell'apprendimento automatico.
Per esempio, dire che c'è un aggiornamento necessario a questa frase (in grassetto):"Il Fondo A considera 28 delle loro 42 partecipazioni di minoranza in società operativamente attive come di particolare importanza per il gruppo". La frase di richiesta con informazioni aggiornate può leggere:"Il Fondo A considera significative 23 delle 43 partecipazioni di minoranza". Il sistema individuerà il testo Wikipedia pertinente per "Fondo A, " in base al reclamo. Quindi elimina automaticamente i numeri obsoleti (28 e 42) e li sostituisce con i nuovi numeri (23 e 43), mantenendo la frase esattamente la stessa e grammaticalmente corretta. (Nel loro lavoro, i ricercatori hanno eseguito il sistema su un set di dati di frasi specifiche di Wikipedia, non su tutte le pagine di Wikipedia.)
Il sistema è stato addestrato su un popolare set di dati che contiene coppie di frasi, in cui una frase è un'affermazione e l'altra è una frase di Wikipedia pertinente. Ogni coppia è etichettata in uno dei tre modi seguenti:"d'accordo, " significa che le frasi contengono informazioni fattuali corrispondenti; "non sono d'accordo, " nel senso che contengono informazioni contraddittorie; o "neutro, " dove non ci sono abbastanza informazioni per nessuna delle due etichette. Il sistema deve mettere d'accordo tutte le coppie in disaccordo, modificando la frase obsoleta per corrispondere alla domanda. Ciò richiede l'utilizzo di due modelli separati per produrre l'output desiderato.
Il primo modello è un classificatore di verifica dei fatti, preaddestrato per etichettare ogni coppia di frasi come "d'accordo, " "disaccordo, " o "neutro", che si concentra sulle coppie in disaccordo. In esecuzione in combinazione con il classificatore è un modulo personalizzato "maschera di neutralità" che identifica quali parole nella frase obsoleta contraddicono l'affermazione. Il modulo rimuove il numero minimo di parole richieste per "massimizzare neutralità", il che significa che la coppia può essere etichettata come neutrale. Questo è il punto di partenza:anche se le frasi non sono d'accordo, non contengono più informazioni ovviamente contraddittorie. Il modulo crea una "maschera" binaria sulla frase obsoleta, dove uno 0 viene posizionato sopra le parole che molto probabilmente richiedono l'eliminazione, mentre un 1 va sopra i portieri.
Dopo il mascheramento, un nuovo framework a due codificatori-decodificatori viene utilizzato per generare la frase di output finale. Questo modello apprende rappresentazioni compresse dell'affermazione e della frase obsoleta. Lavorando insieme, i due encoder-decodificatori fondono le parole dissimili dal claim, facendoli scorrere nei punti lasciati vacanti dalle parole cancellate (quelle coperte da 0) nella frase obsoleta.
In una prova, il modello ha ottenuto un punteggio più alto di tutti i metodi tradizionali, utilizzando una tecnica chiamata "SARI" che misura quanto bene le macchine eliminano, Inserisci, e mantieni le parole rispetto al modo in cui gli umani modificano le frasi. Hanno usato un set di dati con frasi di Wikipedia modificate manualmente, che il modello non aveva visto prima. Rispetto a diversi metodi tradizionali di generazione del testo, il nuovo modello era più accurato nell'effettuare aggiornamenti sui fatti e il suo output assomigliava più da vicino alla scrittura umana. In un'altra prova, gli umani in crowdsourcing hanno valutato il modello (su una scala da 1 a 5) in base a quanto bene le sue frasi di output contenevano aggiornamenti fattuali e corrispondevano alla grammatica umana. Il modello ha ottenuto punteggi medi di 4 negli aggiornamenti fattuali e 3,85 nella grammatica corrispondente.
Rimuovere i pregiudizi
Lo studio ha anche dimostrato che il sistema può essere utilizzato per aumentare i set di dati per eliminare i pregiudizi quando si addestrano i rilevatori di "notizie false, " una forma di propaganda contenente disinformazione creata per fuorviare i lettori al fine di generare visualizzazioni di siti Web o guidare l'opinione pubblica. Alcuni di questi rilevatori si addestrano su set di dati di coppie di frasi accordo-disaccordo per "imparare" a verificare un'affermazione abbinandola a prove fornite.
In queste coppie, l'affermazione abbinerà determinate informazioni a una frase di "prova" di supporto da Wikipedia (d'accordo) o sarà modificata dagli esseri umani per includere informazioni contraddittorie alla frase di prova (non sono d'accordo). I modelli sono addestrati a contrassegnare affermazioni con prove confutabili come "false, " che può essere utilizzato per aiutare a identificare le notizie false.
Sfortunatamente, tali set di dati attualmente presentano distorsioni non intenzionali, Shah dice:"Durante l'allenamento, i modelli usano un linguaggio delle affermazioni scritte umane come frasi "da regalare" per contrassegnarle come false, senza fare molto affidamento sulla frase di prova corrispondente. Ciò riduce l'accuratezza del modello durante la valutazione di esempi del mondo reale, in quanto non esegue il controllo dei fatti."
I ricercatori hanno utilizzato le stesse tecniche di cancellazione e fusione del loro progetto Wikipedia per bilanciare le coppie disaccordo-accordo nel set di dati e aiutare a mitigare il pregiudizio. Per alcune coppie "in disaccordo", hanno usato le false informazioni della frase modificata per rigenerare una falsa "prova" a sostegno della frase. Alcune delle frasi da regalare esistono quindi sia nelle frasi "d'accordo" che "non d'accordo", che costringe i modelli ad analizzare più caratteristiche. Usando il loro set di dati aumentato, i ricercatori hanno ridotto del 13% il tasso di errore di un popolare rilevatore di notizie false.
"Se hai una distorsione nel tuo set di dati, e stai ingannando il tuo modello facendogli solo guardare una frase in una coppia in disaccordo per fare previsioni, il tuo modello non sopravviverà al mondo reale, " Shah dice. "Facciamo in modo che i modelli guardino entrambe le frasi in tutte le coppie d'accordo-disaccordo".
Questa storia è stata ripubblicata per gentile concessione di MIT News (web.mit.edu/newsoffice/), un popolare sito che copre notizie sulla ricerca del MIT, innovazione e didattica.