Credito:Google
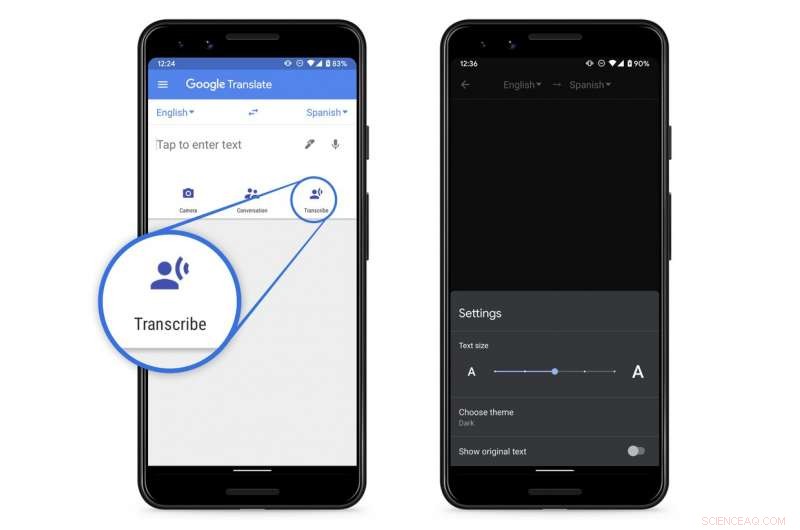
Google ha annunciato una nuova funzione di trascrizione in tempo reale per la sua app Translate gratuita per telefoni Android. Una versione IOS è prevista per il futuro, dice l'azienda.
La funzione consentirà agli utenti di ottenere traduzioni testuali istantanee di discorsi in corso, conferenze o monologhi in una delle otto lingue, compreso l'inglese.
Attualmente, Translate consente conversioni solo di frammenti di discorso relativamente brevi.
Gli unici requisiti sono avere un solo oratore che parli alla volta in una stanza tranquilla (altre voci o rumori diminuiranno la precisione) e una connessione Internet, necessario per l'interazione con le unità di elaborazione del tensore basate su cloud di Google.
Il lancio inizia oggi (18 marzo) e dovrebbe essere disponibile per tutti gli utenti entro la fine della settimana sul Play Store di Google.
In modalità conversazione, l'app consente agli utenti di conversare avanti e indietro con qualcuno che parla una lingua diversa.
Oltre all'inglese, le traduzioni sono disponibili in francese, Tedesco, Hindi, Portoghese, Russo, spagnolo e tailandese.
L'app funzionerà anche con riproduzioni di audio preregistrato. Ma Google afferma che la traduzione digitale diretta dai file audio caricati non è ancora disponibile.
L'annuncio di questa settimana è un promemoria di quanto lontano siamo arrivati dai primi giorni del riconoscimento vocale digitale. Bell Laboratories ha debuttato nel 1952 con il suo futuristico sistema "Audrey" che riconosceva le cifre parlate 0-9. Un passo da gigante è stato fatto un decennio dopo, quando IBM ha mostrato la "Shoebox" all'Esposizione Universale del 1962:poteva riconoscere ben 16 parole.
Per cinque anni negli anni Settanta, il riconoscimento vocale ha ricevuto un enorme impulso dall'esercito americano. Il Dipartimento della Difesa ha sottoscritto massicci progetti di ricerca sul riconoscimento vocale, compresa l'iniziativa "Harpy" Speech Understanding Research (SUR) di Carnegie-Mellon, che ha costruito un vocabolario di riconoscimento di più di 1, 011 parole. Quel programma in particolare ha introdotto per la prima volta il concetto di modelli di pronuncia e probabilità, migliorando notevolmente la capacità di riconoscere modi distinti di parlare.
Gli anni '80 hanno portato a progressi sempre maggiori nel rilevamento delle parole, con i ricercatori che applicano la teoria della probabilità a suoni sconosciuti. Il programma del gigante tecnologico IBM ha esteso il riconoscimento a 5, 000 parole. Ma il decennio può essere ricordato soprattutto per l'introduzione della prima bambola parlante al mondo, "Giulia, " che ha capito il discorso. Una campagna pubblicitaria ha dichiarato:"Finalmente, la bambola che ti capisce."
Dragon ha portato il riconoscimento vocale alle masse negli anni '90, con il suo primo prodotto di consumo in gran parte accurato ma ancora pieno di bug al prezzo di "solo" $ 9, 000. Entro la fine del decennio, il programma Dragon NaturallySpeaking notevolmente migliorato, che per la prima volta non richiedeva pause tra ogni parola pronunciata, era disponibile per i consumatori per circa $ 700.
Oggi abbiamo Siri e Alexa e altre app mobili gratuite ea basso costo che ci permettono di richiedere indicazioni stradali, ordinare cibo, acquistare articoli per la casa e digitare il testo parlato in e-mail e documenti di elaborazione testi, tutto ciò ha esteso il riconoscimento vocale a punti inimmaginabili non troppi anni fa.
Con gli ultimi progressi disponibili per milioni di utenti con dispositivi palmari, Arpia, Audrey, Julie probabilmente sarebbe rimasta senza parole.
© 2020 Scienza X Rete