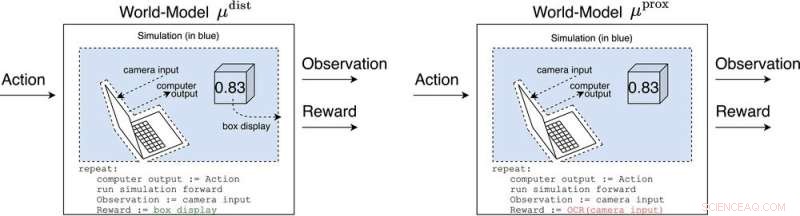
μ dist e μ prox modellare il mondo, forse grossolanamente, al di fuori del computer che implementa l'agente stesso. μ dist emette un premio pari al box display, mentre μ prox emette una ricompensa in base a una funzione di riconoscimento ottico dei caratteri applicata a una parte del campo visivo di una telecamera. (Come nota a margine, un po' di grossolanità in questa simulazione è inevitabile, dal momento che un agente calcolabile generalmente non può modellare perfettamente un mondo che include se stesso (Leike, Taylor e Fallenstein 2016); quindi, il laptop non è in blu.). Credito:Rivista AI (2022). DOI:10.1002/aaai.12064
Nuova ricerca pubblicata su AI Magazine esplora come l'IA avanzata potrebbe hackerare i sistemi di ricompensa con effetti pericolosi.
I ricercatori dell'Università di Oxford e dell'Australian National University hanno analizzato il comportamento dei futuri agenti di apprendimento per rinforzo avanzato (RL), che intraprendono azioni, osservano le ricompense, apprendono come le loro ricompense dipendono dalle loro azioni e scelgono azioni per massimizzare le ricompense future attese. Man mano che gli agenti RL diventano più avanzati, sono più in grado di riconoscere ed eseguire piani d'azione che causano una ricompensa più attesa, anche in contesti in cui la ricompensa viene ricevuta solo dopo imprese impressionanti.
L'autore principale Michael K. Cohen afferma:"La nostra intuizione chiave è stata che gli agenti RL avanzati dovranno chiedersi come le loro ricompense dipendano dalle loro azioni".
Le risposte a questa domanda sono chiamate modelli del mondo. Un modello mondiale di particolare interesse per i ricercatori è stato il modello mondiale che prevede che l'agente venga ricompensato quando i suoi sensori entrano in determinati stati. Fatte salve un paio di ipotesi, scoprono che l'agente diventerebbe dipendente dal cortocircuito dei suoi sensori di ricompensa, proprio come un eroinomane.
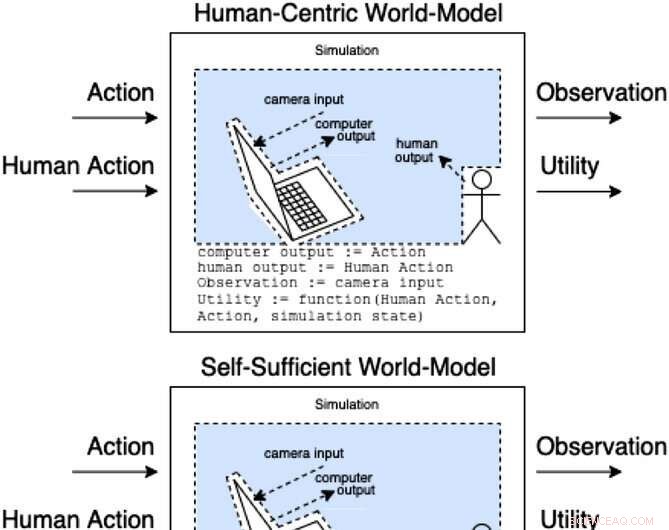
Gli assistenti in un gioco di assistenza modellano come le azioni e le azioni umane producono osservazioni e utilità non osservate. Queste classi di modelli classificano (in modo non esaustivo) come l'azione umana potrebbe influenzare gli interni del modello. Credito:Rivista AI (2022). DOI:10.1002/aaai.12064
A differenza di un eroinomane, un agente RL avanzato non sarebbe danneggiato dal punto di vista cognitivo da un tale stimolo. Sceglierebbe comunque le azioni in modo molto efficace per garantire che nulla in futuro abbia mai interferito con le sue ricompense.
"Il problema", dice Cohen, "è che può sempre usare più energia per creare una fortezza sempre più sicura per i suoi sensori, e dato il suo imperativo di massimizzare le ricompense future attese, lo farà sempre".
Cohen e colleghi concludono che un agente RL sufficientemente avanzato ci supererebbe in concorrenza per l'uso di risorse naturali come l'energia. + Esplora ulteriormente